



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +41 315281584 and speak to our training experts, we may still be able to help with your training requirements.
Different Types of Keys in SQL
Sienna Roberts 09 April 2025Get ready to dive into the intricate world of SQL keys with our comprehensive overview of "Types of Keys in SQL." Explore the primary key, unique key, foreign key, composite key, candidate key, alternate key, and super key, gaining a deep understanding of each type. By the end, you'll have a well-rounded knowledge of the role these keys play in database management.
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.

If you are entering the domain of SQL for the first time, you will see that there are a lot of emphasis that is put on Keys in SQL. But what are these Keys? These Keys are fundamental elements which helps to identify records in a table, establish relationships between these tables and make sure that the data maintains its integrity.
If you want to learn more about these Keys, this blog will help you understand the types of Keys in SQL,the unique features that make these Keys different from each other, how they are used to connect tables in a database. Learn more!
Table of Contents
1) Introduction to Keys in SQL
2) Primary Key
3) Unique Key
4) Foreign Key
5) Composite Key
6) Candidate Key
7) Alternate Key
8) Super Key
9) Difference between different Keys in SQL
10) Conclusion
Introduction to Keys in SQL
Think of keys as the digital counterparts of physical keys – they unlock access to specific information within a database. Just as a key is unique to a lock, a database key is unique to a record or a set of documents, providing a way to identify and differentiate data entries. The PostgreSQL Performance Tuning Guide explains that SQL, the Structured Query Language, offers various types of keys, each with a distinct purpose and significance.To gain deeper insights into SQL and how it compares to other databases like Oracle, explore the Difference Between Oracle and SQL Database.
They facilitate efficient data retrieval, ensure data integrity, and establish relationships between tables. With these Keys, SQL databases would resemble unorganised collections of data, making it easier to manage and query effectively.
SQL offers several types of Keys, each serving a distinct purpose in the database ecosystem:
1) Primary Key: It is an identifier for each record in a table. It ensures data uniqueness and serves as a reference for establishing relationships.
2) Unique Key: Similar to a Primary Key, a Unique Key enforces uniqueness but allows null values. It is used for columns that need to remain unique but may contain missing data. The difference between Microsoft SQL Server and Azure SQL in handling Unique Keys typically revolves around performance optimisations and deployment options.
3) Foreign Key: A Foreign Key establishes a link between two tables based on a standard column. It maintains referential integrity and enforces relationships between tables.
4) Composite Key: A Composite Key uses multiple columns to create a unique identifier. It's useful when a single column cannot ensure uniqueness.
5) Candidate Key: Candidate Keys are potential options for Primary Keys. They share the properties of uniqueness and minimal redundancy.
6) Alternate Key: An Alternate Key is a candidate key that isn't chosen as the Primary Key. It provides additional options for uniquely identifying records.
7) Super Key: It is a set of attributes that, taken together, uniquely identify records. It can include more details than necessary for a primary key.

Primary Key
The Primary Key is like the DNA of a record – a unique identifier that distinguishes each entry within a table. This key ensures that no two forms share the same value, maintaining data integrity and enabling effective data management.
It is the gold standard for identifying and differentiating records within a table. Just as each person has a unique fingerprint, each record has a unique primary key.
Creating it in SQL involves assigning one or more columns as the Primary Key while creating a table. The syntax for creating it varies slightly between Database Management Systems (DBMS), but the underlying principle remains consistent.
By enforcing uniqueness, the primary vital guarantees that no two records in the table are identical. This prevents duplication and maintains the accuracy of the stored information. Data integrity means the accuracy and consistency of data. A Primary Key is preserving data integrity by preventing unauthorised modifications or deletions.
In a relational database, tables often relate to one another through common attributes. The Primary Key of a table becomes a Foreign Key in another table, establishing connections between data sets.
Since these Keys are inherently indexed in most DBMS, they significantly improve query performance. Searching for a specific record becomes much faster due to the indexed nature of primary keys.
The process of organizing data to minimize redundancy is known as normalization. Create a Primary Key in SQL, as its uniqueness enables proper normalization, effectively reducing data duplication and enhancing overall database efficiency.
When updates or deletions occur, it ensures that the changes are applied to the correct record, preventing unintended alterations. The use of a Primary Key and Foreign Key relationship guarantees that the correct references are maintained, preserving data integrity. It also provides a reliable way to access documents directly, which is crucial for applications that require efficient data retrieval.
Unique Key
The Unique Key, is a versatile SQL feature that bestows the power of distinctiveness upon specific columns or combinations of columns within a table. Unlike the Primary Key, which mandates uniqueness and non-null values, it is more lenient, allowing for a single null entry while enforcing identity across the rest of the columns or columns, similar to how the Single Entry System maintains simplicity while tracking financial transactions.
It also serves as a vigilant sentinel guarding against inadvertent duplicates. It's a tool that, when wielded thoughtfully, enhances data integrity by preventing the emergence of redundant entries. Consider it maintaining order and precision within a table, mainly when null values are possible.
Unique Keys are the solution to ensure that specific attributes within a table remain distinct but are open to a potential null entry. Imagine a scenario where a database tracks customer information.
While most customers provide email addresses, some might still need to. Here, a Unique Key could be applied to the email column, allowing null values to be present while maintaining the uniqueness requirement for non-null entries. Similarly, when preparing for interviews, consider asking Unique Interview Questions to gain deeper insights into candidates.
Elevate your data career with our SQL courses! Gain practical skills, hands-on experience, & certifications that make a difference.
Foreign Key
Unlike other Keys primarily focusing on uniqueness, the Foreign Key focuses on relationships. It forms the bridges that link information across tables, enabling a database to reflect real-world interactions and associations.
One of the remarkable features of these Keys are their ability to define cascading actions. These actions determine what happens to related records when a change occurs in the referenced table.
For instance, with a ‘Cascade delete action’, deleting a customer record could automatically trigger the deletion of all associated order records. This ripple effect ensures data remains coherent and relevant, even in the face of modifications.
Composite Key
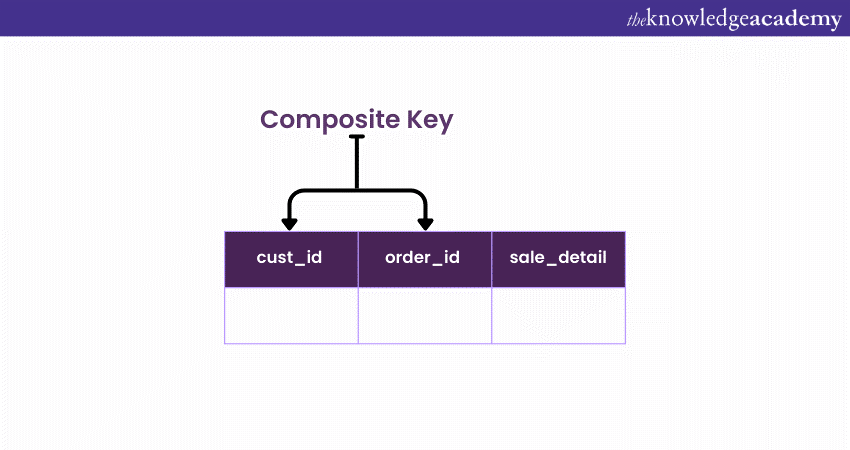
Unlike single-column Keys that hinge on a solitary attribute, a Composite Key is a harmonious combination of multiple columns. This amalgamation creates a unique identifier that collectively distinguishes records within a table.
Each product is uniquely identified not just by a single attribute but by combining its manufacturer ID and its product ID. More than the manufacturer or product ID alone would be necessary to ensure absolute distinctiveness. It's the composite of both these IDs that guarantees uniqueness.
Creating a Composite Key involves defining multiple columns as the primary or unique. This intertwining of attributes forms a robust identifier that prevents identical combinations from surfacing.
Composite Keys handle intricate scenarios where a single attribute can't guarantee uniqueness. These represent the natural world in designs where identity involves various elements.
Candidate Key
Just as multiple paths can lead to a destination, various attributes or combinations can act as unique identifiers for records within a table. The challenge is in identifying the most appropriate candidate key in DBMS that ensures data uniqueness while minimising redundancy.
It embodies the essence of uniqueness. It's a set of attributes that, taken together, can distinguish each record from the others. Identifying Candidate Keys involves exploring different features or combinations and seeking the ones that preserve data integrity and precision.
These are foundational to effective database design. They provide the bedrock upon which unique identification is built. By exploring different attributes and combinations, database architects comprehensively understand the dataset's structure and the relationships between its components.
Candidate Keys are foundational to effective database design. They provide the bedrock upon which unique identification is built. By exploring different attributes and combinations, database architects comprehensively understand the dataset's structure and the relationships between its components.
Looking to improve your SQL skills? Explore more SQL Projects and start practicing!
Alternate Key
Unlike the Primary Key, which stands as the direct reference, or a Unique Key that enforces distinctiveness with leniency towards null values, the Alternate Key is a contender for the primary identifier. It's a Candidate Key that isn't chosen as the Primary Key but still holds the power to identify records uniquely.
It maintains data integrity by providing a backup option for uniquely identifying records. While the Primary Key is the direct path to distinctiveness, the Alternate Key is a secondary assurance. This secondary assurance becomes crucial when dealing with scenarios where the primary key might not be feasible due to complexity, length, or other considerations.
Consider a situation where you manage a database of employees. The Primary Key is an employee ID. Still, due to system limitations or user preferences, you should also ensure that each employee is uniquely identified by their email address. The email address becomes an alternate key – a secondary avenue to data uniqueness.
The beauty of the Alternate Key lies in its flexibility. It caters to scenarios where different parts of the database's user base or application require unique identification using other attributes. This flexibility supports diverse use cases and ensures the database remains adaptable to varying requirements.
Level Up Your SQL Game – Learn How to Create Temp Tables in SQL Easily!
Super Key
Where records strive for individuality, the Super Key emerges as a versatile concept that extends beyond the boundaries of conventional keys. It encapsulates a set of attributes – a combination of columns – that, taken together, ensure the uniqueness of each record within a table.
Unlike other Keys that serve as specific identifiers, a Super Key embodies a broader scope, enveloping various attributes in its aura of distinctiveness.
Every Primary Key is a Super Key, but not every Super Key is a Primary one. While a Primary Key is a specific Super Key chosen as the main identifier, it extends its influence beyond uniqueness. This hierarchy offers a holistic view of data uniqueness, allowing for different levels of granularity when identifying records.
One of the intriguing aspects of it is its relationship to the concept of closure. Closure refers to including additional attributes to a Super Key without compromising uniqueness. This property provides insight into how details can create layers of specificity while maintaining a core of distinctiveness.
It could involve a combination of course ID, instructor ID, and semester ID. This Super Key ensures that each course a specific instructor offers in a particular semester remains unique. However, extending thisKey to include the department ID allows you to create a more specific Super Key that still upholds uniqueness.
Unlock faster performance with PostgreSQL Query Optimization tips—download the PDF now!
Difference between different Keys in SQL
To help you understand more about these Keys, let’s have a look at some of these differences:
|
Key type |
Purpose |
Characteristics |
|
Primary Key |
Used to uniquely identify a row in a table |
Cannot be NULL, and must be unique one per table |
|
Foreign Key |
Used to maintain referential integrity between tables |
t can be NULL |
|
Composite Key |
Used to uniquely identify a row when a single column is not sufficient |
It is a combination of colum, however, they must be uniqueness |
|
Unique Key |
Used to prevent duplicate values in a column |
It can be NULL |
|
Candidate Key |
Used to identify potential Primary Keys |
It can be unique and can uniquely identify each row in a table |
|
Super Key |
Used to uniquely identify rows in a broad sense |
It can contain additional columns which are not unique |
Maximize your database skills—download the free MySQL Cheat Sheet today!
Conclusion
From the steadfast Primary Key to the flexible Alternate Key, each type holds a distinct note, harmonising data integrity and efficient queries. For a deeper understanding, exploring resources like the PostgreSQL Architecture PDF can provide valuable insights into advanced database structures. Like Candidate Keys and Super Keys, this blog has unveiled the intricate threads that compose a well-designed database. The Keys in SQL are the linchpins that ensure data's melody remains harmonious and reliable, elevating data management to an art form. When examining SQL vs MySQL, it’s important to recognize that while both use these keys, MySQL may have specific optimizations or implementations that influence how they are managed and utilized within a database.
Master SQL concepts and secure your dream role with essential SQL Interview Questions!
Frequently Asked Questions
What is Candidate Key in SQL?
The SQL Cheat Sheet defines a Candidate Key as a composition of a group of multiple keys or a single key that can uniquely identify rows in a table. It is also a column or combination of columns which can uniquely identify each row in a table.
Why Keys are necessary for DBMS?
Keys are necessary for DBMS as they are required for defining the constraints in a database. To identify the records that are present in various events for any relation, these Keys are required to identify them uniquely and separately.
What are the 6 types of Keys in SQL?
The 6 types of Keys in SQL are:
a) Super Key
b) Candidate Key
c) Primary Key
d) Alternate Key
e) Composite Key
f) Unique Key
What are the differences between Primary Key and Candidate Key in SQL?
Let’s have a look at this table to know the differences between Primary Key and Candidate Key in SQL
|
Feature |
Primary Key |
Candidate Key |
|
Definition |
It is a Unique Key that uniquely identifies each row in a table |
Any column or set of columns which can identify rows in a table |
|
Uniqueness |
This Key is unique across all rows in a table |
There can be multiple Candidate Keys in a table |
|
Null value |
Cannot contain NULL value |
Can contain NULL value |
|
Role in table design |
It is chosen as the main means of identifying records |
It is considered as potential primary Key |
What are the other resources provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 3,000 online courses across 490+ locations in 190+ countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
Upcoming Programming & DevOps Resources Batches & Dates
Date
 Introduction to SQL
Introduction to SQL
Introduction to SQL
Mon 12th May 2025
Introduction to SQL
Mon 9th Jun 2025
Introduction to SQL
Mon 14th Jul 2025
Introduction to SQL
Mon 8th Sep 2025
Introduction to SQL
Mon 10th Nov 2025
Introduction to SQL
Mon 8th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


