



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +1 6474932992 and speak to our training experts, we may still be able to help with your training requirements.
Data Preprocessing in Machine Learning: A Complete Overview
Eliza Taylor 05 February 2025Data Preprocessing is a vital step in any Machine Learning project. It is the process of converting the raw data into a format that is appropriate for model training and testing. In this blog, we will explain what Data Preprocessing in Machine Learning is, why it is important, how to perform it, and the best practices to follow.
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.

Machine Learning creates systems to learn from data and make predictions or decisions. Machine Learning models depend on the quality and quantity of the data they are fed. However, real-world data is often messy, incomplete, inconsistent, or irrelevant. It can have an impact on the accuracy and performance of the models. In this blog, we will discuss what Data Preprocessing in Machine Learning is, why it is important, how to perform it, and the best practices to follow.
Table of Contents
1) What is Data Preprocessing in Machine Learning?
2) The importance of Data Preprocessing
3) Data Preprocessing steps in Machine Learning
4) Best practices for Data Preprocessing
5) Conclusion
What is Data Preprocessing in Machine Learning?
Data Preprocessing is the process of generating raw data for Machine Learning models. It is the first step in creating a Machine Learning model. It is the most complex and time-consuming aspect of data science. Data Preprocessing is required in Machine Learning algorithms to reduce their complexities.
Data Preprocessing involves various tasks, such as:
a) Handling missing values
b) Encoding categorical variables
c) Removing outliers
d) Normalising or standardising the data
e) Reducing the dimensionality of the data
f) Splitting the data into training, validation, and test sets

The importance of Data Preprocessing
Data Preprocessing is important for several reasons, such as:
a) Improving the quality and reliability of the data
b) Enhancing the performance and accuracy of the Machine Learning models
c) Reducing the complexity and computation time of the Machine Learning algorithms
d) Avoiding errors and biases in the Data Analysis
e) Facilitating the interpretation and visualisation of the data
Data Preprocessing can make a significant difference in the outcome of a Machine Learning project. It can help us discover useful patterns and insights from the data and avoid misleading or erroneous results.
Shape the future with our Artificial Intelligence & Machine Learning Training – Sign up today!
Data Preprocessing steps in Machine Learning
Data Preprocessing consists of several steps that can be performed sequentially or iteratively, depending on the nature and requirements of the data. Here are some of the common steps involved in Data Preprocessing:
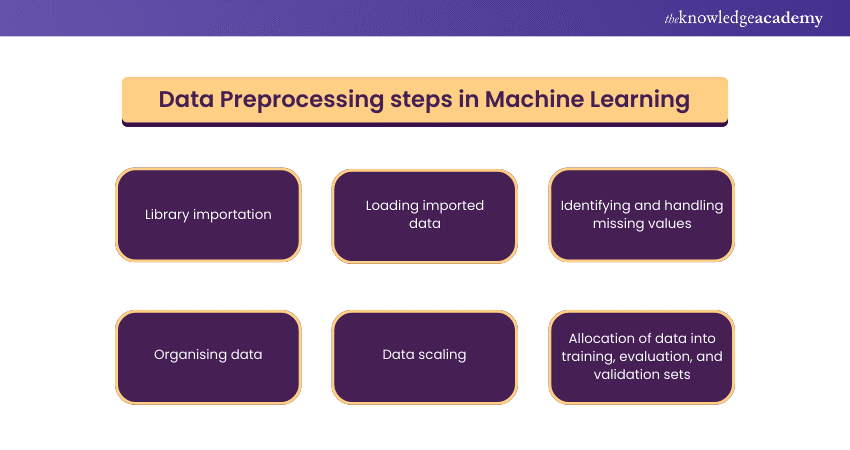
Library importation
The first step in Data Preprocessing is importing the necessary libraries to help us perform various tasks. Some of the commonly used libraries for Data Preprocessing in Python are:
a) Numpy: It is a library that supports mathematical and scientific operations on arrays and matrices.
b) Pandas: It is a library that provides data tools and structure for Data Analysis and manipulation.
c) Scipy: It is a library that offers functions and modules for scientific computing and statistics.
d) Scikit-learn: It is a library that provides Machine Learning algorithms and tools for Data Preprocessing, modelling, and evaluation.
We can import these libraries as follows:
import numpy as np
import pandas as pd
import scipy as sp
from sklearn import preprocessing
Loading imported data
The next step is loading the data we want to preprocess and analyse. The data can be in various formats, such as CSV, Excel, JSON, or HTML. We can use the pandas library to read the data from different sources and store it in a data frame, a tabular data structure that allows easy manipulation and analysis. For example, to read a CSV file, we can use the following code:
df = pd.read_csv('data.csv')
We can also use the ‘head()’ and ‘info()’ methods to glimpse the data and its attributes, such as the number of rows, columns, data types, and missing values.
df.head()
df.info()
Identifying and handling missing values
Missing values are one of the most common problems in real-world data. They can occur due to different reasons, such as human errors, system failures, or incomplete data collection. Missing values can affect the quality and reliability of the data, as well as the performance and accuracy of the Machine Learning models. Therefore, we need to identify and handle the missing values in the data.
There are two different ways to handle missing values:
a) Deleting: This method removes the rows or columns containing missing values. It can be done using the ‘dropna()’ method in pandas. However, this method can result in information loss and reduce the data size.
b) Imputing: This method involves replacing the missing values with appropriate values, such as the mean, median, mode, or constant value. It can be done using the ‘fillna()’ method in pandas, or the ‘SimpleImputer()’ class in scikit-learn. However, this method can introduce noise and bias in the data.
The choice of the method depends on the missing values and the analysis's objective. We can use the ‘isnull()’ and ‘sum()’ methods in pandas to check the number of missing values in each data frame column.
df.isnull().sum()
Organising data
Organising data is arranging the data in a structured and meaningful way. It can help us to understand the data better and perform further analysis. Organising data can involve various tasks, such as:
Renaming the columns: This can help us to give descriptive and consistent names to the columns of the data frame. We can use the ‘rename()’ method in pandas to rename the columns.
a) Reordering the columns: This can help us to arrange the columns in a logical order, such as grouping the related columns together. We can use the ‘reindex()’ method in pandas to reorder the columns.
b) Sorting the rows: This can help us sort the data frame rows based on one or more columns. We can use the ‘sort_values()’ method in pandas to sort the rows.
c) Grouping the rows: This can help us aggregate the data frame rows based on one or more columns. We can use the ‘groupby()’ method in pandas to group the rows and perform various operations, such as sum, count, mean, etc.
For example, to rename the columns of the data frame, we can use the following code:
df = df.rename(columns={'Pregnancies':'preg', 'Glucose':'glu', 'BloodPressure':'bp', 'SkinThickness':'skin', 'Insulin':'ins', 'BMI':'bmi', 'DiabetesPedigreeFunction':'dpf', 'Age':'age', 'Outcome':'out'})
Data scaling
Data scaling is the process of transforming the numerical values of the data into a common range or scale. It can help to reduce the variance and improve the performance of the Machine Learning models. Data scaling can also help to handle the outliers and skewed distributions in the data.
There are two main types of data scaling:
a) Normalisation: This method involves scaling the data values between 0 and 1. It can be done using the ‘MinMaxScaler()’ class in scikit-learn. Normalisation is useful when the data has a fixed range or when we want to preserve the shape of the distribution.
b) Standardisation: This method involves scaling the data values such that they have a mean of 0 and a standard deviation of 1. It can be done using the ‘StandardScaler()’ class in scikit-learn. Standardisation is useful when the data has an unknown range or when we want to reduce the effect of outliers.
The method's choice depends on the data's nature and distribution and the Machine Learning algorithm to be used. We can use the ‘fit_transform()’ method to apply the scaling to the data frame.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
Allocation of data into training, evaluation, and validation sets
The final step in Data Preprocessing is to split the data into training, evaluation, and validation sets. It can help us train, test, and optimise the Machine Learning models. The training set is used to fit the model to the data, the evaluation set is used to measure the model's performance, and the validation set is used to fine-tune the model parameters.
There are different ways to split the data into different sets, such as:
a) Hold-out method: This method involves randomly splitting the data into two or three subsets, such as 70% for training, 15% for evaluation, and 15% for validation. It can be done using the ‘train_test_split()’ function in scikit-learn. However, this method can result in high variance and bias, depending on the size and distribution of the data.
b) K-fold cross-validation method: This method involves dividing the data into k equal folds and then using one fold as the evaluation set and the rest as the training set. This is repeated k times, and the average performance is calculated. It can be done using the ‘KFold()’ class in scikit-learn. k fold cross validation in machine learning can reduce the variance and bias but also increase the computation time and complexity.
The choice of the method depends on the data's size and availability and the analysis's objective.
We can use the split() method to generate the indices or sections for each set and then use them to access the data from the original data frame. For example, to use the k-fold cross-validation method, we can use the following code:
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, test_index in kf.split(df):
train = df.iloc[train_index]
test = df.iloc[test_index]
# perform model training and testing on train and test sets
Unlock the potential of AI with our Introduction to AI Course – Sign up now!
Best practices for Data Preprocessing
Data Preprocessing is not a one-size-fits-all process. It depends on the data's nature and characteristics, the Machine Learning algorithm and the problem to be solved. However, some general guidelines and best practices can help us perform Data Preprocessing effectively and efficiently. Here are some of them:

Data cleaning
Data cleaning is removing or correcting the errors and inconsistencies in the data, such as spelling mistakes, typos, duplicates, or invalid values. Data cleaning can help us improve the quality and accuracy of the data and reduce noise and outliers. Data cleaning can involve various tasks like:
a) Checking the data types and formats of the columns and converting them if necessary
b) Removing or replacing the missing values using appropriate methods
c) Removing or replacing the outliers using appropriate methods
d) Removing or merging the duplicate rows or columns
e) Correcting the spelling or grammatical errors in the data
f) Validating the data against the rules or constraints of the domain
We can use various methods and tools in pandas and scikit-learn to perform data cleaning, such as ‘astype()’, ‘drop_duplicates()’, ‘replace()’, ‘str.replace()’, ‘is_valid()’, etc.
Data reduction
Data reduction involves decreasing the size and complexity of the data while maintaining the important information and features. Data reduction can help us improve the efficiency and performance of Machine Learning models and avoid the curse of dimensionality and overfitting. Data reduction can involve various tasks, such as:
a) Selecting the relevant columns or features that contribute to the target variable or the problem
b) Removing the irrelevant or redundant columns or features that do not add any value or information to the data
c) Combining the related columns or features into new ones that capture the essence of the data
d) Reducing the number of rows or observations by sampling or clustering the data
e) Reducing the number of dimensions or features by applying dimensionality reduction techniques, like Linear Discriminant Analysis (LDA) or Principal Component Analysis (PCA).
We can use various methods and tools in pandas and scikit-learn to perform data reduction, such as ‘drop()’, ‘corr()’, ‘SelectKBest()’, ‘PCA()’, ‘LDA()’, etc.
Data transformation
Data transformation is changing the shape, format, or representation of the data to make it more suitable for Machine Learning models. Data transformation can help us enhance the features and relationships in the data and normalise or standardise the data. Data transformation can involve various tasks, such as:
a) Encoding the categorical variables into numerical values, such as using label encoding or one-hot encoding
b) Applying mathematical or statistical functions to the numerical variables, such as taking the log, square root, or power
c) Applying feature engineering techniques to the data, such as creating new features from existing ones or using domain knowledge or external sources
d) Applying data scaling techniques to the data, such as normalisation or standardisation
We can use various methods and tools in pandas and scikit-learn to perform data transformation, such as ‘map()’, ‘apply()’, ‘LabelEncoder()’, ‘OneHotEncoder()’, ‘MinMaxScaler()’, ‘StandardScaler()’, etc.
Data integration
Data integration combines data from different sources or formats into a single and consistent data set. Data integration can help us enrich and expand the data and increase its diversity and coverage. Data integration can involve different tasks, such as:
a) Merging or joining the data from different tables or files based on common keys or columns
b) Concatenating or appending the data from different tables or files along the rows or columns
c) Reshaping or pivoting the data from wide to long format or vice versa
d) Aligning or matching the data from different sources or formats based on the same attributes or values
We can use various methods and tools in pandas and scikit-learn to perform data integration, such as ‘merge()’, ‘join()’, ‘concat()’, ‘append()’, ‘melt()’, ‘pivot()’, ‘align()’, etc.
Unleash the power of Machine Learning with our Machine Learning Course – Sign up today!
Conclusion
Data Preprocessing is an important step in any Machine Learning project. It involves transforming the raw data into a suitable model training and testing format. Data Preprocessing in Machine Learning can improve the quality and reliability of the data and the accuracy and performance of the Machine Learning models.
Frequently Asked Questions
What are the steps of Data Preprocessing?
The steps of Data Preprocessing are:
a) Library importation
b) Data loading
c) Missing value handling
d) Data organisation
e) Data scaling
f) Data splitting
Why is Data Preprocessing important?
Data Preprocessing is important because it can improve the data's quality and reliability and the performance and accuracy of the Machine Learning models. Data Preprocessing can also help avoid errors and biases in Data Analysis.
What are the other resources and offers provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 3,000 online courses across 490+ locations in 190+ countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is Knowledge Pass, and how does it work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are related Artificial Intelligence & Machine Learning courses and blogs provided by The Knowledge Academy?
The Knowledge Academy offers various Artificial Intelligence & Machine Learning, including Artificial Intelligence, Machine Learning and Deep Learning Courses. These courses cater to different skill levels, providing comprehensive insights into Machine Learning.
Our Data, Analytics & AI blogs cover a range of topics related to Database, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your AI and ML skills, The Knowledge Academy's diverse courses and informative blogs have you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Machine Learning Course
Machine Learning Course
Machine Learning Course
Fri 4th Apr 2025
Machine Learning Course
Fri 6th Jun 2025
Machine Learning Course
Fri 29th Aug 2025
Machine Learning Course
Fri 24th Oct 2025
Machine Learning Course
Fri 26th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


