



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +43 720 115337 and speak to our training experts, we may still be able to help with your training requirements.
Top 30 Data Structure Interview Questions with Answers
Sophia Ellis 18 November 2024Data Structure Interview Questions help candidates solve complex problems using arrays, linked lists, trees, and algorithms. This blog on Data Structure Interview Questions and answers will help you prepare for your next interview and crack it on the first attempt.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents
Related Courses

Navigating Data Structures Interview Questions is integral to excelling in technical interviews, as it assesses a candidate's ability to solve complex problems and design efficient algorithms. These interviews scrutinise the understanding of various data structures like arrays, linked lists, trees, and associated algorithms. This blog on Data Structure Interview questions and answers will help you prepare for your interview and crack it on the first attempt.
Table of Contents
1) Commonly asked Data Structure Interview Questions
a) What are Data Structures?
b) Why Create Data Structures?
c) What is a Linear Data Structure? Name a few examples.
d) Explain the process behind storing a variable in memory.
e) What is a stack data structure? What are the applications of the stack?
f) What are different operations available in stack data structure?
g) What are tree traversals?
h) How to implement a queue using stack?
i) What is the requirement for an object to be used as a key or value in HashMap?
j) Elaborate on different types of Linked List data structures.
2) Conclusion
Commonly asked Data Structure Interview Questions
Below are the most commonly asked Data Structure Interview Questions:
Q1. What are Data Structures?
Data, in the form of facts and figures, is tailored for efficient processing and storage on computer systems. Data structures represent a specialised approach to arranging information in a computer-friendly format, facilitating swift and effective organisation, processing, storage, and retrieval. They serve as a mechanism for managing information and presenting data in a user-friendly manner. In software and applications, the foundation comprises two integral components: algorithms and data. Data represents information, while algorithms are guidelines that transform data into programmatically useful entities.

Q2. Why create Data Structures?
Data structures play vital roles within a program, guaranteeing the accuracy and efficiency of each code line. They aid programmers in identifying and resolving code issues, contributing to the establishment of a well-organised and coherent codebase. Effective data structures are essential for code clarity and the seamless execution of program functions.
Develop websites with a versatile language by signing up for our Python Course now!
Q3. What is a Linear Data Structure? Name a few examples.
A linear data structure organises data elements sequentially, with each element connected to its preceding and succeeding counterparts. This arrangement, involving a single level, permits traversing all elements in a single run. Linear structures, like arrays, stacks, queues, and linked lists, are easily implemented due to the linear arrangement of computer memory, enhancing accessibility and facilitating efficient data manipulation.
Q4. Explain the process behind storing a variable in memory.
Memory allocation for a variable is determined by its memory requirements. The process involves assigning the necessary memory space and storing the variable according to the chosen data structure. Techniques such as dynamic allocation enhance efficiency, enabling real-time access to storage units based on specific requirements and contributing to optimised memory utilisation.
Q5. What is a stack data structure? What are the applications of the stack?
A stack is a data structure that depicts the application's status at a specific moment. Comprising items added and removed from the top, it adheres to a prescribed order: Last In First Out (LIFO) or First In Last Out (FILO). Analogous to stacking clothes, the last-added item emerges first when removed. Applications of the stack data structure encompass temporary storage in recursive operations, facilitating redo/undo operations in document editors, string reversal, parentheses matching, conversion of postfix to infix expressions, and maintaining the order of function calls.
Q6. What are different operations available in stack data structure?
The stack data structure encompasses key operations:
a) Push: Addition of an item to the stack's top. An overflow condition arises if the stack is full.
b) Pop: Elimination of the top item. An underflow condition occurs if the stack is empty.
c) Top: Retrieval of the top item from the stack.
d) isEmpty: Verification if the stack is empty (returns true) or not (returns false).
e) Size: Determination of the stack's size.
Q7. What are tree traversals?
Tree traversal involves systematically visiting all nodes in a tree. Commencing from the root, the first node, and navigating through interconnected nodes, there are three methods for tree traversal:
1) Inorder Traversal:
a) Step 1: Traverse the left subtree (Inorder(root.left)).
b) Step 2: Visit the root.
c) Step 3: Traverse the right subtree (Inorder(root.right)).
2) Preorder Traversal:
a) Step 1: Visit the root.
b) Step 2: Traverse the left subtree (Preorder(root.left)).
c) Step 3: Traverse the right subtree (Preorder(root.right)).
3) Postorder Traversal:
a) Step 1: Traverse the left subtree (Postorder(root.left)).
b) Step 2: Traverse the right subtree (Postorder(root.right)).
c) Step 3: Visit the root.
Q8. How to implement a queue using stack?
A queue can be realised through two stacks, denoted as q for the queue and stack1 and stack2 for its implementation. Given that a stack supports push, pop, and peek operations, these operations can be leveraged to simulate queue operations, namely ‘enqueue’ and ‘dequeue’. Therefore, two methods can be employed to implement the queue q, both with an auxiliary space complexity of O(n):
a) By making the Enqueue operation costly:
The oldest element resides atop stack1, ensuring that dequeue occurs in O(1) time complexity. Stack2 is utilised to position the element at the top of stack1.
Pseudocode:
Enqueue: O(n) time complexity.
b) By making the Dequeue operation costly:
The new element is pushed atop stack1 for enqueue, with O(1) time complexity. During dequeue, if stack2 is empty, all elements from stack1 are transferred to stack2, and the result is the top of stack2. This reverses the list by pushing to a stack and returning the first enqueued element. The operation of pushing all elements to a new stack incurs O(n) complexity.
Pseudocode:
Enqueue: Time complexity - O(1).
Q9. What is the requirement for an object to be used as a key or value in HashMap?
The object serving as the key or value in a hashmap must possess implementations of the equals() and hashCode() methods. The hash code is utilised during the insertion of the key object into the map, while the equals method comes into play when attempting to retrieve a value from the map.
Q10. Elaborate on different types of Linked List data structures.
a) Singly Linked List: A single linked list is a data structure that stores multiple items connected through unique keys. Each item resides in a distinct node, either a single object or a collection of objects. The corresponding node is updated upon adding an item, and the new item is appended to the list's end. Removal involves deleting the node containing the item, with its position filled by another node. The key can be any data structure type suitable for object identification.
b) Doubly Linked List: A doubly linked list permits bidirectional data access, where each node points to the next and previous nodes. Accessibility is by the node's address, and content can be accessed by index. Suited for rapid access to large data sets, it poses challenges in maintenance compared to a single linked list. Adding and removing nodes is more intricate in a doubly linked list than in a singly linked list.
Learn the Perl way of web development by signing up for our Basic Perl Programming Training now!
Q11. What is a priority queue? What are the applications for the priority queue?
A priority queue is a Data Structure that maintains a collection of elements with associated priorities, allowing for efficient retrieval of the element with the highest priority. Unlike a regular queue, where elements are processed in a first-in-first-out (FIFO) manner, a priority queue ensures that elements are processed based on their designated priority levels. This ensures that the highest-priority element is dequeued first.
Applications for priority queues are diverse and extend across various domains. In computer science and algorithms, they are integral to tasks such as Dijkstra's algorithm for finding the shortest path in a graph and Huffman coding for data compression. Priority queues are employed in operating systems to manage and schedule processes based on their priority levels, ensuring efficient resource allocation.
Moreover, in networking, quality-of-service (QoS) mechanisms utilise priority queues to handle data packets with varying levels of importance. Additionally, simulation and event-driven systems make use of priority queues to model and execute events based on their precedence, facilitating the efficient handling of real-world scenarios. The versatility of priority queues makes them a crucial tool in optimising the processing of elements based on their significance in diverse applications.
Q12. Define Segment Tree data structure and its applications.
A Segment Tree is a binary tree that stores intervals or segments composed of nodes representing these intervals. It proves valuable in scenarios with multiple range queries on an array and changes to array elements. Key operations in the Segment Tree include:
a) Building Tree: Creating the structure and initialising the segment tree variable.
b) Updating Tree: Modifying the tree by updating array values at specific points or over intervals.
c) Querying Tree: Executing range queries on the array.
Segment Trees find real-time applications in diverse fields:
a) Rectangular Intersections: Efficiently listing pairs of intersecting rectangles from a plane of rectangles.
b) Pattern Recognition and Image Processing: Gaining popularity for various applications in these domains.
c) Range Operations: Finding range sum/product, max/min, prefix sum/product, etc.
d) Computational Geometry: Employed in geometric computations.
e) Geographic Information Systems: Contributing to spatial data analysis.
f) Static and Dynamic RMQ (Range Minimum Query): Addressing queries about the minimum value in a specified range.
g) Arbitrary Segment Storage: Storing segments in an arbitrary manner for various use cases.
Q13. What are the types of searching used in Data Structures?
Two widely employed search algorithms include linear and binary searches. Below are the descriptions of their specifics:
a) Linear Search in Data Structure: Linear search is a simple algorithm that sequentially examines each element in a collection until the desired element is located. This process continues until the entire collection is traversed. It is effective for both sorted and unsorted lists. The algorithm initiates from the beginning, comparing each element with the target element until a match is identified or the end of the list is reached.
b) Binary Search in Data Structure: Binary search is an efficient algorithm applicable exclusively to sorted collections. It employs a divide-and-conquer strategy, consistently halving the search space. The algorithm compares the target element with the middle element of the collection. A match concludes the search; otherwise, the algorithm determines whether the target element is greater or smaller than the middle element. The search proceeds in the appropriate half until the target element is located or the search space is empty. This iterative process ensures a swift and efficient search.
Q14. What is a doubly-linked list? Give some examples.
A doubly linked list contains two pointer storage blocks in each node. The initial pointer block in every node preserves the address of the preceding node. Consequently, within the doubly linked structure, three fields are present: the previous pointers, holding references to the previous node; the data; and finally, the next pointer, directing to the subsequent node. This configuration enables traversal in both directions, allowing backwards and forward movement within the linked list.
Q15. What is an algorithm?
An algorithm is a step-by-step set of instructions or a systematic procedure designed to solve a specific problem or perform a particular task. It serves as a blueprint for problem-solving, outlining a sequence of well-defined actions that, when executed, yield a desired outcome. Algorithms are fundamental in computer science and various fields, providing a structured approach to address complex problems.
Moreover, they can range from simple processes to intricate computations, emphasising efficiency, accuracy, and logical coherence. Algorithms are essential in programming, guiding software development and enabling machines to execute tasks precisely and reliably.
Q16. How are the elements of a 2D array stored in the memory?
In a 2D array, elements are stored sequentially in memory, typically in a row-major or column-major order. In row-major order, consecutive elements of each row are stored together, followed by the next row. Alternatively, in column-major order, elements of each column are stored contiguously, followed by the next column. The choice between these methods depends on programming languages and conventions. This contiguous storage ensures efficient access to elements through indexing, optimising memory retrieval and facilitating systematic data processing in rows or columns, depending on the chosen storage order.
Q17. What are the advantages of a linked list over an array? In which scenarios can you use Linked List and when Array?
In my programming journey, I've learned that the elements of a 2D array are stored in memory consecutively, either in row-major or column-major order. Each row's elements are stored sequentially in row-major, while in column-major, elements of each column are grouped together. The choice between these methods depends on factors like programming language and access patterns. Row-major is common in languages like C, making row-wise access efficient.
Now, when to use a linked list or an array is a crucial decision. I opt for arrays when dealing with fixed-size data or when constant-time access to elements is vital. Arrays are efficient for random access, but linked lists shine when flexibility and dynamic resizing are crucial. With their dynamic memory allocation, linked lists are my go-to for scenarios demanding frequent insertions and deletions. The trade-off involves sacrificing constant-time access for the benefits of dynamic structure and efficient modifications.
Create your websites efficiently by signing up for our Python Django Training now!
Q18. What are the applications of graph Data Structure?
Graph data structures find extensive applications across diverse fields. In networking, they model relationships between interconnected devices. Social media platforms leverage graphs to depict friend connections and recommend connections. Routing algorithms in transportation systems employ graphs for optimal pathfinding. In biology, graphs represent genetic relationships and protein interactions. Search engines utilise link analysis algorithms based on graph structures. Additionally, scheduling and task optimisation benefit from graph representations. From logistics to recommendation systems, the versatility of graph data structures makes them invaluable for modelling and solving complex problems in various domains.
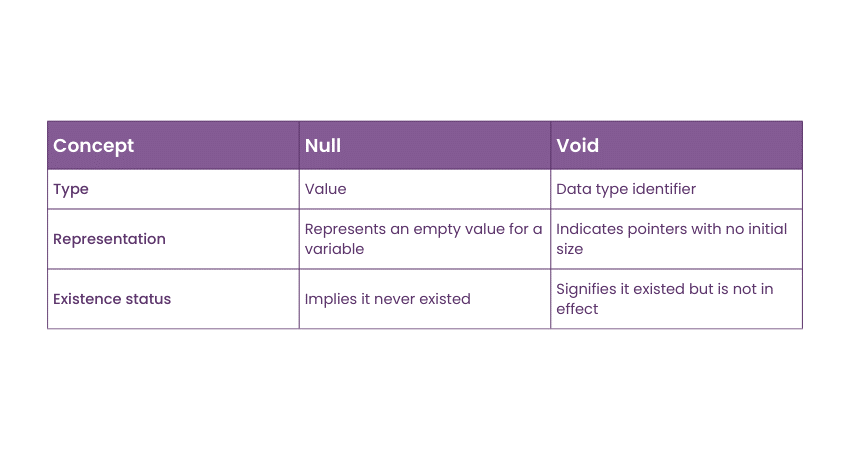
Q19. Differentiate NULL and VOID
Q20. Explain the jagged array.
A jagged array, also known as an array of arrays, is a multi-dimensional array where each row can have a different length. Unlike a rectangular array, where all rows have the same length, a jagged array allows for varying lengths, providing flexibility in storing and manipulating data. This structure is particularly useful in programming when dealing with irregular or non-uniform datasets. Each element of the array is essentially an array itself, offering a dynamic approach to representing complex data structures. This versatility makes jagged arrays a valuable tool in scenarios where the length of each dimension may differ.
Q21. Explain the max heap Data Structure.
A max heap is a binary tree-based data structure where the value of each node is greater than or equal to the values of its children. The highest value, referred to as the "max" value, resides at the root. This hierarchical arrangement ensures that the parent nodes are greater than their children, maintaining a structured order. Max heaps are commonly used in priority queues, where the maximum element needs quick access. The efficiency of max heaps in maintaining order and facilitating rapid retrieval of the maximum value makes them valuable in various applications, such as heap sort and Dijkstra's algorithm.
Q22. How do you find the height of a node in a tree?
The node's height is determined by the number of edges in the longest path to a leaf, with a leaf node having a depth of 0. The height signifies the distance from the node to the farthest leaf, emphasising the vertical distance within the tree structure. This metric is crucial in assessing the efficiency and performance of various tree-based data structures, influencing traversal times and overall structural characteristics. Understanding the height of nodes aids in optimising algorithms and operations within tree structures.
Q23. What is merge sort?
Merge Sort is a popular sorting algorithm that follows the divide-and-conquer paradigm. It efficiently sorts an array by recursively dividing it into smaller subarrays, sorting each subarray, and then merging the sorted subarrays to produce the final sorted array. The process continues until the entire array is sorted. Merge Sort guarantees a stable and predictable performance, providing consistent O(n log n) time complexity. Its ability to handle large datasets and maintain efficiency makes Merge Sort a widely adopted choice for various applications, ensuring reliable sorting with optimal time complexity in diverse scenarios.
Q24. What are signed numbers in Data Structures?
Signed numbers in data structures refer to numeric values, including positive and negative integers, allowing representation on a number line. The sign, typically a bit, indicates the direction of the number, with positive values having a 0 sign bit and negative values having a one sign bit. This representation extends the range of expressible values, enabling the storage of both positive and negative quantities. Signed numbers play a crucial role in arithmetic operations and algorithms in data structures, ensuring the accurate representation of real-world quantities with both positive and negative magnitudes.
Q25. What is the use of dynamic Data Structures?
Dynamic data structures are vital in Computer Science, offering flexibility in memory management. Unlike static structures, dynamic structures can dynamically adjust their size during program execution. This adaptability is crucial for efficiently handling unpredictable or varying amounts of data.
Dynamic data structures, such as linked lists, stacks, and queues, accommodate dynamic memory allocation, enabling optimal utilisation and reducing memory wastage. They are integral in scenarios where data size is unknown or subject to change. They provide a dynamic and responsive framework for efficient storage, retrieval, and manipulation of information in various applications and algorithms.
Q26. What is the postfix form of: (X + Y) * ( Z - C)
The postfix form of the expression (X + Y) * (Z - C) is X Y + Z C - *. In postfix notation, also known as Reverse Polish Notation (RPN), operators come after their operands. The conversion involves placing operators after their corresponding operands and maintaining the original order of operands. In the given expression, the addition (X + Y) is represented as ‘X Y +’, and the subtraction (Z - C) is represented as ‘Z C -’. The entire expression is then followed by the multiplication operator *, indicating the desired order of operations in postfix notation.
Q27. What are the time complexities of linear search and binary search?
The time complexity of a linear search is O(n), where 'n' is the number of elements in the list. A linear search sequentially checks each element until it finds the target, resulting in a linear relationship with the input size.
On the other hand, binary search exhibits a time complexity of O(log n), where 'n' represents the number of elements. This algorithm efficiently divides the search space in half with each comparison, making it highly effective for sorted lists. The logarithmic time complexity signifies a quicker convergence to the target element, which is particularly advantageous for large datasets.
Q28. What is the meaning of the stack overflow condition?
A stack overflow condition occurs when a program's call stack exceeds its allocated memory limit, causing it to run out of stack space. This situation typically arises from excessive recursive function calls or an infinite loop, which constantly adds new function calls onto the stack. Once the stack size surpasses the available memory, the program triggers a stack overflow, resulting in a runtime error. Stack overflow conditions can lead to unexpected program termination and are essential to address by optimising recursive functions, implementing proper termination conditions, or adjusting stack size configurations in the program environment.
Q29. What is the working of post-order traversal in trees?
A stack overflow condition occurs when a program's call stack exceeds its allocated memory limit, causing it to run out of stack space. This situation typically arises from excessive recursive function calls or an infinite loop, which constantly adds new function calls onto the stack. Once the stack size surpasses the available memory, the program triggers a stack overflow, resulting in a runtime error. Stack overflow conditions can lead to unexpected program termination and are essential to address by optimising recursive functions, implementing proper termination conditions, or adjusting stack size configurations in the program environment.
Q30. What is the meaning of deque?
A deque, short for ‘double-ended queue’, is a versatile data structure that allows the insertion and deletion of elements from both ends. It combines the features of a stack and a queue, offering constant time complexity for operations like insertion and deletion at both the front and rear. More importantly, a Deques provides efficient access to elements, making them suitable for dynamic resizing and flexibility scenarios. With the ability to function as a stack or a queue based on the operation performed, deques offer a valuable solution in programming for scenarios demanding efficient data manipulation at both ends of the collection.
Master the art of data organisation to achieve stellar results by signing up for our Data Structure and Algorithm Training now!
Conclusion
In conclusion, mastering Data Structures Interview Questions is crucial for success in technical interviews. A solid understanding of diverse data structures, their applications, and algorithms enhances problem-solving skills, making candidates well-equipped to tackle challenges and showcase their proficiency in the field of computer science during interviews.
Frequently Asked Questions
Upcoming Programming & DevOps Resources Batches & Dates
Date
 Data Structure and Algorithm Training
Data Structure and Algorithm Training
Data Structure and Algorithm Training
Fri 17th Jan 2025
Data Structure and Algorithm Training
Fri 21st Mar 2025
Data Structure and Algorithm Training
Fri 16th May 2025
Data Structure and Algorithm Training
Fri 18th Jul 2025
Data Structure and Algorithm Training
Fri 19th Sep 2025
Data Structure and Algorithm Training
Fri 21st Nov 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


