



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +55 8000201623 and speak to our training experts, we may still be able to help with your training requirements.
What is Time Complexity: Its Definition, Types, and Algorithms
Scarlett Adams 21 March 2025Wondering What is Time Complexity? It’s a measure of the time an algorithm takes to run as a function of input size, helping to gauge efficiency. This blog explores key types like constant, linear, and logarithmic time and offers examples to clarify these concepts. Dive in to understand algorithm performance better!
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Picture yourself navigating a vast maze, searching for the quickest exit. Would you rather wander aimlessly or follow a map that leads you out swiftly? This scenario highlights the importance of understanding Time Complexity. But What is Time Complexity? It's a measure that helps us assess the efficiency of algorithms, guiding us to select the most effective solutions.
In this blog, we'll explore What is Time Complexity, diving into its definition, different types, and the algorithms that depend on it. By the end, you'll grasp why Time Complexity is vital and how it influences your code's performance. Ready to enhance your problem-solving abilities? Let's dive in!Table
Table of Contents
1) What is Time Complexity?
2) Significance of Time Complexity
3) Steps to Calculate the Time Complexity
4) Different Types of Time Complexity
5) Time Complexity Analysis of Sorting Algorithms
6) Time Complexity Example
7) What is the Time Complexity of Prim's Algorithm?
8) What is Space Complexity?
9) Conclusion
What is Time Complexity?
Time Complexity is the amount of time that any algorithm takes to function. It is basically the function of the length of the input to the algorithm. Time Complexity measures the total time it takes for each statement of code in an algorithm to be executed.
Although it does not evaluate the execution time of the algorithm, it is intended to provide information related to how execution time changes. This variation generally occurs with the increase or decrease in the number of operations in an algorithm, such as in the Bucket Sort Algorithm where execution time depends on data distribution.
Furthermore, just like any object is typically defined by time and space, an algorithm’s effectiveness can be determined by its Complexity in Space and Time. An algorithm is nothing but an instruction that tells a computer how it should execute a particular application program.
The algorithm’s execution time may differ for various inputs of equal size, and hence, the worst-case Time Complexity could be considered. This is the maximum time necessary for inputs of a fixed size.
For example, consider the problem of making tea. We can follow some key steps to prepare tea as shown below:
1) Step 1: Get a milk pan
2) Step 2: Gather milk, tea leaves, water and sugar.
a) Do we have milk?
i) If yes, add it to the mix of boiling water, tea leaves and sugar.
ii) If not, do we need to purchase milk?
a) If yes, then go to the shop to buy.
b) If no, terminate the process.
c) Step 3: Turn on the stove
The above steps are an example of a simple algorithm to make tea. In addition to following an algorithm, flowcharts can also be followed for executing a process.

Significance of Time Complexity
Computer programming comprises algorithms, each of which is a finite sequence of well-defined instructions. These instructions are executed on a computer for Problem-solving and Decision-making. The computer always requires a fixed set of instructions, which can also contain variations for performing the same task, similar to the many possible ways to Solve a Rubik’s Cube by moving a piece from one position to another.
Furthermore, developers also have a wide range of programming languages to choose from. Each programming language has a distinct structure for writing instructions, combined with the performance boundaries of the selected programming language. It is vital for developers to understand that the Types of Operating Systems (OS), hardware, and processors in use have an influence on the execution of an algorithm.
Moreover, considering how various factors can significantly affect an algorithm’s outcome, developers should be careful to understand how computing systems perform a single task. They can determine this by assessing an algorithm’s space and Time Complexity.
On one hand, the space complexity of an algorithm helps determine the amount of memory or space it needs to operate as a function of its input length. On the other hand, the Time Complexity of the algorithm calculates the total time needed to complete the execution of a function on a specific length of input.
More importantly, an algorithm’s Time Complexity is significantly dependent on the size of the data being processed, and it also helps define the effectiveness of the algorithm. The algorithm’s Time Complexity is mainly an evaluation of its performance.
Steps to Calculate the Time Complexity
Now, you have seen how each function is assigned an order notation and the relationship between the algorithm’s execution time, its number of operations and input data size.
The next step is to understand how you can evaluate an algorithm’s Time Complexity depending on its assigned order notation for each time it executes. The input size of the data to be processed and the run time of the computation for any given ‘n’ elements in the algorithm are also considered.
Here are the various steps that you can follow to evaluate the Time Complexity of an algorithm:
a) Step 1: The algorithm can be defined as a 2-input square matrix with the growth order ‘n’
b) Step 2: The np.random function is applied to select the values of every element in both matrices in a random manner.
c) Step 3: A result matrix is then assigned to the algorithm, with 0 values of growth order equivalent to the order of the input matrix.
d) Step 4: The resultant matrix is converted to a list-type
e) Step 5: Every element in the resultant list is then mathematically summed to derive a final answer
Learn to craft high-performance applications by registering for our D Programming Language Training.
Pseudocode Example
Here is an example of a pseudocode that helps demonstrate the concept of Time Complexity in algorithms. It analyses the algorithm with the Big O notation for growth order. This example demonstrates the operation of finding the maximum value in an array and calculating its Time Complexity:

The above pseudocode contains a data array ‘arr’, and here is how the Time Complexity is analysed to calculate the maximum value in it:
a) The if statement defined before the for loop evaluates if the array is devoid of elements. This operation is considered a constant time growth order, denoted as O (1).
b) The loop then proceeds to do iterations through all the elements in the array, starting from index[0] to [length(arr) - 1]. The worst-case scenario would be if the maximum value was at the last index or the end of the array or not present in the array. In this case, the above loop would run [length(arr) - 1] a number of times. Therefore, this demonstrates that there is a Time Complexity of the growth order O (n), where ‘n’ denotes the array’s length.
c) The variable assignment and the comparison formula in the loop are also called constant time operations, denoted as O (1).
The algorithm’s Time Complexity is always analysed by comparing the number of operations or iterations done in relation to the data input size.
Learn about data declarations and pointer techniques by signing up for C Programming Training now!
Different Types of Time Complexity
Time Complexity is denoted by time as a function of the input’s length. A relationship also exists between the size of the input data, denoted as ‘n’, and the number of operations performed, denoted as ‘N’, in relation to time.
This relationship is commonly referred to as the ‘Order of Growth in Time Complexity’ and is denoted by ‘O[n],’ where ‘O’ symbolises the growth order and ‘n’ represents the input length. ‘O[n]’ is referred to as ‘Big O Notation’, which conveys an algorithm’s runtime and how quickly it grows with respect to the input ‘n.’
A prime example of an algorithm with Time Complexity O(n^2) is the ‘Selection sort’ algorithm. This algorithm is designed to perform an iteration through a list of numbers to ensure that the element at index ‘i’ is the ‘ith’ smallest/largest element in that list.
Furthermore, the Time Complexity notation comes in various forms, which are described as follows:
1) Constant Time Complexity: O (1)
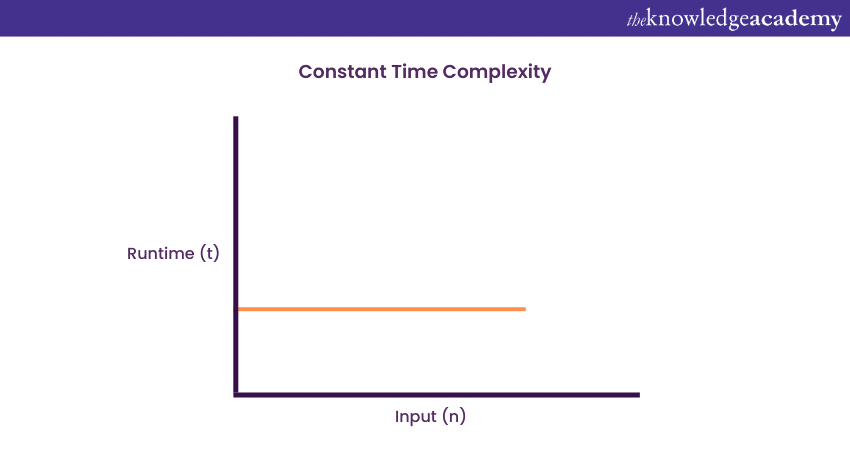
An algorithm will have a constant time with order O (1) if it is independent of the input size ‘n’. Regardless of what the input size ‘n’ is, the execution time will not be affected. The example of the Selection sort algorithm explained above demonstrates that no matter what the array (n) length may be, the final execution time to retrieve the first element in arrays of any length remains the same.
Now, the execution time can be considered as one unit of time, in which case it is only one unit of time’s worth to execute both arrays, regardless of their length. Therefore, the function will be considered under constant time with the growth order of O (1).
2) Linear Time Complexity: O (n)

An algorithm will have a linear Time Complexity in the case when the execution time demonstrates a linear increase with the input’s length. The increase occurs when the function checks all the values in the processed input data, with the order O (n).
In the Selection sort algorithm, the execution time has a linear increase. Now, if the execution time is considered as one unit of time, then it will take [n*(1 unit time)] to execute the array to completion. Therefore, in growth order O (n), the function can be said to run linearly with the input size.
3) Logarithmic Time Complexity: O (log n)
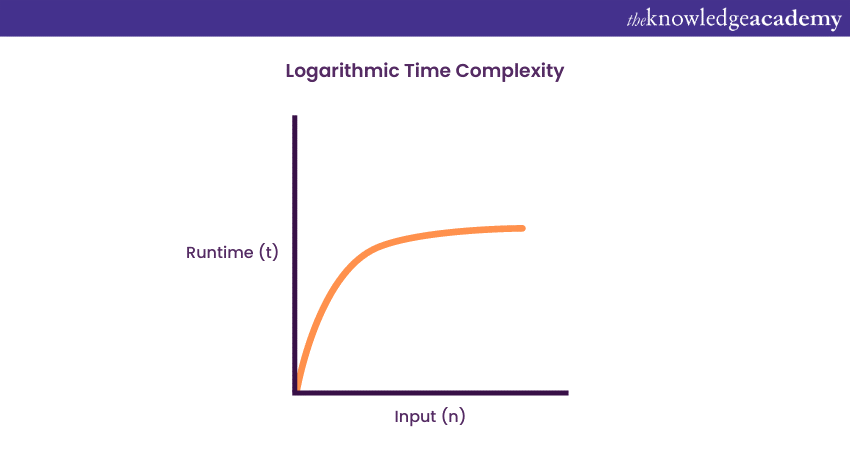
An algorithm will have a logarithmic Time Complexity in the case when the size of the input data is reduced in each step of the algorithm’s execution. The gradual reduction of the data size is an indication that the number of executions is not equal to the data input size; rather, they decrease with the increasing input size.
A good example of logarithmic Time Complexity is a binary search function, also known as a binary tree. Binary search functions involve the search of a given element in an array, followed by segregating the array into two sections. A new search is then performed in each section. The array split ensures that the operation is not performed on all elements in the data array.
4) Quadratic Time Complexity: O (n^2)
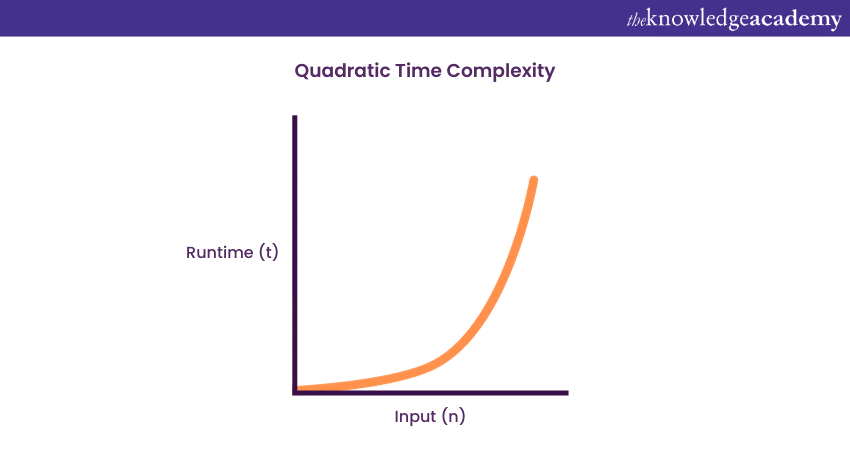
An algorithm will have a non-linear or quadratic Time Complexity in the case when the execution time increases in a non-linear fashion, I.e. (n^2) with the input data’s length. Nested loops are such algorithms that typically come under this growth order where one loop runs with the order O (n). If the algorithm involves a loop inside a loop, then it runs on the growth order of O (n)*O (n) = O (n^2).
Now, if there are ‘m’ number of loops defined in the structure of the function, the growth order is then denoted by O (n^m), which is basically called the ‘polynomial Time Complexity function’. The term means that an algorithm is called a solvable one in polynomial time if the number of steps needed to finish the algorithm for a given input is O (n^2) for a non-negative integer ‘t’, where n denotes the input data’s complexity.
Learn about object-oriented approaches, by signing up for our Object-Oriented Fundamentals Training now!
Time Complexity analysis of various sorting algorithms
The further exploration of the Time Complexity concept in different sorting algorithms helps you choose the optimal algorithm in any given situation. Sorting algorithms basically arrange an array’s elements in an ascending or descending order, resulting in a permutation of the input array. Here is a list describing the various sorting algorithms in detail:
1) Selection sort

The Selection sort algorithm is a mathematical procedure where the lowest value is exchanged with the element in the first index position of the data array. This is followed by the second lowest value being exchanged with the element in the second index position of the array. This process is iterated over the remaining elements until all the elements of the array are sorted.
The Selection sort algorithm has a best-case Time Complexity of O (n^2) and a worst-case Time Complexity of O (1).
2) Merge Sort
The Merge sort algorithm is an example of the ‘Divide and Conquer’ technique. The algorithm divides an array into equal halves and merges them back in a sorted order. The Merge sort is intended to continuously divide an array equally in recursions. Recursion is basically a technique for solving a computational problem, which entails the need to segregate the problem into smaller manageable parts to achieve the solution.
The Merge sort is basically a code written with a recursive function that calls itself within the same code, for solving the sorting problem. The Merge sort algorithm has a best-case Time Complexity of O (nlogn) and a worst-case Time Complexity of O (nlogn).
3) Bubble Sort
The simplest of all sorting algorithms, the Bubble sort, is an algorithm that operates by iteratively swapping the values between two numbers. Also called the ‘Sinking sort’, the algorithm compares each element with the element in the index after it. The worst-case Time Complexity of the Bubble sort is O (n^2), and the best-case Time Complexity is O (n).
4) Quick Sort

The Quick Sort Algorithm is the most well-known sorting algorithm for comparison-based computations. Similar to the Merge sort, this algorithm also functions on the Divide and conquer strategy.
It basically selects an array element as a pivot and partitions the array around the chosen element. The Quick sort algorithm is then applied recursively on the left partition, followed by the right partition. The best-case Time Complexity of the Quick sort is n*log (n), and the worst-case Time Complexity is n^2.
5) Heap Sort
The Heap sort algorithm is among the various comparison-based sorting techniques. Its mechanism is similar to an optimised version of the Selection sort algorithm. It basically partitions the input array into sorted and unsorted sections, followed by iteratively shrinking the unsorted section. The shrink process occurs by removing the largest value from it and shifting it to the sorted section.
However similar it may be to the Selection sort, the Heap sort stands apart by not spending time scanning the unsorted section. More importantly, the Heap sort keeps the unsorted section in a heap data structure, which is a tree-based structure fulfilling the heap property. The best-case Time Complexity of the Quick sort is O (nlogn), and the worst-case Time Complexity is O (nlogn).
6) Bucket Sort
The Bucket sort also called the ‘bin sort’ algorithm, is a sorting technique which distributes an array’s elements into multiple ‘buckets’. Each of these buckets is again sorted individually, either by applying another sorting technique or by recursively implementing the bucket sorting algorithm.
Each of the individual buckets is sorted with the Insertion sort algorithm before being joined together again. This sorting method has an exceptionally fast computational speed owing to the way the values are assigned to each bucket. The best-case Time Complexity for the Bucket sort technique is O (n + k), and the worst-case complexity is O (n ^ 2).
Unlock the secrets to building sleek, and modern websites – register for our Bootstrap Training now!
7) Insertion Sort
The Insertion sort algorithm is a basic technique that sorts an array by computing one element with each iteration cycle. It takes an element and searches for its correct index in the sorted array. This sorting technique is quite akin to arranging a deck of playing cards.
The algorithm is deemed efficient owing to its organisational method on an unordered array of data through comparisons and element insertions based on either the numerical or alphabetical order. The best-case Time Complexity of the Insertion sort is (n), and the worst-case is (n^2).
Time Complexity example
Here is an example that will help you better understand the implementation of Time Complexity in a real-world scenario:
The ride-sharing application Uber, allows users to request a ride, followed by a search by the app to locate the nearest available driver to match their request. The search process by the application is then followed by sorting the located drivers to find the one in closest proximity to the user’s location.
Now, in this situation, there are two key approaches applied with respect to Time Complexity:
1) Linear Search Approach
Linear search is a fundamental approach implemented to locate an element in a dataset. It is designed to assess each element until a match is found. In the context of the application, the same approach is applied by iterating through a list of drivers available in the area, followed by a calculation of the distance between every driver’s and every user’s location.
The application then proceeds to select the driver in closest proximity to the user. It is also important to note that the application’s performance may degrade during peak hours.
2) Spatial Indexing Approach
The Spatial indexing approach is designed to locate elements in a specific region, calculate the closest neighbour or identify intersections between various spatial elements. This is an approach that computes data with more efficiency by utilising data structures such as Quadtrees or KD trees. These spatial indexing structures basically partition spaces into smaller regions, which enables quicker searches based on the spatial proximity of the element or object.
The Time Complexity of the Spatial indexing approach is close to O(log n), which is computationally more efficient than O(n). This approach is better because the search process is guided by the spatial indexing structure, which eliminates the comparison of distances between all located drivers.
Simplify Complex Calculations! Learn Permutation and Combination Step by Step.
What is the Time Complexity of Prim’s Algorithm?
The time complexity of Prim’s Algorithm depends on the data structures used. With an adjacency matrix and a priority queue, it is O(V2)O(V^2)O(V2), where VVV is the number of vertices. Using an adjacency list and a min-heap, it reduces to O((V+E)logV)O((V + E) log V)O((V+E)logV), where EEE is the number of edges.
What is Space Complexity?
Prim’s Algorithm has a space complexity of O(V+E)O(V + E)O(V+E) due to storing the graph representation and additional data structures.
Conclusion
Understanding What is Time Complexity equips you with the tools to optimise your algorithms and enhance your coding efficiency. By mastering its concepts and types, you can tackle complex problems with confidence and precision. Ready to revolutionise your problem-solving approach? Harness the power of time complexity and elevate your coding skills to new heights! For clearer problem visualisation, understanding the differences between Flowchart and Pseudocode can help you choose the right representation for your algorithms.
Learn the major programming languages by signing up for our Programming Training now!
Frequently Asked Questions
What is Time Complexity 1?
Time complexity is a measure of the computational time an algorithm takes to run as a function of its input size. It helps evaluate the efficiency and scalability of algorithms, guiding optimisation decisions.
What is an Example of Complexity?
An example is O(n), where execution time grows linearly with input size. For instance, iterating through a list of size n has O(n) complexity.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 3,000 online courses across 490+ locations in 190+ countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Personal Development Courses, including the Career Development Course, Time Management Training, and Attention Management Training. These courses cater to different skill levels, providing comprehensive insights into Business Relationship Management.
Our Business Skills Blogs cover a range of topics related to Time Complexity, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Business Management skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Business Skills Resources Batches & Dates
Date
 Career Development Course
Career Development Course
Career Development Course
Fri 6th Jun 2025
Career Development Course
Fri 29th Aug 2025
Career Development Course
Fri 24th Oct 2025
Career Development Course
Fri 26th Dec 2025
Career Development Course
Fri 23rd Jan 2026
Career Development Course
Fri 20th Mar 2026
Career Development Course
Fri 15th May 2026
Career Development Course
Fri 17th Jul 2026
Career Development Course
Fri 20th Nov 2026
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


