



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on 01344 203999 and speak to our training experts, we may still be able to help with your training requirements.
Random Forest vs Decision Tree: What's the Difference?
Eliza Taylor 22 November 2024Random forest combines multiple Decision Trees to improve accuracy and reduce overfitting for big datasets, while a Decision Tree is ideal for smaller datasets. This blog explores the differences between Random Forest Vs Decision Tree, covering parameters such as interpretability, training time, overfitting and more. Read on!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents
In the cutting-edge world of Machine Learning (ML), two powerful contenders are vying for the spotlight as the best algorithm: Random forest and Decision Tree. Each of them brings its unique charm. While the Decision Tree stands alone—simple, interpretable, and ideal for smaller datasets—random forest steps in like an ensemble when data complexity increases, combining multiple trees to create a more robust performance.
So, knowing when to use one over the other can make a radical difference in your Data Science journey. This blog explores the key differences between Random Forest Vs Decision Tree, to help you pinpoint the exact choice for your data analysis needs.
Table of Contents
1) What Is Random Forest?
2) What Are Decision Trees?
3) Differences Between Random Forest and Decision Trees
4) When to Use Random Forest Vs Decision Tree
5) Conclusion
What is Random Forest?
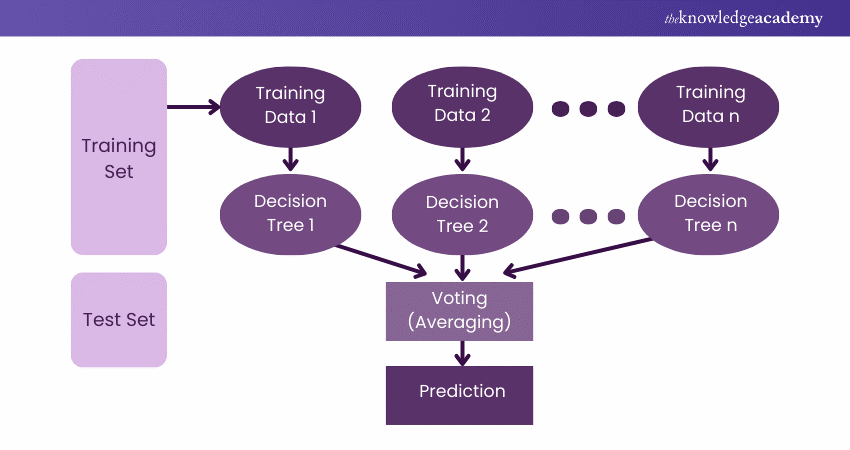
A random forest is a powerful tree-based algorithm in Machine Learning (ML). It works by creating several Decision Trees during training phase where each tree is constructed through a random subset of the dataset to measure a subset of features in each partition. This randomness introduces variability among individual trees, improving overall prediction performance and reducing the risk of overfitting.

What Are Decision Trees?
A Decision Tree is a supervised non-parametric learning algorithm utilised for classification and regression tasks. It has a hierarchical tree structure comprising branches, leaf nodes, a root node, and internal nodes. The Decision Tree commences with a root node (that has no incoming branches) and outgoing branches from the root node feed into internal nodes (also known as decision nodes).
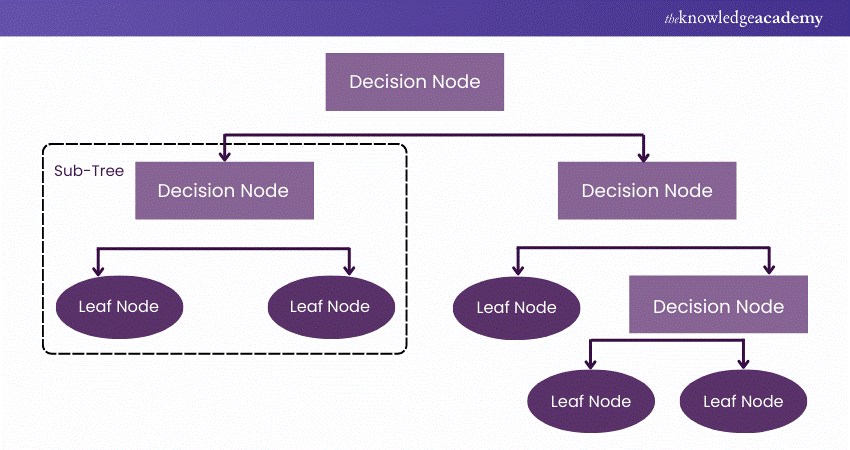
Based on available features, both node types perform evaluation to form homogenous subsets, signified by terminal nodes or leaf nodes. The leaf nodes represent every possible outcome within the dataset.
Expand your Data Science skills through data visualisation and data modelling techniques in our comprehensive Advanced Data Science Certification Course - Sign up now!
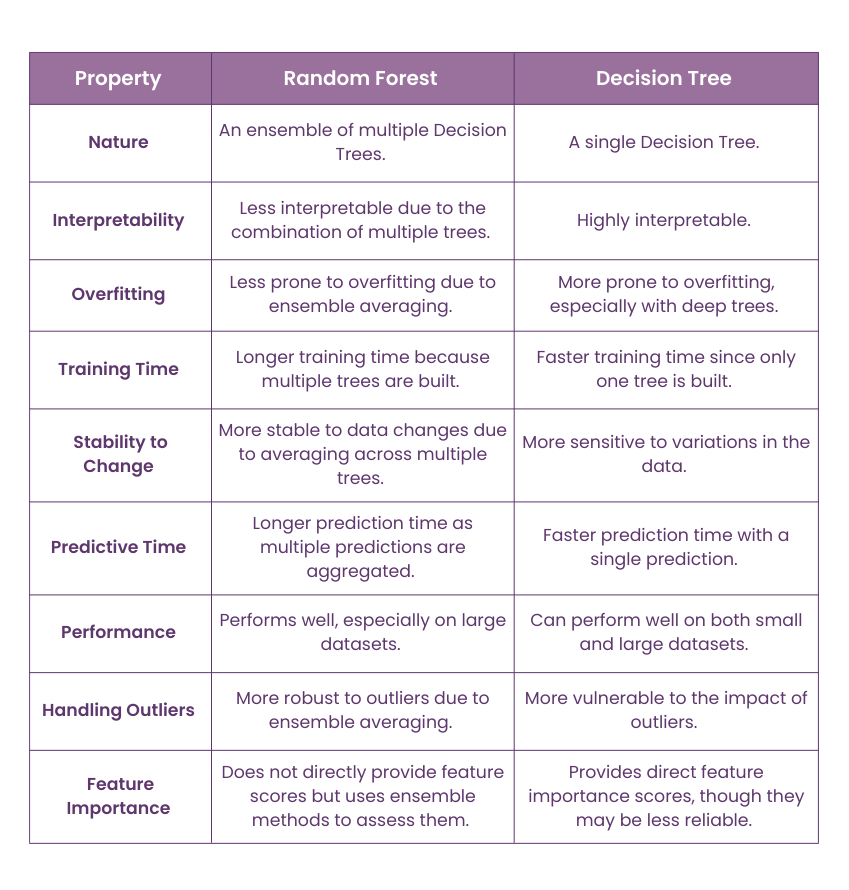
Differences Between Random Forest and Decision Trees
The following table summarises the key differences between random forest and Decision Tree models:
When to Use Random Forest Vs Decision Tree
The following points will help you decide when to use the random forest model and when to opt for a Decision Tree:

1) Go for a Decision Tree when interpretability is essential, and you require a simple, easy-to-understand model.
2) Use a random forest when you seek improved accuracy, better generalisation performance and robustness to overfitting, especially on complex datasets with high-dimensional feature spaces.
3) When computational efficiency is a priority and you're working with a small dataset, a Decision Tree is the way to go. Its simplicity and speed make it a good fit for these scenarios.
4) A random forest can provide better results if you have a vast dataset with complex relationships between labels and features.
Gain insight and expertise on different Machine Learning algorithms in our detailed Machine Learning Course – Sign up now!
Conclusion
In conclusion, the choice between Random Forest Vs Decision Tree comes down to the dataset's complexity and your data analysis needs. Decision Trees are the ideal option for interpretability and simplicity involving smaller datasets. However, when greater accuracy and robustness involving large datasets are the priority, random forest is the go-to solution. The key distinctions between the two, as outlined in this blog, will help you make the right choice for your data science requirements.
Master statistical methods and data visualisation in our Data Science With R Training - Sign up now!
Frequently Asked Questions
Why Does Random Forest Outperform Decision Tree?

Random forest outperforms Decision Trees due to the following factors:
a) Reduction in Overfitting
b) Bias-Variance Trade-off
c) Robustness to Noise
d) Feature Importance
e) Improved Accuracy
What are the Limitations of Random Forest?
While Random Forest is a versatile algorithm, it does come with some limitations:
a) Computational complexity
b) Significant memory usage
c) Less interpretability
d) Difficulty in handling imbalanced data
e) Overfitting with noisy data
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Data Science Courses, including the Advanced Data Science Certification Course and the Predictive Analytics Course. These courses cater to different skill levels, providing comprehensive insights into Decision Tree Analysis.
Our Data, Analytics & AI Blogs cover a range of topics related to Data Analytics, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Data Science skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Decision Tree Modeling Using R Training
Decision Tree Modeling Using R Training
Decision Tree Modeling Using R Training
Fri 28th Feb 2025
Decision Tree Modeling Using R Training
Fri 4th Apr 2025
Decision Tree Modeling Using R Training
Fri 27th Jun 2025
Decision Tree Modeling Using R Training
Fri 29th Aug 2025
Decision Tree Modeling Using R Training
Fri 24th Oct 2025
Decision Tree Modeling Using R Training
Fri 5th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


