



 Top Rated Course
Top Rated Course


We may not have the course you’re looking for. If you enquire or give us a call on +420 210012971 and speak to our training experts, we may still be able to help with your training requirements.
What is the Data Science Lifecycle? A Complete Guide
Sophia Ellis 21 August 2023Gain a comprehensive understanding of the Data Science Lifecycle in this exploration of its various stages and the key members involved. Unlock insights into the lifecycle's intricacies, from its initial stages to the final results. Dive into the roles of data scientists, analysts, and engineers who collaborate in this dynamic process.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Data Science has emerged as a transformative force, revolutionising industries and driving evidence-based decision-making. At the heart of Data Science, lies its Lifecycle. The Data Science Lifecycle is a comprehensive and structured approach that guides the journey from the stage of raw data to actionable insights.
Furthermore, by understanding and implementing the best practices in this lifecycle, organisations can unlock the true potential of their data, empowering them to thrive in today's data-driven landscape. Learn everything about the Data Science Lifecycle of a project in this blog, including how Data Science products are built, delivered, and maintained.
Table of Contents
1) Understanding the Data Science Lifecycle
2) Exploring the stages of the Data Science Lifecycle
3) Popular frameworks for Data Science Lifecycles
4) A look at the members involved in the Data Science Lifecycle
5) Conclusion
Understanding the Data Science Lifecycle
The Data Science Lifecycle is a structured and iterative process that encompasses various stages to extract valuable insights and knowledge from data. It is a well-defined methodology used by Data Scientists to tackle complex problems and make data-driven decisions.
Additionally, the Data Science Lifecycle process involves a step-by-step approach, starting with data collection, followed by data preparation, exploratory data analysis, feature engineering, model building, model evaluation, and finally, model deployment.
Furthermore, in the Data Science Lifecycle, data is collected from many sources, such as databases, APIs, or web scraping, ensuring its quality and relevance. Subsequently, the data is prepared and transformed to eliminate errors, handle missing values, and format it for analysis. Exploratory Data Analysis helps in understanding patterns and relationships within the dataset.
Moreover, the crucial phase of feature engineering involves selecting and creating relevant features to enhance model performance. Model building comprises applying various Machine Learning algorithms to develop predictive models. These models are then evaluated using appropriate metrics to assess their accuracy and generalisation capabilities.
Learn to utilise information and discover data pathways like revenues and testimonials, by signing up for the Data Science Analytics Course now!
Exploring the stages of the Data Science Lifecycle
Here is a list of the various stages that comprise the Data Science Lifecycle, described as follows:
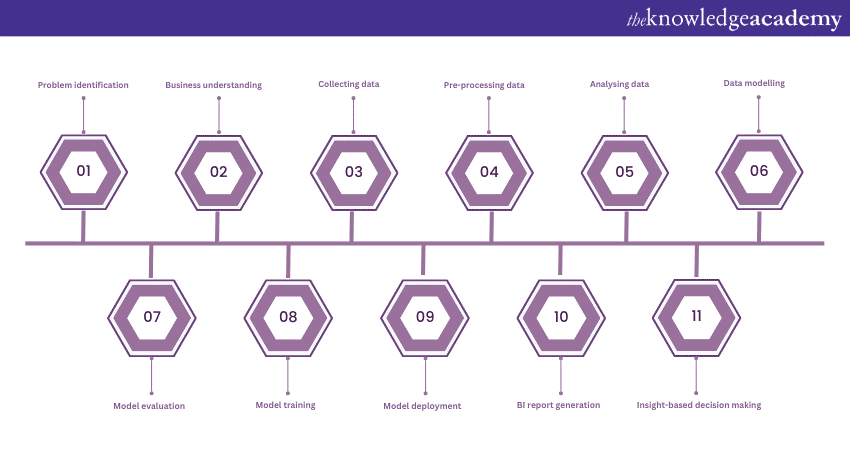
Problem identification
This is the first and most important stage of the Data Science Lifecycle, where the specific problem or challenge that needs a data-driven solution is defined and understood. This stage involves collaborating with stakeholders to understand their needs and objectives and refining the problem statement accordingly. This ensures that the data collection, analysis, and modelling stages are aligned with the organisation’s goals and expectations and that the insights and solutions generated are relevant and impactful.
Business understanding
This stage involves gaining a deep understanding of the organisation’s domain and industry context, as well as the business processes, objectives, and challenges. This helps Data Scientists align their analysis and modelling efforts with the organisation’s strategic goals and priorities.
Moreover, by understanding the Key Performance Indicators (KPIs) and the specific requirements of the stakeholders, Data Scientists can devise data-driven strategies that enhance growth and efficiency. By having a clear business understanding, Data Scientists can ensure that their solutions are tailored to the specific context and needs of the business problem.
Collecting data
Data collection is a fundamental stage in the Data Science Lifecycle, involving the gathering of relevant and reliable data from various sources. Data Scientists carefully select appropriate datasets, considering the specific problem or question to be addressed. This process may involve accessing data from databases, APIs, web scraping, or other external repositories.
Furthermore, ensuring data quality and integrity is paramount during data collection, as it forms the foundation for subsequent analysis and modelling. Properly collected data provides valuable insights and empowers Data Scientists to make informed decisions, enabling organisations to drive innovation and achieve their objectives.
Pre-processing data
Pre-processing data is a critical step in the Data Science Lifecycle that involves preparing raw data for analysis. This phase includes cleaning, transforming, and formatting the data to ensure its accuracy and reliability. Data Scientists handle missing values, remove duplicates, and address outliers to enhance the data's quality.
Additionally, data is transformed into a suitable format for analysis, such as numerical representation or one-hot encoding for categorical variables. Proper data pre-processing is essential to avoid bias and errors in the subsequent analysis and modelling stages, ensuring that the data is in optimal condition for extracting meaningful insights and building robust predictive models.
Analysing data
Analysing data is a core stage in the Data Science Lifecycle where data scientists explore and examine the prepared data to uncover patterns, trends, and correlations. Through descriptive and inferential statistical methods, as well as data visualisation techniques, they gain valuable insights into the dataset's underlying characteristics.
Additionally, this analysis allows for a deeper understanding of the relationships between variables, identifying outliers or anomalies, and revealing potential factors influencing the defined problem. Data Analysis is crucial for making data-driven decisions and guiding the subsequent steps in the lifecycle, such as model building and evaluation, leading to impactful and informed solutions.
Data modelling
Data modelling is a pivotal phase in the Data Science Lifecycle, where Data Scientists develop predictive or descriptive models using various algorithms in Machine Learning. These descriptive models are designed to identify patterns and relationships in the data, enabling accurate predictions or classifications.
Furthermore, selecting the appropriate algorithm and features is crucial for achieving high-quality outcomes. Data modelling helps in extracting valuable insights from the dataset and provides a framework for making data-driven decisions. By leveraging the power of data modelling, organisations can optimise processes, enhance customer experiences, and gain a competitive advantage in their respective industries.
Model evaluation
Model evaluation is a vital stage in the Data Science Lifecycle, where the performance and effectiveness of the developed models are assessed. Data Scientists use various evaluation metrics, such as accuracy, precision, recall, F1-score, and ROC curves, to measure how well the models perform on unseen data.
Furthermore, this analysis helps identify potential issues like overfitting or underfitting and allows for model fine-tuning. Evaluating models ensures that they can make reliable predictions and generalise well to real-world scenarios. Accurate model evaluation is crucial for selecting the most suitable model for deployment, ensuring that data-driven decisions are based on robust and trustworthy predictions.
Learn to create reports and organise data in various templates through our comprehensive Cognos BI Training today!
Model training
This stage involves feeding the selected data into the chosen Machine Learning algorithms to train the models to recognise patterns and make predictions. During this stage, the models adjust their internal parameters using optimisation techniques to improve their accuracy and performance. Additionally, this stage involves splitting the data into training and validation sets to ensure the model’s ability to generalise to new data.
By properly training and tuning the models, Data Scientists can find the optimal model configuration that captures the relationships within the data effectively. Successful model training enables Data Scientists to generate valuable insights and make accurate predictions that support data-driven decision-making.
Model deployment
Model deployment is the final and critical phase in the Data Science Lifecycle, where the trained and evaluated models are integrated into the operational environment. Once deployed, the models can provide real-time predictions and actionable insights, supporting data-driven decision-making.
Furthermore, this stage involves implementing the model in a production environment, ensuring its seamless integration with existing systems. Continuous monitoring and maintenance of the systems are essential to ensure the model's accuracy and performance over time. Successful model deployment allows organisations to leverage data-driven insights, automate processes, and make informed decisions, driving efficiency and unlocking the full potential of Data Science solutions.
Business Intelligence (BI) report generation
This stage involves transforming the data insights into informative reports and dashboards using data visualisation tools and techniques. Data Scientists present complex data in a clear and visually appealing way, highlighting the key findings and outcomes of the Data Analysis and modelling stages. These reports enable the stakeholders, including executives and decision-makers, to easily understand the results and make informed decisions.
Business Intelligence reports summarise the Data Analysis and model outcomes, making it easier for businesses to identify trends, patterns, and areas of improvement. Through effective BI report generation, organisations can gain actionable insights, optimise processes, and drive strategic decision-making with confidence.
Insight-based decision making
Insight-based decision making is a data-driven approach where organisations leverage the valuable insights derived from data analysis and modelling to guide their strategic and operational decisions. By making decisions based on concrete evidence and patterns revealed through data, businesses can reduce uncertainty and risk, leading to more informed and effective choices.
Furthermore, insight-based decision making empowers organisations to identify opportunities, optimise processes, and respond to challenges with precision. By embracing data-driven insights, businesses can gain a competitive edge, drive innovation, and achieve their goals with greater confidence and success in today's data-driven landscape.

Popular frameworks for Data Science Lifecycles
Data Science is the process of extracting insights and value from data using various methods and tools. There are different frameworks that guide Data Scientists through the stages of a Data Science project, from understanding the business problem to delivering the solution. Let’s explore the different frameworks:
Data mining Lifecycles
Data mining Lifecycles are the steps involved in conducting a data mining project, from defining the problem to deploying the solution. Let's explore some popular frameworks used in Data Mining Lifecycles:
1) Knowledge Discovery in Database (KDD) process: This is one of the most popular frameworks for data mining. It contains five steps, including data selection, data cleaning, data transformation, data mining, and knowledge interpretation. It shows us the interactive nature of data mining and the importance of validating and evaluating the results.
2) SEMMA: This framework helps users use the tools in SAS Enterprise Miner for data mining problems. It has five steps, including sample, explore, modify, model, and assess. It helps us build and test machine learning models using large data sets and deal with complex problems with ease and efficiency.
3) CRISP-DM: This is one of the widely used frameworks for data mining. It covers the whole data mining process from the business side to the technical side and gives us a common language and framework for data mining people and stakeholders. It is flexible and adaptable to different kinds of data mining projects and domains.
Modern Data Science Lifecycles
The data mining Lifecycles are ideal for describing the core data mining process, but they may not include the full scope and complexity of a Data Science project. So, some modern Data Science Lifecycles were developed to deal with the operational and organisational aspects of a Data Science project. Here are some of them:
1) OSEMN: This is a five-phase Lifecycle that stands for Obtain, Scrub, Explore, Model, and Interpret. It focuses on the core data problem and the steps involved in getting, cleaning, analysing, and communicating the data and the results.
2) Microsoft TDSP: This is a Lifecycle that combines many modern agile practices with a structure similar to CRISP-DM. It has five steps: Business understanding, data acquisition and understanding, modelling, deployment, and customer acceptance. It helps us manage, collaborate, and document throughout the Data Science project Lifecycle.
3) Domino Data Labs Lifecycle: This is a Lifecycle that is maybe most similar to my generic Lifecycle, partly because it has a final operations stage. It has six steps, including ideation, data acquisition and exploration, research and development, validation, delivery, and monitoring. It covers the whole Data Science project from the initial idea to the final product and the ongoing maintenance and improvement.
Acquire the knowledge and skills for analysing business processes through our Business Analyst Course today!
A look at the members involved in the Data Science Lifecycle
Below are the descriptions of each of the members involved in the Data Science Lifecycle:
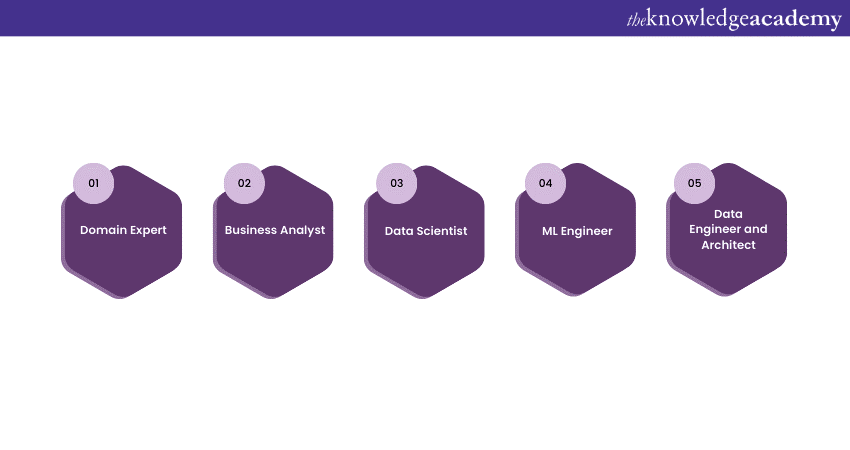
Domain expert
The domain expert plays a crucial role as a member of the Data Science Lifecycle. Their expertise in the specific industry or field of interest is invaluable in understanding the nuances of the data and its context. Collaborating with Data Scientists, domain experts provide valuable insights into the problem at hand, guiding the data analysis and modelling processes.
Furthermore, their in-depth knowledge helps in identifying relevant features, defining meaningful evaluation metrics, and interpreting the results in a business context. By combining the domain expert's knowledge with Data Science techniques, the team can develop more accurate and relevant solutions, enabling informed decision-making and impactful outcomes.
Business Analyst
The Business Analyst plays a significant role in the Data Science Lifecycle, acting as a bridge for the technical team and the business stakeholders. With a deep understanding of the organisation's processes and objectives, the Business Analyst translates business requirements into data-driven solutions.
Furthermore, they work closely with Data Scientists to define clear problem statements, identify relevant data sources, and establish Key Performance Indicators (KPIs). Additionally, they help in validating the results of Data Analysis and models in the context of business needs. The Business Analyst 's involvement ensures that data-driven insights align with the organisation's goals, driving effective decision-making and fostering business success.
Data Scientist
The Data Scientist is a central figure in the Data Science Lifecycle, possessing a unique blend of technical skills and domain knowledge. They are responsible for collecting, pre-processing, and analysing data to uncover valuable insights and patterns. With expertise in various machine learning algorithms, the Data Scientist builds predictive and descriptive models to solve complex problems.
Furthermore, they collaborate with domain experts and business analysts to understand the context of the data and translate it into actionable solutions. Proficient in data visualisation, the Data Scientist communicates findings effectively, guiding decision-makers to make informed choices that drive innovation and success for the organisation.
ML Engineer
The ML Engineer is a key player in the Data Science Lifecycle, specialising in implementing and deploying machine learning models at scale. They possess a strong background in Software Engineering and are skilled in programming languages like Python and R. ML Engineers work closely with Data Scientists to operationalise models, optimise performance, and automate processes.
Furthermore, they ensure the seamless integration of machine learning solutions into production systems, making real-time predictions and driving business efficiency. With expertise in cloud computing and distributed systems, the ML engineer plays a pivotal role in transforming Data Science prototypes into practical, scalable, and reliable solutions that benefit the organisation's operations and decision-making processes.
Acquire mastery over concepts like neural networks and clustering techniques, by signing up for the Machine Learning Course now!
Data Engineer and Architect
The Data Engineer and Architect are instrumental roles in the Data Science Lifecycle, responsible for designing and building the infrastructure required for data processing and storage. Data engineers focus on developing data pipelines and data warehouses, ensuring the smooth flow and integration of data from various sources.
Additionally, they optimise data structures for efficient querying and retrieval. On the other hand, data architects create the overall blueprint for the data ecosystem, ensuring its scalability, security, and compliance with industry standards. Together, they collaborate to provide a robust foundation that enables Data Scientists and Analysts to work with large volumes of data efficiently and derive meaningful insights for the organisation's success.
Data Science Developer
Data Science Developers design, create and code large Data Analytics programs to support scientific or business/enterprise goals. This role requires some Data Science skills as well as practical Software Development knowledge. This role is also known as a machine learning engineer. They help to bridge the gap between Software Development and Data Science.
Data Science Manager
A Data Science Manager is the leader of the team, coordinating all the tasks and ensuring that they are done well. They communicate with all clients and keep all commitments. They ensure timely, high-quality deliveries. They manage change and motivate business users to adopt the solution.
Conclusion
The Data Science Lifecycle is a systematic and iterative process that empowers organisations to harness the power of data to drive innovation and informed decision-making. From problem identification to model deployment, each stage plays a vital role in extracting valuable insights and developing impactful solutions.
Acquire the programming skills and the knowledge base of extracting insights from data, by signing up for the Data Science Training Courses now!
Frequently Asked Questions
Is Data Science a safe career?

Data Science is a safe career as it is one of the most in-demand and high-paying fields in the world today. Data Scientists are needed in various industries and sectors, such as healthcare, finance, e-commerce, Information Technology (IT), education, etc.
Who can study Data Science?
Anyone who has an interest and aptitude for Data Analysis, programming, Mathematics, and Statistics can study Data Science. However, having a degree in Computer Science, Mathematics, Statistics, or a related field can be beneficial for gaining the necessary skills and knowledge. Data Science also requires workplace skills such as communication, teamwork, and problem-solving.
What are the other resources provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 17 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, blogs, videos, webinars, and interview questions. By tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is Knowledge Pass, and how does it work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knowsno bounds.
What are related Data Science courses and blogs provided by The Knowledge Academy?
The Knowledge Academy offers various Data Science Courses, including Python Data Science, Text Mining Training and Predictive Analytics Course. These courses cater to different skill levels, providing comprehensive insights into Data Science methodologies.
Our Data Science blogs covers a range of topics related to Data Science, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Data Science skills, The Knowledge Academy's diverse courses and informative blogs have you covered.
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


