



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on 01344203999 and speak to our training experts, we may still be able to help with your training requirements.
Top 15+ Data Engineering Projects Ideas for Beginners to Advanced
Sienna Roberts 21 February 2025Curious to explore Data Engineering Projects for your bright career? They involve designing, building, and maintaining systems for collecting, storing, and analysing data. Continue reading this blog to understand Data Engineering Projects and how you can utilise them to elevate your career as a Data Engineer.
Home
 Resources
Data, Analytics & AI
Top 15+ Data Engineering Projects Ideas for Beginners to Advanced
Resources
Data, Analytics & AI
Top 15+ Data Engineering Projects Ideas for Beginners to Advanced
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Are you ready to transform your data engineering knowledge into practical, future and career-driven skills? Data Engineering Projects are something you cannot miss out on, especially with regard to keeping in line with the market competition. Its relevance can be understood from the fact that many hiring managers prioritise candidates during candidate screening, possessing the relevant skills, education, and experience in Data Engineering projects.
In this blog, you will explore the comprehensive overview of the Data Engineering Projects, ranging from beginner to advanced. This will be a hugely insightful blog, so we recommend you read till the end. Wasting no time, let’s press the accelerator!
Table of Contents
1) What is Data Engineering?
2) Structure of a Data Engineering Project
3) Beginner Level Data Engineering Projects
4) Intermediate Level Data Engineering Projects
5) Advanced Level Data Engineering Projects
6) Data Engineering Projects on GitHub
7) Why Should You Work on Data Engineering-Based Projects?
8) Conclusion
What is Data Engineering?
Data Engineering is a branch of engineering that primarily focuses on structuring data to be efficiently utilised across diverse technologies. This process typically includes creating or modifying databases and ensuring that data remains accessible, regardless of its origin or storage method.
Data Engineers are an essential part of the Data Engineering discipline who analyse and derive insights from research data. They then use these insights to build innovative tools and systems that support future research efforts. Additionally, Data Engineers often contribute to developing business intelligence (BI) applications by generating reports based on data analysis.
Data Engineers are also responsible for designing, constructing, and maintaining scalable data pipelines to facilitate the collection, storage, and processing of large datasets. They ensure data integrity and availability by implementing robust data management practices. Their responsibilities also revolve around optimising data systems and working closely with data scientists and analysts to understand their data requirements and provide the necessary infrastructure to meet those needs.
Through their vast experiences, Data Engineers can effortlessly create applications and systems to transform raw data into actionable business insights. For this, they use the applications of comprehensive reports and dashboards that aid in strategic decision-making, helping businesses enhance their operations and achieve their goals.

Structure of a Data Engineering Project
A well-structured data engineering project involves several key components that ensure a smooth flow from conception to deployment. Here are the main steps broken down into clear pointers:
1) Define Project Scope and Objectives: Identify the problem to be solved, understand the business requirements, and set clear goals. Engaging stakeholders during this phase can provide valuable insights and facilitate better decision-making.
2) Data Collection and Ingestion: Identify data sources, which may include databases, APIs, file systems, and third-party data providers. Design a robust pipeline to efficiently extract, transform, and load (ETL) the data into a centralised repository, ensuring data quality.
3) Data Storage and Management: Choose the right storage solutions based on project requirements, considering factors such as data volume, access speed, and analytical needs. Implement data governance practices to maintain security and compliance, including access controls, metadata management, and data lineage tracking.
4) Deployment and Monitoring: Deploy the data pipeline in a production environment and set up continuous monitoring to ensure efficient operation and early identification of potential issues. Regularly update the infrastructure to adapt to changing business needs and emerging technologies.
Beginner Level Data Engineering Projects
To help you get started on your data engineering journey, we have compiled a list of engaging projects tailored for the beginners:
1) Smart IoT Infrastructure
Building a smart IoT infrastructure involves integrating devices, sensors, and systems to collect, process, and analyse data. Begin by defining your objectives and requirements, and accordingly, design a powerful architecture comprising the device, network, data processing, and application layers. Choose appropriate hardware like sensors, microcontrollers, and gateways, and use cloud platforms such as AWS IoT or Azure IoT for scalable storage and analytics.
Post that, develop a data pipeline for ingestion, storage, and processing using tools like Apache Kafka and Spark. To this, you can implement machine learning (ML) models for intelligent decision-making and creating user-friendly interfaces. However, you must ensure data security with encryption and authentication. Test thoroughly and deploy the infrastructure, followed by continuous monitoring and maintenance for optimal performance. Remember to prioritise security, scalability, and user experience (UX) throughout the process.
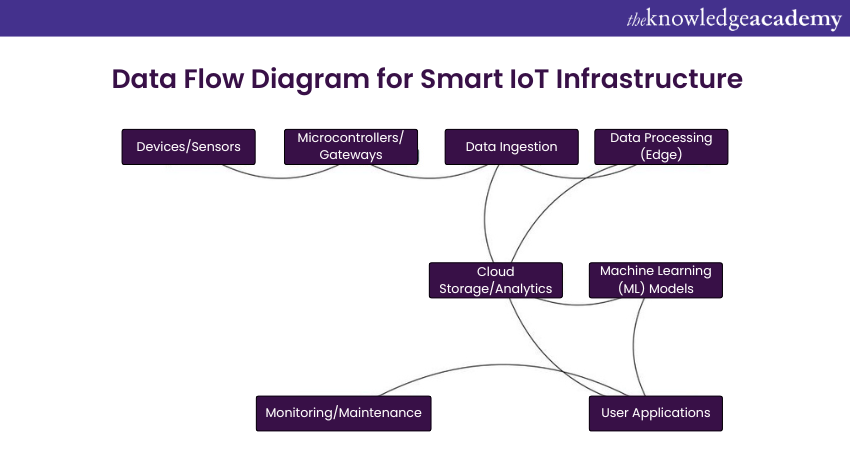
The diagram above illustrates the data flow in the IoT project:
a) Devices/Sensors: Collect data from the environment
b) Microcontrollers/Gateways: Aggregate and transmit data to the cloud
c) Data Ingestion: Capture and store data from devices
d) Data Processing (Edge): Perform real-time processing at the edge
e) Cloud Storage/Analytics: Store and analyse data in the cloud
f) Machine Learning (ML) Models: Apply machine learning (ML) for intelligent decision-making
g) User Applications: Present data to users through applications
h) Monitoring/Maintenance: Continuously monitor and maintain the system for optimal performance
2) Analysing Aviation Data
In the airline industry, companies are always looking for ways to improve their services. To this, an effective strategy helps to gain a deeper insight into their customers.
This Data Engineering Project mainly delves into collecting both real-time streaming data from Airline APIs using NiFi and batch data from AWS Redshift through the utilisation of Sqoop.
This analysis are conducted using tools like Apache Hive and Druid. The project compares the performance of these two approaches and encourage discussions on optimisation techniques for Hive. The results will be shown using AWS Quicksight.
3) Forecasting demand In Shipping and Distribution
This Data Engineering Project focuses on demand forecasting, which entails a comprehensive analysis of demand data and the effective application of statistical models to project trends.
This kind of data engineering project proves invaluable for logistics companies, for example, in gaining insights into the expected product orders from individual customers at different locations. By harnessing demand forecasts as an essential input for allocation tools, the company can gain the capability to optimise its operational activities. This optimisation includes route planning for delivery vehicles and strategic capacity planning for the long term.
Another example is a vendor or insurer seeking to understand the anticipated number of product returns due to failures. In such cases, demand forecasting aids in risk assessment and resource allocation, allowing these entities to make informed decisions and plan for contingencies accordingly.
4) Analysing Event Data
This project offers an exciting opportunity for data enthusiasts to explore reports generated by city governments.
The focus is on a detailed analysis of accidents that occur within a major urban area. By leveraging data from an open data portal, you can create a comprehensive data engineering pipeline. This pipeline involves data extraction, cleansing, transformation, exploratory analysis, data visualisation, and orchestrating the flow of event data on cloud platforms.
The project begins with a thorough exploration of various data engineering methodologies aimed at efficiently extracting real-time streaming event data from the selected city’s accident dataset. This data is then processed on AWS to derive Key Performance Indicators (KPIs) that serve as crucial metrics for understanding accident trends and patterns.
These KPIs are integrated into Elasticsearch, allowing for text-based searches and in-depth analysis. The Kibana visualisation tool is then used to present these insights visually, enabling effective decision-making.
5) Data Ingestion with Google Cloud Platform
This project aims to create a data ingestion and processing pipeline for both real-time streaming and batch loads on the Google Cloud Platform (GCP). The dataset in use is taken from the Yelp dataset, which is widely utilised for academic and research purposes.
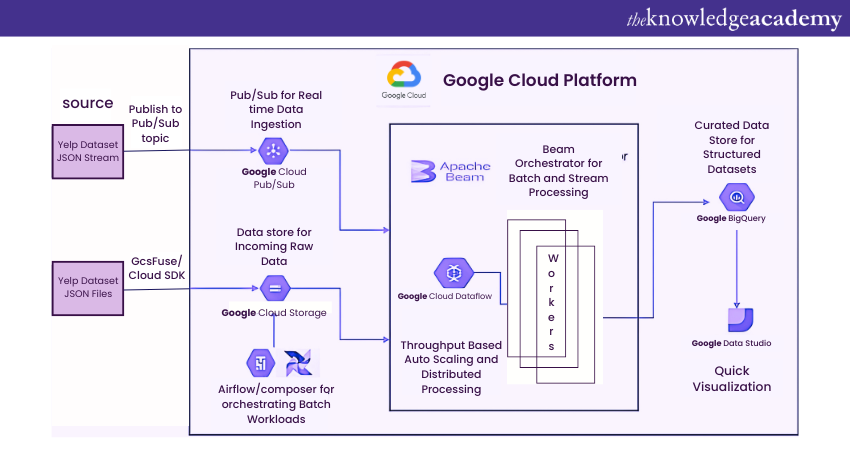
To this end, a service account is first created on GCP, and later, the Google Cloud SDK (Software Development Kit) is downloaded. After that, Python and all necessary dependencies are installed and connected to the GCP account. The Yelp dataset, available in JSON format, is then uploaded to Google Cloud Storage via the Cloud SDK and integrated with Cloud Composer.
The JSON data stream is published to a Pub/Sub topic. Cloud Composer and Pub/Sub outputs are processed with Apache Beam and connected to Google Dataflow. Structured data is sent from Dataflow workers to Google BigQuery. Finally, the processed data is visualised using Google Data Studio.
6) Data Visualisation
Data visualisation is the science of transforming raw data into visual forms such as graphs, charts, and graphical representations. The main reason behind is when you encounter a graph or chart; you can effectively grasp its conveyed information.
To begin with, envision a scenario where you are given the task to determine how many individuals in your neighbourhood are viewers of "Game of Thrones" (GoT). For this, you could individually inquire with each resident; however, that would be an exceedingly time-consuming endeavour.
Instead, you can create a map that pinpoints the residences of your neighbours and employ a colour-coding system to distinguish between GoT enthusiasts and their non-alternatives. This visual map enables anyone with the question "Who watches GoT?" to obtain a rapid answer by simply looking at the map.
Data visualisation also proven invaluable for conveying data pertaining to trends over time. In these cases, data visualisation simplifies the understanding of data patterns, making it among the most sought-after tools for data analysis and communication.
Master random processes convergency and Markov Chains with Probability And Statistics For Data Science Training- join now!
Intermediate Level Data Engineering Projects
After gaining some foundational skills, it’s time to tackle more challenging projects. The following are the list of intermediate-level Data Engineering Projects:
1) Log Analytics Project
Logs are essential for understanding the of a security breach. identifying operational trends, establishing a reference point, and conducting forensic and audit analysis.
In the context of this project, your expertise in Data Engineering will be applied to the following:
a) Acquire server log data
b) Securely store it within the distributed storage framework of Hadoop Distributed File System (HDFS)
c) Use the dataflow management tool Apache NiFi to store the log data
Additionally, this Data Engineering Project encompasses:
a) Stages of data cleaning and transformation
b) To leverage the capabilities of Apache Spark to uncover valuable insights regarding the activities transpiring on the server.
These insights range from identifying and accessing hosts to pinpointing the countries responsible for most of the network traffic directed towards the server. Subsequently, these findings are then presented visually using Plotly-Dash, describing the narrative about the server's activities. It will also explore any potential concerns that may warrant your team's attention.
You can employ the architectural framework referred to as the Lambda architecture, which typically handles both real-time streaming data and batch data. Log files are then directed to a Kafka topic through NiFi. This data is subjected to analysis and storage in a Cassandra database that constitutes the "Hot Path." The data extracted from Kafka is also then archived in the HDFS path for future research, characterising the "Cold Path" within this architectural setup.
2) COVID-19 Data Analysis
This is a fascinating Data Engineering Project that offers an opportunity to gain experience in the preparation and integration of datasets, a crucial step in the Live COVID-19 API dataset analysis.
Through the process of data preprocessing, cleansing, and transformation, you create informative visualisations in diverse dashboards.
The project entails the following vital aspects:
1) The calculation of country-specific new recoveries is performed and the identification of country-specific new confirmed COVID-19 cases.
2) The COVID-19 data obtained will be incorporated will be then incorporated into a Kafka topic and Hadoop Distributed File System (HDFS) using Apache NiFi.
3) Following this, the data will be carefully processed and analyzed within a PySpark cluster, as outlined in the PySpark Cheat Sheet, before being ingested into the Hive database.
4)The outcome will then be presented in the form of informative plots through the utilisation of tools like Tableau and Quicksight.
3) MovieLens Data Analysis for Recommendation Systems
A Recommender System helps predict or filter user preferences based on their choices. These systems are used in many areas, including movies, music, news, books, research articles, and product recommendations.
This example focuses on movie recommendation systems used by popular streaming services like Netflix and Amazon Prime. These systems analyse users' viewing habits to suggest movies that match their interests. Before showing recommendations, a data pipeline collects data from various sources and feeds it into the recommendation engine.
In the context of this project, you will delve into the following:
1) Utilisation of Databricks Spark on Azure, incorporating Spark SQL to construct this data pipeline.
2) The initial step involves downloading the dataset from a research group situated within the Department of Computer Science and Engineering at the University of Minnesota.
3) Subsequently, the dataset is manually uploaded to Azure Data Lake Storage.
4) The core of the project revolves around the creation of a Data Factory pipeline, which is employed to ingest files.
5) Following this data ingestion, Databricks is harnessed to conduct an in-depth analysis of the dataset.
4) Example of a Retail Analytics Project
Project goal: To analyse a retail store's dataset to boost its decision-making proces, by keeping a strong focus on areas such as inventory management, supply chain optimisation, and marketing strategies. By working on this project, you will:
1) Gain practical experience using AWS EC2 instances and Docker Compose for project execution.
2) Acquire a deep understanding of the Hadoop Distributed File System (HDFS) and its critical commands for efficient data storage and retrieval.
3) Learn to leverage Sqoop Jobs for data extraction and loading tasks, enhancing your data transfer capabilities.
4) Develop proficiency in executing data transformation operations within Hive, a powerful data warehousing tool.
5) Gain practical experience setting up MySQL for table creation and performing data migration tasks from Relational Database Management Systems (RDBMS) to Hive warehouses.
This project offers an excellent opportunity to explore the practical aspects of Data Engineering in the context of retail analytics.
Become proficient in different data visualisation methods in Python with our Advanced Data Science Certification Course – register now!
Advanced Level Data Engineering Projects
As the field of data engineering continues to evolve, professionals are increasingly tackling complex challenges that require sophisticated solutions. The following are some of the advanced levels of Data Engineering Projects. The following are some of the advanced levels of Data Engineering Projects:
1) Detecting Anomalies In Cloud Servers
Anomaly detection is a critical tool for cloud platform administrators looking to enhance their cloud infrastructure reliability. It helps by enabling the early identification of unexpected system behaviours and allowing administrators to take corrective actions beforehand.
This project offers a practical example of a Cloud Dataflow streaming pipeline. It can be seamlessly integrated with BigQuery ML and Cloud AI Platform to facilitate anomaly detection within a cloud environment. Moreover, the projects showcase the effectiveness of Dataflow in extracting features and conducting real-time outlier detection.
By engaging in this project, participants can gain
a) Their understanding of anomaly detection techniques within cloud environments.
b) Hands-on experience with Cloud Dataflow, BigQuery ML, and Cloud AI Platform.
c) Learn how to effectively extract features and perform real-time outlier detection—a critical skill for ensuring cloud reliability.
d) Benefit from a reference implementation that has successfully processed substantial volumes of data, providing practical insights into anomaly detection at scale within cloud platforms.
2) Utilising Big Data for Smart City Development
The smart city consists of a highly advanced urban environment that uses electronic data collection methods and sensors to gather and manage big data. This data is then harnessed to enhance the city's assets and resources management.
This big data is collected from diverse sources, including citizens, devices, buildings, and assets and encompasses various aspects such as traffic and transportation systems, power plants, utilities, water supply networks, etc. Later, the Big Data techniques are employed to gather, process, and analyse the collected data.
This project integrates multiple building blocks, media sources, and analytics components with the assistance of the OpenVINO Toolkit. It is designed to showcase the practical implementation of analytics and management for applications like traffic and stadium sensing within the context of a smart city.
3) Analysing Tourist Behaviour
The primary aim of this Big Data project is to investigate the behaviour of visitors, enabling the understanding of tourists' preferences and their preferred locations.
Tourists using the internet and technology during their travels leave behind digital traces that can be efficiently gathered through Big Data techniques. Most of this data originates from external sources and, therefore, cannot fit into traditional databases, necessitating Big Data analytics.
These data sources are also leveraged to aid companies operating in the airline, hotel, and tourism sectors. They facilitate the expansion of their client base and enhance marketing strategies. This data assists tourism organisations in visualising and forecasting future trends and serves as a valuable tool for the industry.
4) Generating Image Captions
This project utilised Python source code for big data analysis, emphasising its complexity and advanced nature. The creation of image captions, as demonstrated in this project, is not suited for beginners. It involves intricate techniques such as Convolution Neural Network (CNN) and Recurrent Neural Network (RNN) with BEAM Search.
The project draws from rich and diverse datasets, including MSCOCO, Flickr8k, Flickr30k, PASCAL 1K, AI Challenger Dataset, and STAIR Captions, to generate image descriptions. These datasets are at the forefront of discussions in this domain.
Boost your career with Data Science Training and be industry-ready with a specialised course on Data Science!
Data Engineering Projects on GitHub
GitHub is an excellent platform for showcasing data engineering projects, allowing developers and data engineers to share their work, collaborate, and contribute to open-source projects. Below are three notable data engineering projects available on GitHub that exemplify real-world applications in various domains.
1) Real-time Financial Market Data Pipeline with Finnhub API and Kafka
This project focuses on building a real-time data pipeline to capture and process financial market data using the Finnhub API and Apache Kafka. The pipeline collects live stock prices, market news, and other relevant data in real time, allowing users to analyse financial trends as they happen.
By leveraging Kafka’s event streaming capabilities, the project ensures reliable data flow and processing, making it ideal for traders and analysts seeking to make timely decisions based on up-to-date information.
2) Real-time Music Application Data Processing Pipeline
This project involves developing a data processing pipeline for a real-time music application. It captures user interactions, such as song plays, skips, and likes, and processes this data to generate insights into user preferences and trends.
The pipeline uses tools like Apache Kafka for streaming data and Apache Spark for batch processing, ensuring the system can handle large volumes of data while delivering quick insights.
3) Shipping and Distribution Demand Forecasting
The Shipping and Distribution Demand Forecasting project aims to predict future demand for shipping and distribution services using historical data. By employing machine learning algorithms and data processing techniques, this project analyses past shipment data, weather conditions, and market trends to create accurate demand forecasts.
The project typically utilises tools like Python, Pandas, and Scikit-learn, along with visualisation libraries to present the forecasting results. These insights help shipping companies optimise their operations, reduce costs, and improve service delivery by anticipating fluctuations in demand.
Why Should You Work on Data Engineering-Based Projects?
Working on Data Engineering Projects offers numerous benefits that can significantly boost your professional development and career prospects:
1) Improved Customer Focus with Big Data and Machine Learning (ML): By combining data engineering with machine learning (ML), you can develop marketing strategies based on customer forecasts. Furthermore, businesses can leverage big data analytics to become more customer-centric while tailoring their services to meet customer needs.
2) In-demand Skill Set: Acquiring data engineering skills, which are highly sought after in the industry, will accelerate your career growth. If you are new to big data, engaging in Data Engineering Projects is an excellent way to gain practical experience and develop relevant skills.
3) Core Responsibilities of Data Engineers: Data engineers are tasked with building and managing computer hardware and software systems for data collection, formatting, storage, and processing. They ensure that data is readily accessible to users, highlighting the importance of data reliability and availability.
4) Comprehensive Understanding of Data Processes: Data Engineering Projects provide a holistic view of the end-to-end data process, from exploratory data analysis (EDA) and data cleansing to data modelling and visualisation. This comprehensive approach is invaluable for understanding how data flows and is utilised within an organisation.
5) Resume Enhancement: Including Data Engineering Projects on your resume makes your job application stand out. It demonstrates your practical experience and expertise in handling real-world data challenges, giving you an edge over other candidates.
Conclusion
We hope you now have a clear understanding of Data Engineering Projects. In this blog, you explored a range of comprehensive projects, from fundamental to advanced levels. Whether you’re a beginner starting your professional journey or an experienced professional seeking a new challenge, these projects have everything yo transform you into a well-versed Data Engineer.
Master Machine Learning algorithms and their implementation in R with our Data Science With R Training- book your slots now!
Frequently Asked Questions
How to Start your First Data Engineering Project?
Begin by identifying a real-world problem or dataset that interests you. Outline the project's scope, choose suitable tools and technologies, and focus on data collection, cleaning, processing, and visualisation to create actionable insights.
How do I Create a Data Engineer Portfolio?
Showcase your skills by including diverse projects that highlight data collection, processing, and visualisation. Additionally, use platforms like GitHub to display your code and create a personal website or LinkedIn profile to present your achievements and technical expertise.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 3,000 online courses across 490+ locations in 190+ countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Data Science Courses, including the Python Data Science Course, Predictive Analytics Training and the Data Mining Training. These courses cater to different skill levels, providing comprehensive insights into 3 Simple Steps to Find Big Data Patterns: Tips and Techniques.
Our Data, Analytics and AI Blogs cover a range of topics related to Data Engineering, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Data Science skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Python Data Science Course
Python Data Science Course
Python Data Science Course
Mon 24th Mar 2025
Python Data Science Course
Mon 26th May 2025
Python Data Science Course
Mon 28th Jul 2025
Python Data Science Course
Mon 20th Oct 2025
Python Data Science Course
Mon 1st Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


