



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +33 805638382 and speak to our training experts, we may still be able to help with your training requirements.
Top 25+ MapReduce Interview Questions and Answers
Sophia Ellis 16 November 2024From this blog, you will discover some of the best sample MapReduce Interview Questions, which will help you crack your following interview. From this blog, you will learn all about MapReduce-related intricacies, which will act as some of the best tools to excel in this domain and the interview.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

MapReduce is a processing framework and programming model for distributed computing and large-scale data processing. Google popularised it and later became the foundation for various big data processing technologies, including Apache Hadoop. So, if you want to be part of this domain, you will have to face some of the most interesting MapReduce Interview Questions. To help you prepare for the following interviews, read this blog, where we have discussed some of the most asked MapReduce Interview Questions and some sample answers.
Table of Contents
1) MapReduce Interview Questions for beginners
a) Tell me the difference between MapReduce and Spark.
b) Define MapReduce.
c) Give me an example of the workings of MapReduce.
d) Tell me the main components of MapReduce Job.
e) Tell me the main components of the MapReduce Job.
f) Can you tell me about the Partitioner and its usage?
g) Define Identity Mapper and Chain Mapper.
h) Can you tell me the main configuration parameters in MapReduce?
i) What are some Job control options specified by MapReduce?
j) Tell me, what is InputFormat in Hadoop?
k) Give me some differences between HDFS block and InputSplit.
l) Do you know what is Text InputFormat?
m) Define JobTracker.
n) Can you explain job scheduling through JobTracker to me?
o) Define SequenceFileInputFormat.
p) How can you set mappers and reducers for Hadoop jobs?
q) What is JobConf in MapReduce?
r) Define MapReduce Combiner.
s) Can you tell me about RecordReader in a Map Reduce?
t) What are Writable data types in MapReduce?
2) MapReduce Interview Questions for professionals
3) Conclusion
MapReduce Interview Questions for beginners
Let’s look at some of the common interview questions along with some sample answers, which will help you prepare for your next interview:
1) Tell me the difference between MapReduce and Spark.
You can answer this question in this manner: "MapReduce and Spark are both popular distributed data processing frameworks, but they have some crucial differences. MapReduce is primarily a batch processing model consisting of two stages - Map and Reduce. In contrast, Spark is more versatile, supporting batch and real-time data processing.
One significant difference is that Spark leverages in-memory processing, resulting in faster data analysis, whereas MapReduce writes data to disk between stages, which can be slower. Spark also offers higher-level APIs and libraries, making it more developer-friendly than MapReduce."
2) Define MapReduce.
You can use this answer for this question: "MapReduce is a widely used programming model and distributed data processing framework. It simplifies the processing of large datasets by breaking down complex tasks into two main phases. In the Map phase, input data is divided into smaller chunks, and a 'mapper' function is applied to each chunk independently.
The mapper processes and extracts relevant information, emitting key-value pairs as intermediate outputs. In the Reduce phase, these intermediate pairs are sorted and grouped by key, and a 'reducer' function is applied to aggregate or further process the data. MapReduce enables parallel processing and scalability, making it suitable for Big Data Analytics."
3) Give me an example of the workings of MapReduce.
You can answer this question: "Certainly, let's consider the example of counting word frequencies in a large text document using MapReduce. The document is divided into smaller portions in the Map phase, and a mapper function is applied to each portion. The mapper tokenises the text, generating key-value pairs where the key is a word and the value is 1. These intermediate pairs are sorted and grouped by word in the Reduce phase. The reducer adds up the values associated with each word, providing the final word count."

4) Tell me the main components of the MapReduce Job.
You can use this answer: "A MapReduce job consists of several key components. These include the Mapper, which processes input data; the Reducer, which aggregates and processes the intermediate results; the Partitioner, which determines how data is distributed among reducers; InputFormat and OutputFormat, which define how data is read and written; JobClient for job submission, and in the context of Hadoop 1.x, JobTracker for resource management and job scheduling."
5) Difference between Shuffling and Sorting in MapReduce.
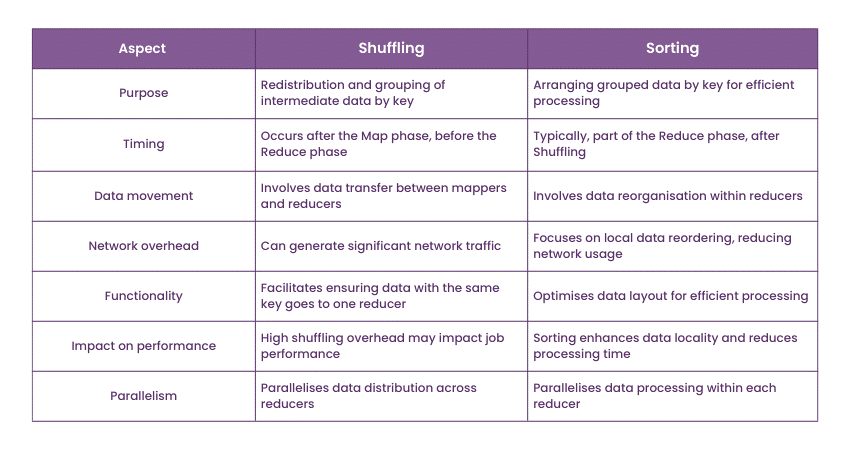
You can use this sample answer: "Shuffling and sorting are essential steps in MapReduce. Shuffling refers to redistributing and grouping intermediate key-value pairs generated by the mappers based on their keys. This step is crucial for ensuring that all values associated with the same critical end up at the same reducer for processing.
Sorting, on the other hand, arranges the grouped key-value pairs by their keys in preparation for the Reduce phase. Sorting ensures that the reducer receives the data in a sorted order, making it easier to process."
6) Can you tell me about the Partitioner and its usage?
Use this sample answer for this question: "Certainly, a Partitioner is a critical component in MapReduce. It determines how the intermediate key-value pairs generated by the mappers are distributed among the reducers. The Partitioner takes the key and assigns it to a specific reducer.
Its primary purpose is to ensure that all key-value pairs with the same critical end up in the same reducer, facilitating data aggregation. The choice of Partitioner can impact the performance and load balancing of a MapReduce job, so it's crucial to choose an appropriate Partitioner for your data processing task."
7) Define Identity Mapper and Chain Mapper.
You can use this answer: "An Identity Mapper is a straightforward mapper that passes the input data as-is to the Reducer without any transformation. It's typically used when no data manipulation is required during the Map phase. On the other hand, a Chain Mapper is a concept that allows you to chain multiple Mapper classes together for sequential data processing.
You can apply a sequence of mappers to your data, each performing a specific transformation, and then pass the output to the Reducer. Chain Mappers are helpful when using multiple map operations to your data."
8) Can you tell me the main configuration parameters in MapReduce?
Use this sample answer for this question: "Certainly, MapReduce jobs are configured using a variety of parameters. Some of the main configuration parameters include 'mapreduce.job.name' for specifying the job name, 'mapreduce.input.fileinputformat.split.minsize' to set the minimum split size, 'mapreduce.map.memory.mb' and 'mapreduce.reduce.memory.mb' to allocate memory to map and reduce tasks, respectively, and many others for fine-tuning job behaviour and resource allocation. Proper configuration is crucial for optimising job performance and resource utilisation."
9) What are some Job control options specified by MapReduce?
You can use this answer: "MapReduce provides several job control options to manage and monitor job execution. These options include setting job priorities to influence scheduling, specifying job dependencies to control the execution order, and configuring job scheduling settings like fair scheduling or capacity scheduling. Additionally, MapReduce allows you to use counters to keep track of various statistics during job execution, aiding in monitoring and debugging."
10) Tell me, what is InputFormat in Hadoop?
You can use this answer: "In Hadoop MapReduce, InputFormat is a critical component that defines how input data is read and split into InputSplits, smaller portions of data processed by individual mappers. InputFormat also specifies how records within those InputSplits are parsed and converted into key-value pairs for processing by the Mapper.
Various InputFormats are available, such as TextInputFormat for processing plain text files, SequenceFileInputFormat for binary sequence files, and many more. Choosing the right InputFormat is essential for correctly processing different types of input data."
Are you interested in learning more about MapReduce Programming Model? Sign up now for our MapReduce Programming Model Training!
11) Give me some differences between HDFS block and InputSplit.
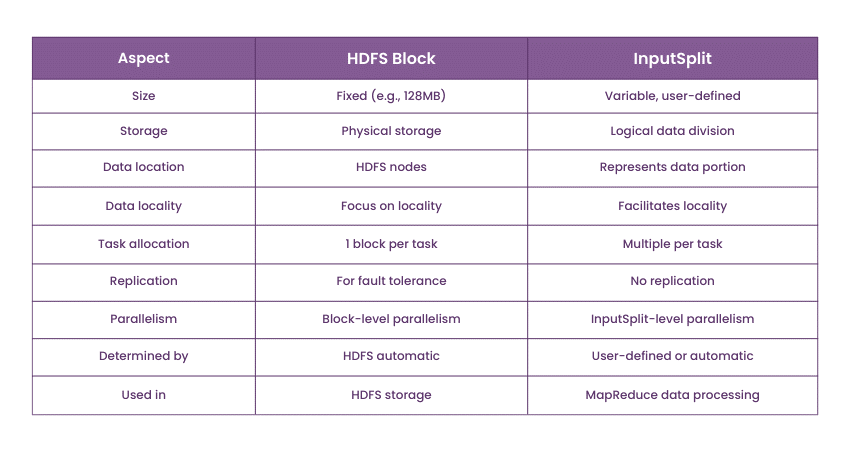
Use this sample answer for this question: "HDFS block and InputSplit are fundamental concepts in Hadoop MapReduce. HDFS block is a physical storage unit on the Hadoop Distributed File System (HDFS), typically of fixed size (e.g., 128 MB or 256 MB). InputSplit, on the other hand, is a logical division of data for processing in MapReduce.
InputSplits are usually smaller than HDFS blocks and are determined based on data locality, making them a logical view of the data. While HDFS blocks are used for storage, InputSplits are used for parallel processing within the MapReduce framework."
12) Do you know what is Text InputFormat?
Use this sample answer for this question: "Yes, Text Input Format is a common InputFormat used in Hadoop MapReduce for processing plain text files. It reads the input file line by line and treats each line as a separate record. Each line is then converted into a key-value pair, where the key is usually the byte offset of the line in the file, and the value is the content of the line. Text Input Format is suitable for tasks where input data is in text format, such as log processing and text analytics."
13) Define JobTracker.
You can answer this question in this manner: "JobTracker is a key component in Hadoop's MapReduce framework, primarily associated with Hadoop 1.x versions. It is responsible for resource management and job scheduling in a Hadoop cluster. JobTracker receives job submissions, schedules tasks, monitors progress, and ensures tasks are executed on available cluster nodes. JobTracker also handles task retries in case of failures. In later Hadoop versions, like Hadoop 2.x and above, the ResourceManager and ApplicationMaster replace the JobTracker for improved cluster resource management."
14) Can you explain job scheduling through JobTracker to me?
You can answer this question in this manner: "Job scheduling through JobTracker involves the allocation of tasks to available cluster nodes in a Hadoop cluster. When a job is submitted, JobTracker schedules tasks, considering data locality to minimise data transfer overhead. It assigns map tasks to nodes with the data needed for processing and optimising performance. Additionally, JobTracker monitors task execution, reschedules tasks in case of failures, and ensures the efficient utilisation of cluster resources."
15) Define SequenceFileInputFormat.
You can use this as your sample answer: "SequenceFileInputFormat is an InputFormat used in Hadoop MapReduce for reading binary sequence files. Sequence files are a specific file format used in Hadoop that can store key-value pairs efficiently. SequenceFileInputFormat is employed when your input data is stored in the sequence file format. It allows MapReduce to read and process data from these binary files efficiently, making it suitable for scenarios where data needs to be serialised and stored."
16) How can you set mappers and reducers for Hadoop jobs?
You can answer this question in this manner: "In Hadoop MapReduce, you can set the mappers and reducers for a job using configuration parameters. Specifically, you can use the 'mapreduce.job.mapper.class' parameter to specify the mapper class and the 'mapreduce.job.reducer.class' parameter to limit the reducer class.
These parameters are included in your job configuration. You can also set the number of mappers and reducers using parameters like 'mapreduce.job.maps' and 'mapreduce.job.reduces' to control the parallelism of your job."
17) What is JobConf in MapReduce?
You can answer this question in this manner: "JobConf, short for Job Configuration, is a class used in Hadoop 1.x for specifying job-related parameters and settings. It encapsulates configuration information required for a MapReduce job, including input and output formats, mapper and reducer classes, and other job-specific properties. JobConf objects are created and configured by developers to define the characteristics of their MapReduce jobs. In newer versions of Hadoop (Hadoop 2.x and above), the JobConf class has been replaced by the Configuration class."
18) Define MapReduce Combiner.
You can use this sample answer: "A MapReduce Combiner is an optional mini reducer that operates on the outputs of the Mapper before data is sent to the Reducer. It performs local aggregation and reduces the amount of data transferred over the network during the shuffle phase. Combiners can significantly improve job performance by reducing the volume of data that needs to be processed by the Reducer. They are handy for operations like summing, averaging, or counting and can be considered a 'mini reducer' at the map task level."
19) Can you tell me about RecordReader in a Map Reduce?
Answer this question: "Certainly, in a MapReduce context, a RecordReader is a crucial component responsible for reading data from InputSplits and converting it into key-value pairs that the Mapper then processes. The RecordReader is specific to the input format used and understands how to interpret the data format and extract meaningful records. It ensures that data is efficiently read and provided to the Mapper for further processing. Different input formats have corresponding RecordReaders tailored to their data structures."
20) What are Writable data types in MapReduce?
You can use this to answer this question: "Writable data types are a set of data serialisation classes provided by Hadoop's MapReduce framework. These classes allow MapReduce to serialise and deserialise data efficiently, reducing the overhead associated with data transfer between the Map and Reduce phases. Some common Writable data types include LongWritable, IntWritable, Text, and more. These types represent keys and values in MapReduce jobs, enabling the framework to work seamlessly with various data formats and types."
Become an expert in Programming with our Programming Training – sign up now!
MapReduce Interview Questions for professionals
If you are a professional looking to improve your skills in your career, you can prepare these MapReduce Interview Questions for your next interview. Let’s look at some of these questions along with their sample answers:
21) Define OutputCommitter.
You can use this as your question: "OutputCommitter is an essential component in Hadoop MapReduce. It defines how the output of a MapReduce job is committed or saved after the job has been completed successfully. It ensures the job's output is stored reliably and consistently, even during failures. OutputCommitter provides methods to specify where and how the final job output is written, making it a crucial part of the MapReduce job's success and fault tolerance."
22) Can you tell me about the “map” in Hadoop?
Answer this question in this way: "In Hadoop, 'map' refers to the first phase of the MapReduce processing model. During the 'map' phase, input data is divided into smaller portions, and a 'mapper' function is applied to each of these portions independently. The mapper processes and extracts relevant information, emitting key-value pairs as intermediate outputs. The 'map' phase is highly parallelisable, allowing multiple mappers to work concurrently on different portions of the input data, a key feature for processing large datasets in a distributed way."
23) Tell me about “reducer” in Hadoop.
You can add more to this sample answer: "In Hadoop, a 'reducer' is a key component of the MapReduce processing model, constituting the second phase. After the 'map' phase, intermediate key-value pairs generated by the mappers are sorted, grouped by their keys, and passed to the reducer.
The reducer then processes these grouped values, often performing aggregation or summarisation, to produce the final output of the MapReduce job. Reducers operate in parallel, with each reducer handling a specific set of key-value pairs. They play a crucial role in consolidating and analysing the results generated by the 'map' phase."
24) Tell me about the parameters of mappers and reducers.
You can answer this question in this way: Sample Answer: "Mappers and reducers in Hadoop MapReduce jobs can be configured with various parameters to control their behaviour. Some common parameters include setting the number of mappers and reducers using 'mapreduce.job.maps' and 'mapreduce.job.reduces,'.
This specifies the mapper and reducer classes using 'mapreduce.job.mapper.class' and 'mapreduce.job.reducer.class,' and configuring memory allocation for map and reduce tasks with 'mapreduce.map.memory.mb' and 'mapreduce.reduce.memory.mb.' These parameters allow developers to fine-tune their MapReduce jobs' performance and resource usage."
25) Tell me about the key differences between Pig vs MapReduce.
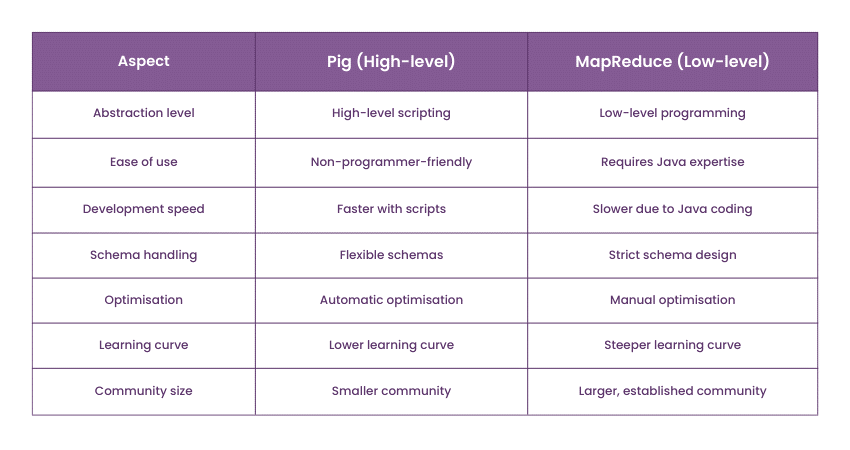
You can add to this sample answer: "Pig and MapReduce are both frameworks used for data processing in Hadoop, but they have notable differences. MapReduce is a low-level, Java-based programming model for distributed data processing, while Pig is a higher-level scripting language (Pig Latin) and platform that abstracts many MapReduce complexities. Pig offers concise and user-friendly data transformation and analysis scripts, making it more accessible to non-programmers.
Additionally, Pig optimises execution plans automatically, reducing the need for manual tuning. In contrast, MapReduce requires developers to write Java code for each processing step and handle many details. The choice between them depends on the particular requirements and the level of control needed in a data processing task."
Do you want to learn more about Swift Programming Language? Register now for our Swift Training!
26) Define partitioning.
You can use this as your sample answer: "Partitioning in Hadoop refers to dividing the output data from mappers into smaller, manageable portions before they are sent to reducers. It determines how key-value pairs are distributed among reducers for processing.
Partitioning ensures that all key-value pairs with the same critical end up in the same reducer, facilitating data aggregation and analysis. The choice of partitioning strategy can impact the performance and load balancing of a MapReduce job, as it determines which reducer will process specific keys."
27) How do you set which framework to run the MapReduce program?
You can add more to this sample answer: "The framework to run a MapReduce program is typically set in the Hadoop configuration. You can specify the framework to use precisely by selecting the 'mapreduce.framework.name' property in the Hadoop configuration files. You don't need to make any changes to run a MapReduce program using MapReduce (the default framework).
You can configure the property accordingly if you want to use other frameworks like Apache Tez or Apache Spark. The choice of framework depends on the unique requirements and optimisations you wish to apply to your MapReduce job."
28) Can you tell me what platform and Java version are required to run Hadoop?
You can answer this question in this manner: "Hadoop is designed to run on various platforms, including Linux, Windows, and macOS. However, it is primarily used on Linux-based systems for production deployment due to its stability and performance. As for Java, Hadoop is traditionally built using Java and requires a compatible Java runtime.
Specifically, Hadoop 2.x and later versions are compatible with Java 8 or higher, while Hadoop 1.x versions are compatible with Java 6 or 7. It's essential to ensure that the appropriate Java version is installed and configured correctly on the Hadoop platform."
29) Explain how the MapReduce program can be written in any language other than Java.
You can add more to this sample answer: "While Hadoop's MapReduce framework is primarily Java-based, it provides the flexibility to write MapReduce programs in other languages through Hadoop Streaming. Hadoop Streaming is a utility that allows you to use other scripting languages like Python, Ruby, or Perl for your Map and Reduce tasks.
You can specify your mapper and reducer scripts written in the chosen language, and Hadoop Streaming handles the communication between the Hadoop framework and your scripts. This enables developers to leverage their expertise in scripting languages while benefiting from Hadoop's distributed processing capabilities."
30) Tell me the difference between an identity mapper and identity reducer.
You can add more to this sample answer: "The identity mapper and identity reducer are special cases used in Hadoop MapReduce for specific scenarios. An identity mapper passes the input data as-is to the reducers without any transformation. It is used when no modification of the input data is needed during the 'map' phase.
On the other hand, an identity reducer also performs no transformation on the data. It simply passes the grouped data to the output as it is. An identity reducer is employed when the aggregation or processing of data is not required during the 'reduce' phase. These components are helpful in situations where you want to maintain the data's original format or structure in the final output."
Enhance your knowledge on web development and ReactJS – register now for our ReactJS Course!
Conclusion
We hope that you have understood some of the most asked questions for both freshers and professionals through this blog. These MapReduce Interview Questions and answers will help you prepare for your interviews and help you stand out from other candidates.
Understand more about Apache Cassandra – register now for our Apache Cassandra Training!
Frequently Asked Questions
Upcoming Programming & DevOps Resources Batches & Dates
Date
 MapReduce Programming Model Training
MapReduce Programming Model Training
MapReduce Programming Model Training
Fri 28th Feb 2025
MapReduce Programming Model Training
Fri 4th Apr 2025
MapReduce Programming Model Training
Fri 27th Jun 2025
MapReduce Programming Model Training
Fri 29th Aug 2025
MapReduce Programming Model Training
Fri 24th Oct 2025
MapReduce Programming Model Training
Fri 5th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


