



 Top Rated Course
Top Rated Course


We may not have the course you’re looking for. If you enquire or give us a call on 01344203999 and speak to our training experts, we may still be able to help with your training requirements.
Top 30 DBMS Interview Questions and Answers: Explained
Sophia Ellis 19 November 2024This blog about DBMS Interview Questions explains better ideas and ways to optimise data queries. It helps you get ready for your interviews easily and with confidence. Learn the important insights about DBMS interviews with clear explanations of the main questions and answers. Improve your skills in managing databases by reading further!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

In information technology (IT), conducting a Database Management System (DBMS) interview is paramount for both experienced professionals and fresh graduates. The ability to articulate responses to DBMS Interview Questions showcases a candidate's proficiency in managing data effectively. In this extensive guide, we will delve into the Top 30 DBMS Interview Questions and Answers, providing detailed explanations to help you answer questions confidently and understand the underlying principles that govern Database Management.
Table of Contents
1) DBMS Interview Questions and Answers
a) What is DBMS?
b) What are primary, super, candidate, and foreign keys?
c) What is database normalisation?
d) What are the distinctions between DDL, DML, and DCL in SQL?
e) What is a trigger?
f) What is a stored procedure?
g) What are indexes?
h) What is CLAUSE in SQL?
i) What is denormalisation?
j) What is a live lock?
2) Conclusion
DBMS Interview Questions and Answers
To navigate the complex landscape of a Database Management System (DBMS), you need technical skills and a deep understanding of key concepts. The following section will reveal top DBMS Interview Questions, along with insightful answers to strengthen your knowledge and prepare you for success in any database-related interview. Let's dive into the world of data excellence!

1) What is DBMS?
That basic question is the crux of any database-related interview sets the stage for discussing the Database Management System. DBMS is a robust software suite that efficiently manages and organises data in a database. It serves as the foundation for today's information systems (IS), enabling smooth storage, retrieval, and manipulation of large datasets.
It ensures data integrity through security measures and access controls. It allows users to interact with databases via an easy-to-use interface, abstracting the complexities of underlying data structures. Key functions of DBMS include data definition, storage management, and query optimisation. This structured approach reduces redundancy and ensures data consistency.
2) What are primary, super, candidate, and foreign keys?
Understanding keys is crucial in relational databases. The primary key helps in identifying each record in a table uniquely, while foreign keys establish relationships between tables. Super keys are sets of attributes uniquely identifying a record, and candidate keys are minimal super keys, offering insight into the intricate web of relationships within a database.
3) What is database normalisation?
Database normalisation is a process in relational database design that organises and structures data to minimise redundancy and dependency. The primary goal is to achieve a well-organised database that reduces data anomalies such as insertion, update, and deletion errors. Data is systematically divided into tables through normalisation, and relationships are established to eliminate data duplication.
This ensures efficient storage, reduces the risk of data inconsistencies, and simplifies the process of querying and updating information. The normalisation process typically involves applying various standard forms, such as First Normal Form (1NF), Second Normal Form (2NF), and Third Normal Form (3NF), to make sure of data integrity and optimise database performance.
4) What are the distinctions between DDL, DML, and DCL in SQL?
Structured Query Language (SQL) is the backbone of database manipulation, comprising three essential components:
1) Data Definition Language (DDL)
2) Data Manipulation Language (DML)
3) Data Control Language (DCL)
They serve different roles in Database Management. DDL focuses on defining and modifying the structure of the database. It encompasses operations like creating, altering, and dropping tables or schemas. DML, on the other hand, revolves around manipulating data within the database. It involves actions such as inserting, updating, and deleting records.
DCL deals with access control and permissions. It regulates user access to specific data or operations. While DDL shapes the database's blueprint, DML moulds its content, and DCL safeguards its integrity. They collectively form a strong framework for efficient and secure Database Management in SQL. Understanding these delineations is crucial for proficiently handling the diverse aspects of database administration.
5) What is a trigger?
A trigger in Database Management is a predefined set of instructions. It automatically executes in response to specific events, like INSERT, UPDATE, or DELETE operations in the database state. These automated procedures enhance data integrity, enforce business rules, and streamline Database Management.
Triggers can be crucial in maintaining consistency by executing actions like validating data, updating related tables, or logging specific events. Their implementation ensures that predefined actions are taken without manual intervention, contributing to database systems' overall efficiency and reliability.
6) What is a stored procedure?
Stored procedures are a precompiled collection of a single or more SQL statements that are stored in a database. It acts as a reusable and encapsulated logic unit, enhancing database efficiency and security. Stored procedures are executed as a single unit, reducing the need for repetitive coding and ensuring consistent data manipulation.
They promote code modularity, ease of maintenance, and improved performance by minimising data transfer between the database and application. Additionally, stored procedures can be parameterised, allowing for dynamic execution based on input parameters. This further enhances their flexibility and applicability in various Database Management scenarios.
7) What are indexes?
Indexes are structures that enhance data retrieval speed by providing quick access paths to specific rows in a table. While they significantly improve query performance, it's essential to be mindful of the trade-offs in terms of storage and maintenance.
8) What is Clause in SQL?
In SQL, a clause is a reserved keyword for filtering, sorting, or manipulating data. Common clauses include WHERE for filtering rows, ORDER BY for sorting results, and GROUP BY for aggregating data.
9) What is denormalisation?
Denormalisation, a deliberate database design strategy, introduces redundancy to enhance query performance. Consolidating tables and minimising joins speed up data retrieval. However, this strategic move requires careful consideration, as increased redundancy may lead to data inconsistency and maintenance challenges.
Balancing the benefits of quicker query execution with potential downsides necessitates a thorough understanding of the specific use case and data access patterns. Prudent implementation, often guided by performance metrics and usage scenarios, ensures denormalisation and serves its purpose without compromising the overall integrity and manageability of the database System.
10) What is a live lock?
A live lock is a nuanced challenge in database Systems. It unfolds when multiple transactions persistently attempt an operation that consistently fails, perpetuating a ceaseless cycle of retries without advancement. Unlike a deadlock, where transactions halt, in a live lock, they continuously retry without success.
This scenario demands meticulous attention as it can impact system performance and user experience (UX). Database administrators must employ strategic intervention and potentially alter transactional logic to break the cycle and restore the system's functionality. This emphasises the importance of proactive management in dynamic database environments.
Learn more about how databases work with our Redis Cluster database Training – Sign up today!
11) What are the advantages of DBMS in contrast to traditional file-based systems?
The advantages of DBMS over traditional file-based systems are profound, transforming the data management landscape. Here are the key advantages explained:

a) Data integrity: DBMS ensures the accuracy and consistency of data through features like constraints and validations, preventing data anomalies.
b) Data security: Access control mechanisms in DBMS restrict unauthorised access, safeguarding sensitive information from unauthorised users.
c) Data independence: Changes in the database structure don’t affect application programs, promoting flexibility and ease of maintenance.
d) Data retrieval: DBMS provides efficient and fast data retrieval through the use of indexes and optimised query processing, enhancing overall system performance.
e) Concurrency control: DBMS manages concurrent access to data, preventing conflicts and ensuring data consistency in multi-user environments.
f) Scalability: DBMS allows for seamless scalability, accommodating growing data volumes without compromising performance or integrity.
g) Backup and recovery: Robust backup and recovery mechanisms in DBMS protect against data loss or system failures, ensuring business continuity.
h) Data abstraction: DBMS provides different levels of data abstraction. This allows users to interact with data at a conceptual level without worrying about underlying complexities.
12. Explain the different types of DBMS architecture
The architecture of DBMS plays an important role in its efficiency and functionality. Here are the different types of DBMS Architecture explained:
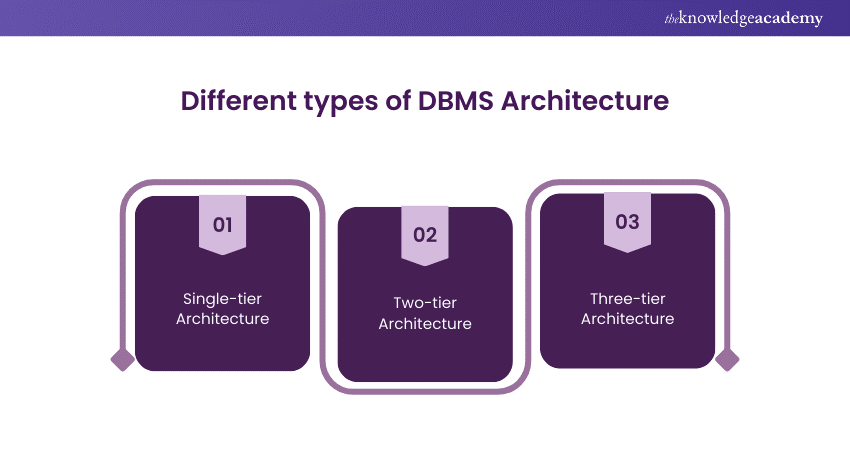
1) Single-tier Architecture:
a) The DBMS is directly linked to the user interface (UI).
b) Simple and straightforward, suitable for small-scale applications.
c) Limited scalability and maintenance capabilities.
2) Two-tier Architecture:
Separates the database from the user interface (UI).
It enhances scalability and allows multiple users to access the database concurrently.
Commonly used in client-server applications.
3) Three-tier Architecture:
The system is divided into three components: client, application server, and database server.
Offers better scalability, flexibility, and maintenance.
Facilitates distributed computing and improved performance for larger applications.
Each Architecture type presents a trade-off between simplicity and scalability. This caters to different requirements based on the scope and complexity of the application.
13) What do you mean by functional dependency?
Functional dependency denotes a relationship between two sets of attributes in a database. If knowing the value of one set uniquely determines the value of another set, a functional dependency exists between them.
14) Explain the different normal forms for normalisation.
Normalisation is a critical aspect of database design. It involves organising a database to minimise redundancy and dependency. The different standard forms include:
a) First Normal Form (1NF): Eliminates duplicate rows.
b) Second Normal Form (2NF): Ensures no partial dependencies on a composite primary key.
c) Third Normal Form (3NF): Eliminates transitive dependencies.
15) Explain the ACID properties of a DBMS.
ACID, an acronym for Atomicity, Consistency, Isolation, and Durability, outlines the foundational properties of reliable database transactions:
a) Atomicity: Transactions are seen as a single, indivisible unit.
b) Consistency: The database transitions from one consistent state to another.
c) Isolation: Transactions are executed independently.
d) Durability: Once a transaction is completed, its effects are permanent.
16) What are the different levels of data abstraction?
Data abstraction involves presenting complex systems in a simplified manner. This allows users to interact with the system at various levels. The different levels of data abstraction include:
1) Physical level:
a) Describes how data is stored on physical storage devices.
b) Involves details such as data structures, file organisation, and access methods.
2) Logical level:
a) Represents the entire database in terms of a high-level data model.
b) It is concerned with defining tables, views, relationships, and constraints.
3) View level:
a) Provides a user-specific, customised view of the data.
b) Allows users to interact with a subset of the database, concealing unnecessary details.
These levels of abstraction ensure that users interact with the database at a level appropriate to their needs. This promotes simplicity, data independence, and effective management of complex database systems.
17) What is a deadlock?
A deadlock in Database Management occurs when two or more transactions are blocked indefinitely, each holding resources that the other requires to proceed. It creates a standstill, as these transactions cannot move forward, leading to perpetual waiting. Deadlocks are a critical concern in multi-user database environments, and their occurrence can hinder system performance.
Resolution strategies involve detection mechanisms to identify deadlocks and subsequent actions, such as transaction rollback or timeout mechanisms, to release the locked resources and restore system functionality. Proper deadlock management is crucial for maintaining the integrity and efficiency of a database system.
18) In the event of a deadlock, what would you do?
Effectively dealing with a deadlock involves employing various techniques such as deadlock detection, prevention, and resolution. Common strategies include setting timeouts, rolling back transactions, or using resource allocation graphs.
19) What should you do when you do not have any primary key for a table?
While it is highly recommended to have a primary key for each table, a unique constraint or combination of columns can serve as a surrogate key if unavailable. This ensures that each record is still uniquely identifiable.
20) What is relational algebra?
Relational algebra is a mathematical set of operations used to manipulate relational databases. It includes operations like selection, projection, union, intersection, and join, providing a theoretical foundation for query languages like SQL.
Educate yourself about databases with our Relational databases & Modelling Training – Join today!
21) What is relational calculus?
Relational calculus, a non-procedural query language, articulates database queries through mathematical logic. Unlike procedural languages, it emphasises specifying the desired data outcomes, allowing users to focus on the "what" rather than the "how" of data retrieval. This abstraction enhances the clarity and expressiveness of database queries.
22) What is an entity?
In databases, an entity is a singular and distinguishable object or concept depicted within the database. Entities encompass a diverse spectrum, ranging from individuals and locations to objects or events. They are the foundational building blocks, capturing and organising essential information within the database structure.
23) What is an entity type?
In the context of Database Management, an entity type refers to a category or class of distinct objects sharing common attributes. Each entity type represents a set of entities that exhibit similar characteristics. For example, in a company database, "Employee" would be an entity type encompassing individual instances of employees. Understanding entity types is crucial for designing a well-organised and efficient database structure.
24) What do you mean by extension and intention?
In the context of databases, "extension" refers to the actual data stored in a table, representing the concrete records. On the other hand, "intension" pertains to the schema or structure of the table, defining the organisation of the data. While extension deals with tangible information, intention outlines the blueprint for how the data is structured and organised within the database. This ensures a clear separation between the concrete data and its conceptual design.
25) What is System R? How many of its two major subsystems?
System R was developed by IBM which is a groundbreaking Relational Database Management System (RDBMS). It laid the foundation for future relational databases. System R introduced the concept of Structured Query Language (SQL) for data manipulation and retrieval. System R comprises of two major subsystems:
a) Research storage: Responsible for storing and retrieving data.
b) System Relational Data Subsystem: Manages data definition, manipulation, and control.
26) What is data independence?
Data independence is the separation of data structure from the application programs and user interfaces (UIs). It allows modifications in the database schema without affecting the higher-level structures. There are two types: Logical Data Independence, which ensures changes in logical schema don't impact application programs, and Physical Data Independence. It enables alterations in the physical storage details without affecting the application's logical structure. This flexibility enhances adaptability and facilitates efficient Database Management.
27) What is join?
A "join" in Database Management combines rows from multiple tables based on related columns. This operation enhances data retrieval by connecting information from distinct tables, creating a comprehensive dataset. Different types of joins, such as INNER JOIN, OUTER JOIN, and CROSS JOIN, offer varied approaches to linking tables. This enables efficient data consolidation and analysis in relational database systems. Understanding joins is crucial for crafting sophisticated and effective SQL queries.
28) What is 1NF?
The first Normal Form (1NF) is a fundamental rule in database normalisation. This ensures that each cell in a table contains a single, indivisible value. 1NF lays the groundwork for a well-organised database by eliminating duplicate rows and enforcing unique records. It mandates atomicity at the lowest level, allowing for efficient data retrieval and streamlined database operations. This eventually contributes to the overall integrity and coherence of the data structure.
29) What is 2NF?
The second Normal Form (2NF) is a critical step in database normalisation. It builds upon 1NF by ensuring that all non-key attributes are fully and functionally dependent on the primary key. This eliminates partial dependencies, ensuring that the entire primary key uniquely determines each attribute in a table. 2NF is instrumental in creating a more robust and logically organised database structure. This minimises data redundancy and enhances overall data integrity.
30) What is 3NF?
The third Normal Form (3NF) is a critical milestone in normalisation. Achieving 3NF involves eliminating transitive dependencies and ensuring that non-key attributes aren’t dependent on other non-key attributes. This level of normalisation minimises data redundancy, enhances data integrity, and paves the way for a well-organised database structure. This fosters efficient Data Management and retrieval in Database Management Systems (DBMS).
Stay at the forefront of database expertise with our GraphQL database Training with React – Join today!
Conclusion
Mastering DBMS Interview Questions is not just about rote memorisation but entails a deep understanding of the underlying principles governing Database Management. The key to success in DBMS interviews lies in combining theoretical knowledge, practical experience, and the ability to think critically. Practice these questions, understand the rationale behind each concept, and stay updated with the latest industry trends. Best of luck with your upcoming interviews!
Learn more about databases with our Introduction to database Training – Sign up today!
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


