



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +1800812339 and speak to our training experts, we may still be able to help with your training requirements.
What is linear Data Structure? A Complete Guide
Sophia Ellis 08 January 2024Explore What is Linear Data Structure' in our latest blog, where we dive into the fundamentals of linear data structures. Learn how they organise data in sequential order, their types like arrays and linked lists, and their practical applications in programming. Perfect for beginners seeking a clear understanding of data organisations and management in computer science!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

A Linear Data Structure is a sequential arrangement of elements with unique predecessors and successors, except for the first and last elements. Linear Data Structures serve as the fundamental building blocks for data organisation. They provide a systematic way to store, manage, and manipulate data in a linear fashion.
This blog will discuss What is Linear Data Structure, exploring its various types, advantages and disadvantages, and use cases. Read more to learn more.
Table of Contents
1) What is Linear Data Structure?
2) Types of Linear Data Structures
a) Array
b) Key components of an Array
c) Advantages and disadvantages of Array
d) Linked Lists
e) Key components of a Linked List
f) Types of Linked Lists
g) Advantages and disadvantages of Linked List
h) Stacks
i) Key features of a Stack
j) Advantages and disadvantages of Stacks
k) Queues
l) Key features of a Queue
m) Advantages and disadvantages of Queues
3) Conclusion
What is Linear Data Structure?
Linear Data Structures form a fundamental category of Data Structures in programming. These structures are characterised by the linear arrangement of data elements, which means that elements are organised sequentially, with each element having a unique predecessor and successor, except for the first and last elements.
Key characteristics of Linear Data Structures
Linear Data Structures exhibit several essential characteristics that set them apart from other Data Structures. These characteristics are crucial for understanding their behaviour and applications:
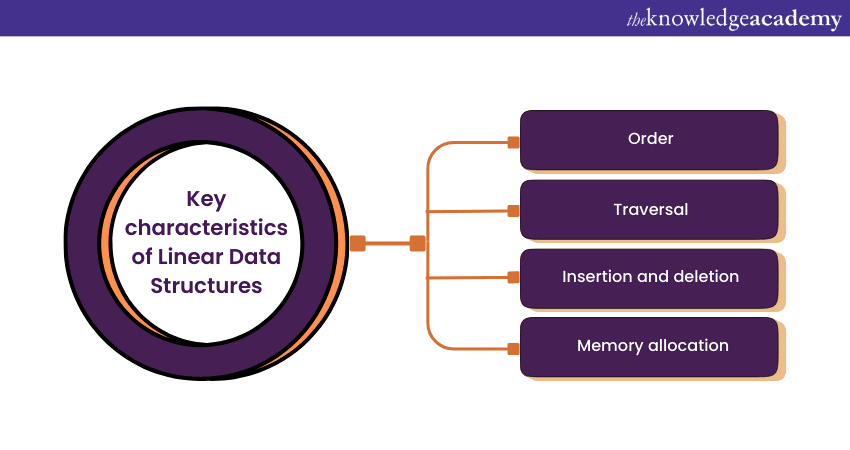
1) Order: Elements in a Linear Data Structure are arranged in a specific and well-defined order. The order could be ascending, descending, or based on insertion order, depending on the type of linear structure.
2) Traversal: One of the fundamental operations with Linear Data Structures is sequential traversal. You can start at the first element and move through the structure one element at a time until you reach the end. This sequential access is particularly useful for processing data in a systematic manner.
3) Insertion and deletion: Linear Data Structures allow for the insertion and deletion of elements at specific positions. These operations can be performed efficiently in most Linear Data Structures, although the exact mechanisms may vary from one type to another.
4) Memory allocation: In Linear Data Structures like Arrays, memory allocation is typically contiguous. This means that elements are stored in adjacent memory locations. Contiguous memory allocation is efficient for direct access but may lead to memory fragmentation if not managed properly.
Common operations on Linear Data Structures
Linear Data Structures support various operations, and understanding how these operations work is crucial for effectively utilising them in software development. Some of the most common operations on Linear Data Structures include:
1) Access: Accessing elements involves retrieving data from a specific position within the Linear Data Structure. To access an element, you typically specify the index or position, and the Data Structure returns the element stored at that location.
2) Insertion: Inserting an element entails adding a new data element at a specific position within the structure. Depending on the type of Linear Data Structure, this operation can be performed at the beginning, end, or anywhere in between.
3) Deletion: Deletion involves removing an element from a specified position within the linear structure. This operation can free up memory or simply reorganise the elements to maintain the linear order.
4) Traversal: Traversal is the process of iterating through all the elements in the Linear Data Structure sequentially. This operation is fundamental for examining or processing the data in a systematic manner.
Learn about essential concepts of Data Structures with Data Structure And Algorithm Training Course
Types of Linear Data Structures
Linear Data Structures are fundamental components in programming, each offering unique features and use cases. In this section, we will delve deeper into the four primary types of Linear Data Structures:
Array
Arrays are a fundamental and versatile Linear Data Structure widely used in programming. An Array is a collection of elements of the same data type, where a unique index or position identifies each element. These Data Structures provide efficient access to elements through indexing, and they are crucial for various applications in software development.
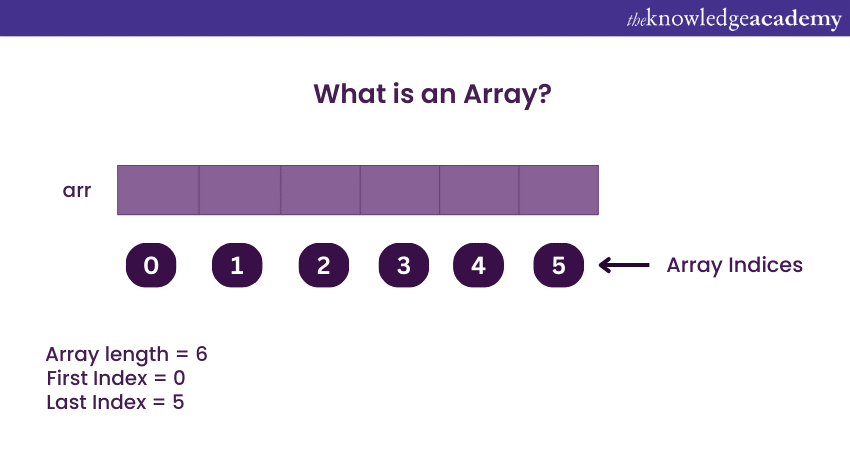
Key components of an Array
An Array consists of several key components:
1) Elements: These are the actual data values stored in the Array. The elements can be of any data type, such as integers, characters, or custom objects.
2) Index: The index is a numeric value that specifies the position of an element within the Array. Indices typically start from 0 (in many programming languages) and increment sequentially.
3) Size: The size of an Array is set. It represents the total number of elements that the Array can hold. Arrays have a specific length that does not change unless explicitly resized.
Advantages and disadvantages of Arrays
Arrays offer several advantages and disadvantages, which determine their suitability for various programming scenarios:
Advantages
1) Fast access: Accessing elements in an Array is extremely fast because it involves direct indexing. Given the index, you can immediately access the desired element.
2) Memory efficiency: Arrays are memory-efficient, as they use contiguous memory allocation. This means elements are stored in adjacent memory locations, reducing memory overhead.
3) Predictable performance: Arrays provide predictable performance for access, insertion, and deletion operations, as these operations are typically performed under a set time.
Disadvantages:
1) Fixed size: The size of an Array is fixed upon creation, which can be a limitation if the number of elements is not known in advance. Attempting to add more elements than the Array's size can lead to overflow or memory allocation errors.
2) Inefficient insertions and deletions: Inserting or deleting elements in an Array can be ineffective because it requires shifting elements to maintain order, which can be a time-consuming process for large Arrays.
3) Wasted memory: Arrays may allocate memory for the maximum size even if you do not use all the available slots. This can result in wasted memory in cases where the Array size is significantly larger than the actual number of elements stored.
Information technology leads the world, and programming skills are more important than ever. Get equipped with our Programming Training Course to learn major programming languages.
Linked Lists
Linked Lists offer a dynamic and flexible way to store and organise collections of data elements. Unlike Arrays that use contiguous memory allocation, Linked Lists use a structure where each element, known as a "node," is connected to the next one through a reference or a pointer.
Key components of a Linked List
A Linked List consists of nodes, and each node contains two primary components:
1) Data: The data can be of any type and represents the actual information stored in the Linked List. For example, in a list of names, the data could be the name itself.
2) Pointer: A reference or pointer that points to the next node in the list. This connection between nodes is what allows the traversal of the Linked List.
Types of Linked Lists
There are several variations of Linked Lists, each with its unique characteristics and use cases:

1) Singly Linked Lists: In a Singly Linked List, each node has a data component and a reference to the next node. This design makes inserting and deleting elements at the end or beginning of the list efficient.
2) Doubly Linked Lists: In a Doubly Linked List, each node has two references—one pointing to the next node and the other to the previous node. This bidirectional connectivity allows for efficient traversal in both directions but requires more memory than Singly Linked Lists.
3) Circular Linked Lists: It is a variation where the last node points back to the first node, forming a closed loop. This circular structure is used in situations where data needs to be continuously cycled.
Advantages and disadvantages of Linked Lists
Linked Lists offer several advantages and disadvantages, which determine their suitability for various programming scenarios:
Advantages:
1) Dynamic sizing: Linked Lists can grow or shrink as needed, making them ideal for managing data whose size is uncertain or can change over time.
2) Efficient insertions and deletions: Adding or removing elements from a Linked List can be done efficiently, especially when the location of insertion or deletion is known.
3) Dynamic memory allocation: Linked Lists allow for dynamic memory allocation as each node can be allocated and deallocated separately.
Disadvantages:
1) Slower access time: Accessing elements in a Linked List can be slower compared to Arrays because you must traverse the list from the beginning to reach a specific component.
2) Increased memory usage: The use of pointers or references in Linked Lists requires additional memory, making them less memory-efficient than Arrays in terms of overhead.
3) Complexity: Managing pointers and references can introduce complexity and make Linked Lists more error-prone compared to Arrays.
Stack
A Stack is a fundamental Linear Data Structure that follows the Last-In, First-Out (LIFO) principle. It is a collection of elements in which new elements are added to the top and removed from the top, much like a Stack of plates where the last plate you put on the Stack is the first one you can take off. Stacks are used in a wide range of applications and are an essential tool for managing data and controlling program flow.
Key features of a Stack
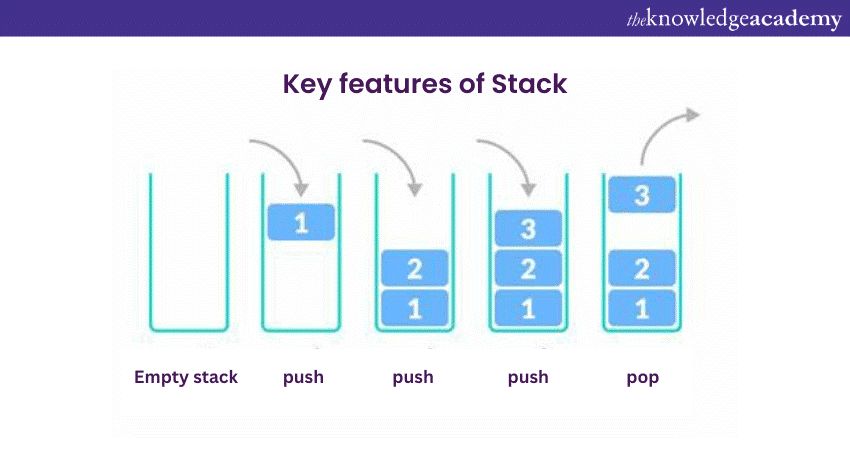
1) Push operation: The operation of adding an element to the top of the Stack is known as "push." This element becomes the new top of the Stack.
2) Pop operation: The operation of removing and returning the element from the top of the Stack is called "pop." After a pop operation, the element below the removed element becomes the new top.
3) Peek operation: The "peek" operation allows you to view the element at the top of the Stack without removing it. This is useful for examining the top element without altering the Stack's structure.
Advantages and disadvantages of Stacks
Stacks are a versatile and important Data Structure that provides specific benefits but also comes with certain limitations. Understanding the advantages and disadvantages of Stacks is essential for making informed decisions when implementing them in your software solutions.
Advantages
1) Last-In, First-Out (LIFO) principle: The LIFO ordering in Stacks is a natural fit for many applications. It ensures that the most recently added item is the first to be removed, making Stacks suitable for managing elements in chronological or reverse chronological order.
2) Efficient push and pop operations: The push and pop operations for Stacks are typically performed in a set time, O(1). This efficiency is crucial for managing data efficiently, especially in scenarios where elements are frequently added or removed from the top of the Stack.
3)Simple implementation: Stacks have a straightforward and intuitive structure. They can be executed using Arrays or Linked Lists, making them relatively easy to understand and use in programming.
Disadvantages
1) Limited access: Stacks are designed for efficient access to the top element. Accessing elements deeper within the Stack requires popping elements until the desired one is reached, which can be inefficient for large Stacks.
2) Fixed size: In many implementations, Stacks have a fixed size determined at the time of creation. Attempting to push elements beyond the Stack's size may result in overflow errors or data loss.
3) Memory management: Stacks can lead to memory management issues if not handled carefully. Failure to pop elements after they are no longer needed can result in memory leakage.
Understand all the primary concepts of D programming languages with our D Programming Language Training and become familiarised with all the functions of D.
Queues
A Queue is a fundamental Linear Data Structure that adheres to the First-In, First-Out (FIFO) principle. In a Queue, elements are added at one end, known as the "rear" or "tail," and removed from the other end, known as the "front" or "head." Queues are commonly used for tasks that require the orderly processing of data, such as scheduling, managing tasks, or handling requests.
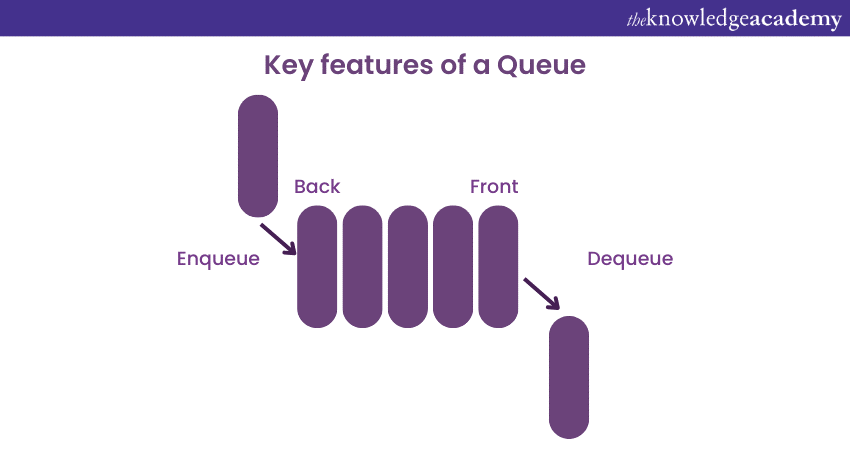
Key features of a Queue
These are the key features of a Queue:
1) EnQueue operation: It is the process of adding an element to the rear of the Queue. The newly added element becomes the last one to be processed.
2) DeQueue operation: The operation of removing and returning the element from the front of the Queue is called "deQueue." After a deQueue operation, the element behind it becomes the next one to be processed.
3) Front and rear: Elements in a Queue are organised linearly, with the front representing the first element to be processed and the rear representing the last.
4) FIFO principle: The FIFO principle ensures that elements are processed in the order they are added, making Queues suitable for managing tasks and requests that need to be handled in a sequential and orderly manner.
Advantages and disadvantages of Queues
Queues are a fundamental Data Structure with specific advantages and disadvantages that make them suitable for particular use cases. Understanding these aspects is crucial for determining when to use Queues in software development.
Advantages
1) Orderly data processing: Queues follow the First-In, First-Out (FIFO) principle, ensuring that elements are processed in the order they were added. This feature is essential for managing tasks or requests in a systematic and orderly manner.
2) Effective task management: Queues are highly effective for managing tasks or processes that need to be executed one after the other, such as print jobs in an operating system or requests in a web server. This ensures that each task is processed fairly and sequentially.
3) Buffering and flow control: Queues are used for buffering data when there is a mismatch in data production and consumption rates. They help smooth out the flow of data, ensuring that no data is lost due to overflow.
Disadvantages
1) Inefficient for random access: Queues are not suitable for scenarios that require random access to elements. Accessing elements beyond the front (head) of the Queue is inefficient because it requires dequeuing multiple items.
2) Memory usage: Queues may consume significant memory when used to buffer data, especially in cases of long Queues. This can become a concern if memory is limited.
3) Blocking: In some applications, if the Queue becomes full, it can block further enqueuing until space becomes available. This blocking behaviour can be problematic in scenarios where continuous data flow is critical.

Conclusion
In programming, it is crucial to have a clear understanding of what Linear Data Structures are. We hope that this blog has provided a complete overview of What is Linear Data Structures, emphasising their significance, characteristics, and real-world applications. By mastering these data structures, you will be better equipped to tackle complex programming challenges, optimise data management, and craft efficient algorithms.
Understand the architecture, data model and installation of Cassandra with Apache Cassandra Training Course and become familiarised with data types and CQL types.
Frequently Asked Questions
Upcoming Programming & DevOps Resources Batches & Dates
Date
 Data Structure and Algorithm Training
Data Structure and Algorithm Training
Data Structure and Algorithm Training
Fri 24th Jan 2025
Data Structure and Algorithm Training
Fri 21st Mar 2025
Data Structure and Algorithm Training
Fri 2nd May 2025
Data Structure and Algorithm Training
Fri 27th Jun 2025
Data Structure and Algorithm Training
Fri 29th Aug 2025
Data Structure and Algorithm Training
Fri 3rd Oct 2025
Data Structure and Algorithm Training
Fri 5th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


