



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on + 1-866 272 8822 and speak to our training experts, we may still be able to help with your training requirements.
What is Data Cleaning? A Complete Breakdown
Sophia Ellis 04 January 2024Explore the essential process of Data Cleaning and its significance in data preparation. This blog covers Data Cleaning techniques, challenges, and best practices, ensuring that your data is accurate, reliable, and ready for analysis.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Data Cleaning is the first and fundamental step in the data preparation journey, crucial for unlocking the true potential of data in various fields. It involves identifying and rectifying errors, inconsistencies, and inaccuracies within datasets, ensuring data accuracy, reliability, and quality.
Moreover, without proper Data Cleaning, the insights derived from data can be skewed, leading to misguided decisions. Data Cleaning is the bedrock of Data Analysis, and it's the process of meticulously identifying and correcting errors and inconsistencies in datasets, ultimately enhancing data integrity and reliability.
In this blog, you will learn about how Data Cleaning refers to identifying, correcting, or removing errors, inconsistencies, and inaccuracies in datasets to improve their quality and reliability.
Table of Contents
1) Understanding What is Data Cleaning
2) Importance of Data Cleaning in Data Science
3) Key steps of the Data Cleaning process
4) Exploring the various Data Cleaning tools
5) Example of Data Cleaning
6) Advantages of Data Cleaning
7) Conclusion
Understanding What is Data Cleaning
Data Cleaning, often referred to as data cleansing or data scrubbing, is a fundamental process in the field of data management and analysis. It involves the systematic identification and correction of errors, inconsistencies, and inaccuracies within a dataset to ensure its accuracy, reliability, and consistency.
This crucial step is necessary because data collected from various sources or through different methods often contains imperfections such as missing values, duplicates, outliers, and formatting discrepancies.
Moreover, these errors can result from human mistakes, system glitches, or data integration issues. Data Cleaning aims to rectify these issues, making the dataset more suitable for analysis, reporting, and decision-making.
Data Cleaning methods include:
a) Handling missing data
b) Detecting and addressing outliers
c) Deduplicating records
d) Standardising formats
e) Validating data against predefined criteria
The ultimate goal is to transform raw, unrefined data into a clean, coherent, and trustworthy dataset, which forms the foundation for meaningful and accurate insights, ensuring that data-driven decisions and analyses are based on high-quality information.

Key steps of the Data Cleaning process
Data is the lifeblood of decision-making in the modern world, but it's not always pristine. In fact, raw data often arrives with errors, inconsistencies, and various issues that can hinder accurate analysis and decision-making.
Now, to address these challenges, Data Cleaning is an essential step in the data preparation process. It involves a series of key steps aimed at transforming raw data into a clean, structured, and reliable dataset. Here are the eight key steps that make up the Data Cleaning process:
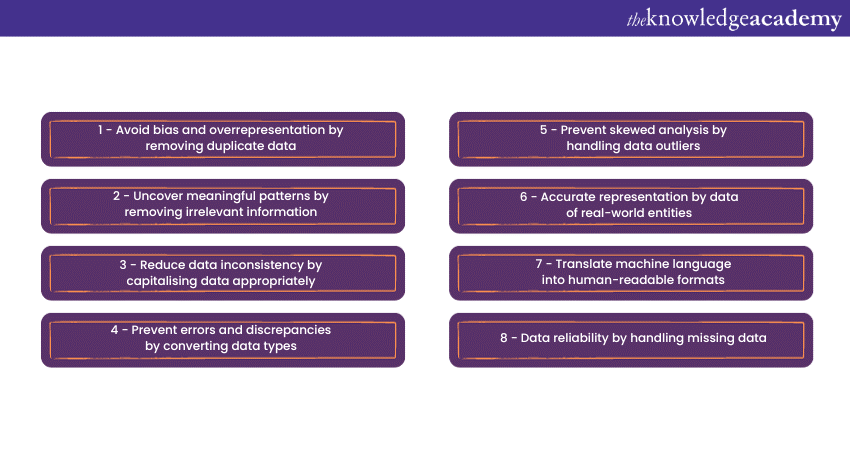
1) Remove duplicate records
Duplicates are a common issue in datasets. They can arise from various sources, such as data entry errors or the merging of multiple data sources. Duplicate records can lead to skewed analysis and incorrect results.
To tackle this issue, Data Cleaning involves identifying and removing duplicate records. This process ensures that each data point is counted only once, preventing overrepresentation and bias in the dataset.
Moreover, duplicates can be identified by comparing records for similarities and eliminating redundant entries. This step is crucial for maintaining data integrity and preventing inaccuracies in analysis.
2) Eliminate irrelevant information
Raw data often contains extraneous or irrelevant information that doesn't contribute to the analysis. Removing such data is a vital step in Data Cleaning. Irrelevant information can be noise that obscures meaningful patterns or trends in the dataset.
For example, in a customer database, irrelevant information might include outdated records, discontinued products, or entries with no associated value. Data Cleaning involves carefully curating the dataset to exclude irrelevant information and streamlining it for more accurate analysis.
3) Standardise data capitalisation
Inconsistencies in data capitalisation can lead to errors in analysis, especially when dealing with text data. For example, "New York" and "new york" might be treated as distinct entities in text analysis, even though they refer to the same location.
Furthermore, Data Cleaning addresses this issue by standardising data capitalisation. This involves converting all text to a uniform format, such as title case or uppercase, ensuring that similar text entries are treated consistently in analysis. Standardisation enhances data consistency, making it easier to identify relationships and patterns in the dataset.
4) Conversion of data types
Datasets often contain data in various formats, including text, numbers, dates, and more. To ensure accurate analysis and calculations, Data Cleaning involves converting data types to their appropriate formats.
For example, dates can be standardised to a common format, and text data can be transformed into numerical values when necessary. Converting data types ensures that the dataset is compatible with the analysis tools and methods used, preventing errors and discrepancies that can arise from incompatible data types.
5) Handling data outliers
Outliers are data points that deviate significantly from the majority of the dataset. These anomalies can skew analysis and produce misleading results. Data Cleaning addresses this issue by handling data outliers.
This involves identifying outliers using statistical methods or domain knowledge and then deciding how to treat them. Depending on the context, outliers can be removed, transformed, or flagged for special attention. Handling data outliers is critical to ensure that the analysis reflects the underlying patterns and trends in the data.
6) Rectify errors in data
Data errors can take various forms, including typographical errors, incorrect data values, or inconsistencies. Data Cleaning aims to rectify these errors to enhance data quality. Rectification may involve correcting misspelt names, adjusting data values that fall outside defined ranges, or resolving inconsistencies between related data fields. By addressing errors, Data Cleaning ensures that the dataset accurately represents the real-world entities and relationships it seeks to describe.
7) Translate machine language
In some cases, Data Cleaning may involve translating machine-generated data or data encoded in specific formats into a human-readable format. For instance, sensor data from IoT devices may be collected in a machine-readable format, which can be challenging for humans to interpret.
Furthermore, Data Cleaning may include the transformation of this data into a human-readable format, making it accessible for analysis and decision-making. This step is essential in scenarios where data needs to be understood and integrated into existing systems or processes.
8) Handle missing data values
Missing data is a common issue in datasets and can occur for various reasons, such as incomplete data collection, data entry errors, or data loss during transmission. Handling missing data is a critical step in Data Cleaning.
Furthermore, there are various techniques for addressing missing data, including imputation, which involves estimating missing values based on available data, and deletion, where incomplete records are removed.
Moreover, the choice of method depends on the nature of the data and the impact of missing values on the analysis. Proper handling of missing data ensures that the dataset remains robust and reliable for analysis.
Verify and validate collected data by signing up for our Data Analysis Training using MS Excel now!
Exploring the various Data Cleaning tools
Data Cleaning tools are essential for ensuring data quality and accuracy in various fields, from business analytics to scientific research. These tools help streamline the process of identifying and rectifying errors, inconsistencies, and other data quality issues.
Here, here are the four categories of Data Cleaning tools, namely Microsoft Excel, programming languages, data visualisations, and proprietary software, explained as follows:
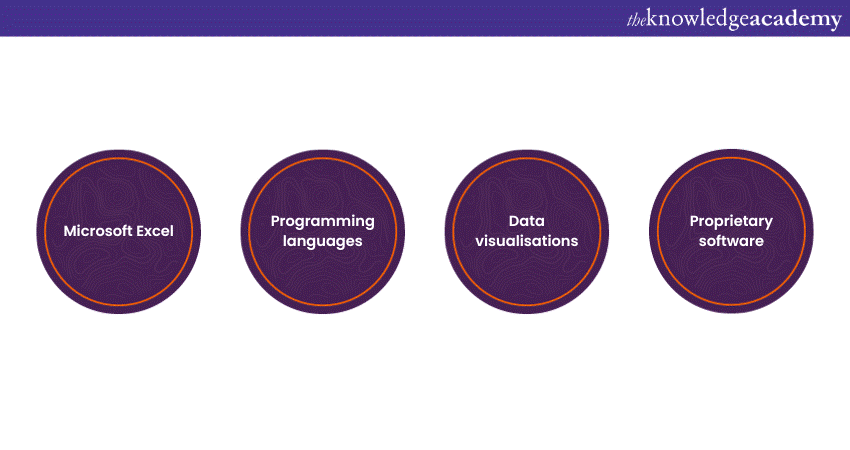
Microsoft Excel
Microsoft Excel is one of the most widely used tools for Data Cleaning and manipulation. Its user-friendly interface allows individuals without extensive programming skills to perform basic Data Cleaning tasks. While Excel is suitable for small to moderately-sized datasets, it may not be the best choice for large datasets or complex Data Cleaning tasks.
Excel offers various features that facilitate Data Cleaning, including:
a) Data sorting and filtering: Excel allows you to sort and filter data to identify duplicates and outliers.
b) Formula and functions: Functions like IF, VLOOKUP, and CONCATENATE enable data transformation and validation.
c) Conditional formatting: You can highlight data that meets specific criteria to spot inconsistencies quickly.
Analyse, sort, report and store data by signing up for our Microsoft Excel Masterclass now!
Programming languages
Programming languages like Python, R, and SQL are powerful tools for Data Cleaning, particularly when dealing with large and complex datasets. Programming languages are highly flexible and can handle diverse Data Cleaning tasks.
They are particularly useful when you need to automate repetitive Data Cleaning processes or work with large datasets. These languages provide extensive libraries and packages designed for data manipulation and cleaning:
a) Python: Libraries such as Pandas and NumPy offer robust Data Cleaning capabilities. Python is widely used for cleaning, transforming, and analysing data.
b) R: R's data manipulation packages, like dplyr and tidyr, are excellent for cleaning and reshaping data.
c) SQL: SQL can be used to query, filter, and aggregate data, making it valuable for Data Cleaning within databases.
Data visualisations
Data visualisation tools, while primarily known for creating charts and graphs, can also aid in Data Cleaning by providing a visual representation of data. While these tools don't perform the actual Data Cleaning, they assist in the data quality assessment process by offering a visual perspective on your data.
Tools like Tableau, Power BI, and QlikView allow you to:
a) Spot data anomalies: Visualisations can help identify outliers and inconsistencies in data.
b) Explore data patterns: Patterns in data can be more apparent when visualised.
c) Data validation: Dashboards can be designed to highlight data quality issues.
Proprietary software
Several proprietary Data Cleaning software tools are specifically designed to automate and streamline Data Cleaning processes. Proprietary software is ideal for organisations that require dedicated Data Cleaning solutions and are willing to invest in specialised tools. They often offer user-friendly interfaces, making them accessible to a broader range of users.
These tools, such as Trifacta and OpenRefine, offer a range of features:
a) Automated data profiling: These tools automatically profile data to identify common data quality issues.
b) Data transformation and wrangling: They provide user-friendly interfaces for cleaning and transforming data.
c) Visualisation: Many proprietary tools offer data visualisation capabilities to assist in data quality assessment.
Example of Data Cleaning
One illustrative example of Data Cleaning in Data Science is in the context of customer data for an E-Commerce company. Suppose a large e-commerce platform is collecting data on customer transactions.
Furthermore, Data cleaning in this scenario involves identifying and resolving these issues. Duplicates are removed, missing data is imputed or flagged, inconsistent formats are standardised, and outliers are either treated or closely examined for fraud detection.
Once the data is cleaned, it becomes a reliable foundation for accurate customer segmentation, personalised marketing, and data-driven decision-making, ultimately improving the e-commerce company's performance and customer experience.
This example highlights the critical role of data cleaning in ensuring the accuracy and reliability of data used in data science applications. Over time, this data accumulates from various sources, including online orders, in-store purchases, and customer support interactions.
As the data grows, it becomes increasingly complex and may contain various issues that need cleaning:
a) Duplicate entries: Due to multiple channels of data entry, there might be duplicate customer records, leading to an inaccurate count of unique customers.
b) Missing values: Some customer records might have missing information, such as email addresses or contact numbers, making it challenging to reach out to customers for promotions or support.
c) Inconsistent formats: Customer names, addresses, and other details might be inconsistently formatted, causing problems in data analysis and reporting.
d) Outliers: Unusual transactions, like unusually large purchases or returns, can distort data analysis results, potentially leading to incorrect insights or predictions.
Uncover actionable insights from datasets by signing up for our Data Analysis Skills Course now!
Advantages of Data Cleaning
Data Cleaning is a fundamental process in Data Management and analysis, and it offers a multitude of advantages that can significantly impact the accuracy, efficiency, and cost-effectiveness of various operations.
The five key advantages of Data Cleaning are described as follows:
Avoiding mistakes
Data errors can have far-reaching consequences, from misguided business decisions to regulatory non-compliance. Data Cleaning plays a pivotal role in avoiding costly mistakes. By identifying and rectifying errors, inconsistencies, and inaccuracies in data, organisations can ensure that the information they rely on is accurate and trustworthy.
For example, in the healthcare industry, Data Cleaning can help prevent life-threatening medical errors by ensuring patient records are correct and up-to-date. Avoiding mistakes through Data Cleaning is a proactive measure that enhances the quality and reliability of data-driven decisions.
Improving productivity
Manual data correction and validation are time-consuming tasks that can slow down operations. Data Cleaning tools and processes significantly improve productivity by automating repetitive and error-prone tasks.
These tools can quickly identify duplicates, outliers, and missing data, streamlining the cleaning process and saving valuable time. With improved productivity, organisations can focus their resources on more value-added activities, such as data analysis and strategy development, instead of being bogged down by Data Cleaning tasks.
Avoiding unnecessary costs and errors
Data errors often lead to financial losses, compliance violations, and wasted resources. For instance, incorrect customer data can result in failed marketing campaigns, wasted advertising budgets, and lost sales opportunities.
By avoiding data errors through cleaning, organisations can prevent these unnecessary costs. Furthermore, Data Cleaning helps companies maintain compliance with data protection regulations, reducing the risk of costly fines and legal complications. The investment in Data Cleaning is, therefore, a cost-saving measure in the long run.
Staying organised
A cluttered and inconsistent dataset can be a nightmare to work with. Data Cleaning promotes organisation by standardising data formats and removing irrelevant information. This organised data is easier to manage, query, and analyse.
Clean data also makes it easier to establish relationships between different data points, fostering a more comprehensive understanding of the information. In addition, staying organised through Data Cleaning ensures that the right data is accessible when needed, reducing the time wasted searching for information.
Improved mapping
Data Cleaning is critical for ensuring that data is correctly mapped and aligned. Data often comes from various sources, and without proper cleaning, it may not be harmonised correctly. Inaccurate mapping can result in incorrect data associations, making it difficult to create meaningful insights.
Clean data ensures that mapping is accurate, improving the quality and relevance of analysis and reporting. For example, in Geographic Information Systems (GIS), Data Cleaning is essential to ensure that spatial data is correctly aligned, enabling accurate maps and spatial analyses.
Attain the expertise to extract meaningful data insights by signing up for our Data Science Training now!
Conclusion
In conclusion, Data Cleaning is the unsung hero of data science, ensuring accurate, reliable, and actionable insights. By addressing errors and inconsistencies, it paves the way for informed decision-making, helping organisations harness the full potential of their data.
Frequently Asked Questions
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Python Data Science Course
Python Data Science Course
Python Data Science Course
Mon 16th Dec 2024
Python Data Science Course
Mon 6th Jan 2025
Python Data Science Course
Mon 17th Mar 2025
Python Data Science Course
Mon 26th May 2025
Python Data Science Course
Mon 14th Jul 2025
Python Data Science Course
Mon 22nd Sep 2025
Python Data Science Course
Mon 24th Nov 2025
Python Data Science Course
Mon 8th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


