



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on 0800 446148 and speak to our training experts, we may still be able to help with your training requirements.
MapReduce Architecture: A Complete Guide
Sophia Ellis 16 November 2024This blog covers everything you need to know about MapReduce Architecture, a powerful framework for processing large-scale data sets. You will learn what MapReduce is, how it works, what its advantages are, and how to apply it to various Hadoop MapReduce applications.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

When it comes to managing the colossal volumes of data in today's digital age, organisations often grapple with challenges such as slow processing times and resource limitations. These issues can lead to missed opportunities and hinder data-driven decision-making. However, understanding MapReduce Architecture can help you navigate these challenges and unlock the potential of efficient and scalable data processing.
If you want to learn more about it, this blog is for you. In this blog, you will learn What is MapReduce, how it works, its benefits and use cases. Let's dive in to understand more!
Table of Contents
1) What is MapReduce?
2) How does MapReduce work?
3) Advantages of MapReduce
4) Use cases for Hadoop MapReduce applications
5) Conclusion
What is MapReduce?
MapReduce is a computational framework and programming model used for processing and generating large datasets in a distributed computing environment. It simplifies the parallel processing of data across multiple nodes or servers, making it possible to handle massive amounts of information efficiently. It was initially developed by Google and popularised by Apache Hadoop.
MapReduce divides tasks into two main phases: the mapping phase and the reducing phase. The former processes and sorts data, and the latter aggregates and summarises the results. This approach enables the scalable and fault-tolerant processing of Big Data, making it a fundamental tool in the world of Data Analytics and processing.

How does MapReduce work?
MapReduce operates through a series of steps that facilitate processing large datasets. Here’s how it works:
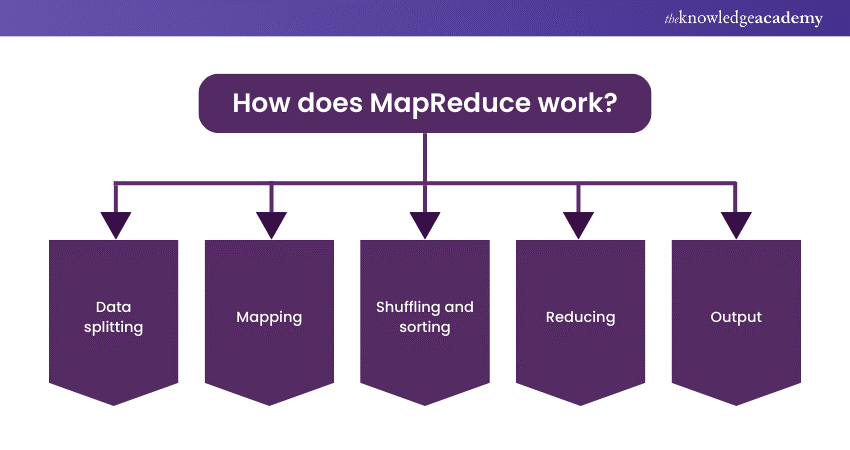
1) Data splitting: The input data is initially divided into smaller portions or "splits." Each split is a manageable chunk that can be processed in parallel.
2) Mapping: In this phase, the mapper function is applied to each split independently. The mapper processes the data and emits intermediate key-value pairs based on the specified operation. These key-value pairs are sorted and grouped by keys.
3) Shuffling and sorting: This step involves the shuffling of intermediate data among nodes in the cluster. Data with the same key is grouped together, and the sorting process organises these groups to prepare for the next phase.
4) Reducing: The reducer phase begins with a reducer function that processes the sorted data groups, one group at a time. It aggregates, summarises, or performs further computations on the data associated with each key. The result of each reduction is the final output for that particular key.
5) Output: The output of the reducer phase consists of the processed data, typically stored in a distributed file system or delivered to the application that initiated the MapReduce job.
MapReduce leverages parallel processing across multiple nodes, making it suitable for handling vast amounts of data. Its division into mapping and reducing phases ensures efficient data processing, while fault tolerance mechanisms enhance its reliability, making it a vital component in Big Data Analytics and processing.
Advantages of MapReduce
MapReduce offers several key advantages, making it a valuable framework for processing large datasets. Let’s explore some of them here:
1) Scalability: MapReduce can handle massive datasets by dividing tasks into smaller chunks that can be processed parallel across a cluster of machines. This scalability allows organisations to process and analyse data of any size, from terabytes to petabytes.
2) Fault tolerance: MapReduce is designed to be fault tolerant. If a node or machine fails during processing, the framework automatically redistributes the task to another available node, ensuring that the job continues without interruption. This resilience is critical for processing large-scale data reliably.
3) Distributed computing: MapReduce leverages distributed computing, enabling organisations to use a cluster of commodity hardware rather than relying on a single, expensive supercomputer. This approach is cost-effective and flexible.
4) Ease of use: MapReduce abstracts many of the complexities of distributed computing, making it accessible to a broader range of users. Developers can focus on writing maps and reducing functions without needing in-depth knowledge of distributed systems.
5) Parallel processing: The parallel processing capabilities of MapReduce significantly reduce processing times. MapReduce accelerates data processing and analysis by executing tasks in parallel across multiple nodes.
6) Data locality: MapReduce processes data where it resides, minimising data transfer over the network. This approach reduces network congestion and improves overall performance.
7) Support for various data types: MapReduce is not limited to structured data; it can process various data types, including unstructured and semi-structured data. This flexibility is crucial in today's diverse data landscape.
8) Community and ecosystem: MapReduce is part of the Apache Hadoop ecosystem, which boasts a vibrant and active community. This community support ensures ongoing development, updates, and access to a wide range of tools and libraries for data processing.
9) Cost-effective storage: MapReduce works seamlessly with Hadoop Distributed File System (HDFS), which offers cost-effective and scalable storage solutions. This integration further reduces the total cost of ownership for Big Data processing.
10) Versatile applications: MapReduce can be applied to various domains, including Data Analytics, Machine Learning, log processing, and more. Its versatility makes it a valuable tool for a wide range of applications.
Overall, it is an indispensable framework for organisations dealing with large datasets. Its ease of use and vibrant ecosystem further contribute to its popularity in the world of Big Data processing.
Unlock the potential of data-driven innovation with our Big Data Architecture Training – Sign up now!
Use cases for Hadoop MapReduce applications
Hadoop MapReduce has found wide-ranging applications across various industries and domains due to its ability to process and analyse massive datasets efficiently. Here are some prominent use cases:
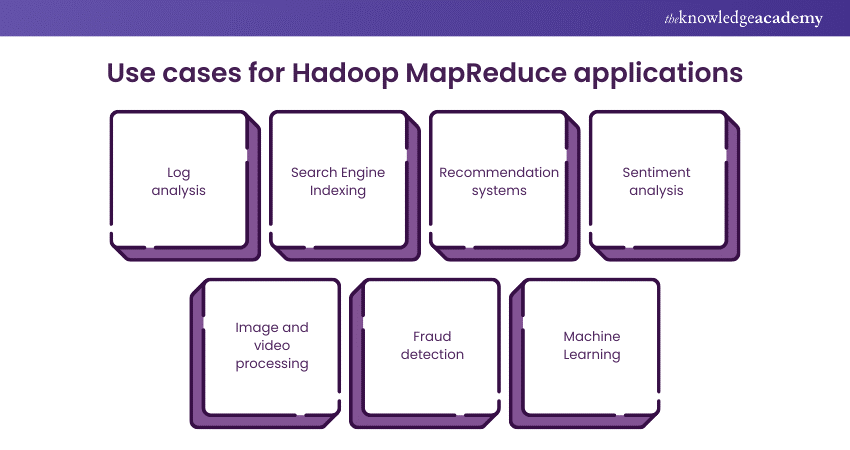
1) Log analysis: MapReduce is extensively used for analysing log files generated by servers, applications, and network devices. It helps identify patterns, anomalies, and performance issues, enabling organisations to enhance system reliability and security.
2) Search Engine Indexing: Search engines like Google use MapReduce to crawl and index web pages. This enables faster and more relevant search results for users.
3) Recommendation systems: E-commerce platforms and streaming services employ MapReduce to analyse user behaviour and preferences. This data is used to generate personalised recommendations, increasing user engagement and sales.
4) Sentiment analysis: Social media platforms and market research firms use MapReduce for sentiment analysis of user-generated content. It helps gauge public opinion, track trends, and assess brand perception.
5) Image and video processing: MapReduce is used to process and analyse multimedia content. It helps classify images, perform object recognition, and process video streams efficiently.
6) Fraud detection: Financial institutions employ MapReduce to detect fraudulent activities by analysing large volumes of transaction data. It identifies unusual patterns and suspicious transactions in real time.
7) Machine Learning: MapReduce can be integrated with Machine Learning algorithms to train models on large datasets. This is crucial in applications like natural language processing, recommendation systems, and predictive analytics.
Take the leap into the world of Big Data with our Big Data and Hadoop Solutions Architect Course – Sign up today!
Conclusion
We hope you read and understand everything about MapReduce Architecture. It is an essential framework for processing vast datasets efficiently. Its scalability, fault tolerance, and versatility make it invaluable across diverse industries. As Big Data continues to grow, MapReduce remains a pivotal tool, enabling organisations to derive meaningful insights and drive data-driven decisions.
Master the art of MapReduce programming with our MapReduce Programming Model Training – Sign up now!
Frequently Asked Questions
What is the significance of a MapReduce Architecture diagram?

A MapReduce Architecture diagram visually represents the components and flow of data in a MapReduce system, aiding in understanding its structure.
Can you explain MapReduce Architecture in simple terms?
MapReduce Architecture is a framework for processing large datasets by dividing tasks into smaller chunks, processing them in parallel, and aggregating the results. It's the backbone of Big Data processing.
What are the other resources and offers provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 17 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, blogs, videos, webinars, and interview questions. By tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is Knowledge Pass, and how does it work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the related courses and blogs provided by The Knowledge Academy?
The Knowledge Academy offers various Programming Courses, including Elastic MapReduce, Object Oriented Programming (OOPs) and Python with Machine Learning. These courses cater to different skill levels, providing comprehensive insights into Programming methodologies in general.
Our Programming blogs cover a range of topics related to Elastic MapReduce, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Programming skills, The Knowledge Academy's diverse courses and informative blogs have you covered.
Upcoming Programming & DevOps Resources Batches & Dates
Date
 MapReduce Programming Model Training
MapReduce Programming Model Training
MapReduce Programming Model Training
Fri 3rd Jan 2025
MapReduce Programming Model Training
Fri 28th Mar 2025
MapReduce Programming Model Training
Fri 23rd May 2025
MapReduce Programming Model Training
Fri 4th Jul 2025
MapReduce Programming Model Training
Fri 5th Sep 2025
MapReduce Programming Model Training
Fri 24th Oct 2025
MapReduce Programming Model Training
Fri 5th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


