



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +33 805638382 and speak to our training experts, we may still be able to help with your training requirements.
Difference Between Hadoop and MapReduce: A Detailed Comparison
Sophia Ellis 16 November 2024This blog highlights the Difference Between Hadoop and MapReduce, key components in Big Data Processing. Here you will learn what Hadoop and MapReduce are, and the comparison that emphasises their collaborative uses in managing large datasets efficiently for scalable Data Processing.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents
In this dynamic era of Big Data Processing, understanding the fundamental Difference Between Hadoop and MapReduce is crucial. These two concepts often used interchangeably, play distinct yet complimentary roles in handling large data sets. Hadoop and MapReduce are thus two different implementations of the MapReduce/framework or concept.
Hadoop is an ecosystem of open-source projects. Hadoop, as such, is an open-source framework for storing and processing massive datasets. Hadoop Distributed File System (HDFS) carries out the storing, and MapReduce takes care of the processing. MapReduce is a programming model that allows you to process vast amount of data. Explore this complete blog to learn about the key Differences Between Hadoop and MapReduce.
Table of Contents
1) What is Hadoop?
2) What is MapReduce?
3) Difference Between Hadoop and MapReduce
4) Conclusion
What is Hadoop?
Hadoop is an open-source software framework that is used for storing and processing large amounts of data in a distributed computing environment. It is designed to handle Big Datasets and is based on the MapReduce programming model, which allows for the processing of large datasets. Its framework is based on java programming with some native code in C and shell scripts.
Designed to handle massive datasets across clusters of computers, Hadoop employs a fault tolerant approach. Its core components, Hadoop Distributed File System (HDFS) and MapReduce, work collaboratively to enable efficient storage and processing of substantial volumes of data.

What is MapReduce?
A MapReduce is a Data Processing tool which is used to process the data parallelly in a distributed form. It was developed in the year 2004, based on a paper published by Google, named as “MapReduce: Simplified Data Processing on Large Clusters”. It is used to compute huge amount of data and to handle upcoming data in parallel and distributed form, the data must flow from various phases.
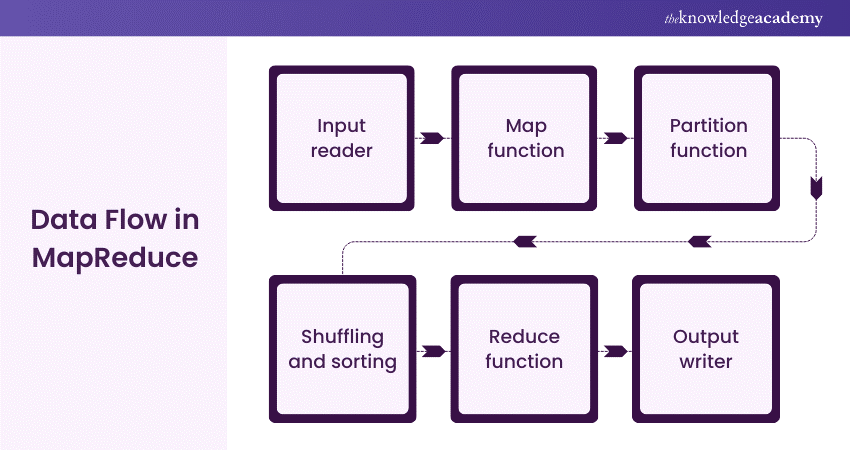
Being a programming model, it is used for the implementation for processing and generating Big Data sets with distributed algorithm on a cluster. The MapReduce is a paradigm that has two phases, the mapper phase and the reducer phase. In the mapper phase input is given as a key-value pair. The output of the mapper is fed to the reducer as input. The reducer runs only after the mapper is over.
Master Hadoop and MapReduce with Hadoop Training Course with Impala – Sign up now!
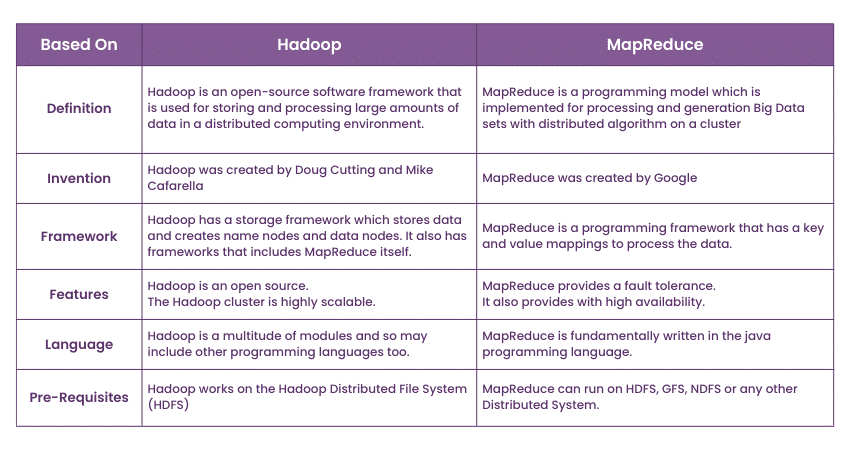
Difference Between Hadoop and MapReduce
As we navigate the expansive realm of Big Data, its essential to grasp the basics that differentiate between the two fundamental pillars. Hadoop is an open-source framework that revolutionises Data Processing with its scalable and distributed environment. MapReduce, on the other hand, is a programming model that orchestrates data computations within Hadoop environments.
Learn more about the Differences Between Hadoop and MapReduce, with the comprehensive table below, that defines the key differences in their roles and contributions:
Unlock the future of programming with our Hadoop Big Data Certification Course – Join today!
Conclusion
In the ever-evolving landscape of data, the Hadoop and MapReduce collaboration will continue to shape the way we approach large scale computing challenges. By learning about their individual strengths and collaborative potential, you can embark on the journey of learning programming and utilising these skills in the era of technological abundance.
Stay at the forefront of programming with our Hadoop Administration Training – Sign up today!
Frequently Asked Questions
What is the primary role of Hadoop in Big Data Processing?

Hadoop is an open-source framework designed for scalable and fault-tolerant storage and processing of massive datasets across clusters of computers.
Can MapReduce solve Big Data problems?
MapReduce, a programming model within the Hadoop framework, orchestrates data computations, enabling efficient processing and analysing of large datasets in a distributed computing environment.
What are the other resources and offers provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 17 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is Knowledge Pass, and how does it work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are related Programming courses and blogs provided by The Knowledge Academy?
The Knowledge Academy offers various Programming and DevOps courses, including programming training, Practitioner, and Agile. These courses cater to different skill levels, providing comprehensive insights into Programming Training methodologies.
Our Programming and DevOps blogs covers a range of topics related to programming, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Project Management skills, The Knowledge Academy's diverse courses and informative blogs have you covered.
Upcoming Programming & DevOps Resources Batches & Dates
Date
 MapReduce Programming Model Training
MapReduce Programming Model Training
MapReduce Programming Model Training
Fri 28th Feb 2025
MapReduce Programming Model Training
Fri 4th Apr 2025
MapReduce Programming Model Training
Fri 27th Jun 2025
MapReduce Programming Model Training
Fri 29th Aug 2025
MapReduce Programming Model Training
Fri 24th Oct 2025
MapReduce Programming Model Training
Fri 5th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


