



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on + 1-866 272 8822 and speak to our training experts, we may still be able to help with your training requirements.
What is Site Reliability Engineering?
Sienna Roberts 04 January 2025Site Reliability Engineering (SRE) is an approach to IT operations where the SRE teams incorporate Software Engineering into infrastructure and operations problems. This blog explores What is Site Reliability Engineering, outlining its benefits, roles, best practices, and metrics. Continue reading to learn more!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Ever wonder who's behind the seamless online and digital experience we often take for granted? Welcome to the world of Site Reliability Engineers (SREs). Their focus on automating processes, elevating system performance, and preventing downtime is an enormous responsibility in today's digital world.
These Engineers are the reasons we can imagine a world where websites never crash, apps never stumble, and services are always lightning-fast. This blog explores What is Site Reliability Engineering, diving into its benefits, best practises, and more. So read on and learn how SREs drive innovation in modern organisations.
Table of Contents
1) What is Site Reliability Engineering?
2) The Benefits of Site Reliability Engineering
3) Roles of a Site Reliability Engineer
4) Site Reliability Engineering Metrics
5) SRE and DevOps
6) What are the Four Golden Rules of SRE?
7) What Languages Does SRE Use?
8) Conclusion
What is Site Reliability Engineering?
Site Reliability Engineering (SRE) is a discipline that combines various aspects of Software Engineering and applies them to infrastructure and operations problems. The primary goal of SRE is to create scalable and highly reliable software systems.
This approach came about as a response to all the challenges posed by the increasing complexity of modern technology stacks and the need for systems that are not only functional but also highly available and dependable.

The Benefits of Site Reliability Engineering
Site Reliability Engineering offers plenty of benefits including the following:
1) Increased Reliability and Uptime: SRE prioritises preventing and mitigating incidents to ensure that applications and systems are consistently available and performant.
2) Improved Scalability: SRE helps organisations scale their infrastructure and applications more efficiently through optimised resource usage and minimised waste.
3) Improved User Experience: SRE ensures that applications and services are always available and responsive. This directly impacts customer satisfaction, brand reputation, and revenue.
4) Continuous Improvement: SRE spotlights the use of data and metrics to narrow down areas for improvement and drive ongoing innovation.
5) Increased Security: SRE can help guarantee that systems and applications are compliant and secure with industry standards and regulations.
6) Predictable Performance: By analysing usage patterns, SRE can help predict and prevent performance issues before they occur. This ensures that systems and applications perform predictably and with consistency.
7) Cost Savings: SRE can help reduce costs by automating routine tasks and optimising resource usage. This reduces the need for manual intervention and saves time and money.
8) Collaboration Between Development and Operations Teams: SRE emphasises cross-functional teams and focuses on shared ownership of reliability and performance.

Core Principles of Site Reliability Engineering
Site Reliability Engineering operates on several core principles that distinguish it from traditional operations and emphasise a holistic approach to System Management:
1) SRE Focuses on Automation:
A significant goal of SRE is to reduce duplication or redundancy of effort. SRE teams focus on automating manual tasks, including:
a) Provisioning access and infrastructure
b) Setting up accounts
c) Building self-service tools.
This enables development teams to focus on delivering features, while operations teams focus on managing infrastructure. Automating processes is even more critical as organisations speed up the delivery of new features into production.
2) SRE Bridges the Gap Between Dev and Ops:
SREs drive resiliency-based Engineering as they turn into mentors and ensure resiliency is top priority for developers and operations. Applying the DevOps mindset to software reliability helps reduce silos between development and operations teams through shared responsibility.
Collaboration between operations, developers, and product owners enables site reliability Engineers to meet uptime and availability targets.
3) SRE Drives a Shift-left Mindset
A shift-left mindset implies SREs can integrate reliability principles from Dev to Ops into each process, app, and code change to improve the software quality. Here are some ways SRE drives a shift-left mindset:
a) Design quality gates based on service level objectives (SLOs) to detect issues early in the development cycle.
b) Automate validation and build testing using service-level indicators (SLIs) and SLOs.
c) Impact architectural decisions during initial design stages to ensure resiliency at the outset of software development.
4) SRE Builds Tools and Services to Help Operations and Support
SRE aims to enable higher change rates while maintaining resiliency and a good uptime. In multi-Cloud environments, resiliency is measured across key metrics such as User Experience, responsiveness, performance, conversion rates, etc. SRE teams must build and implement services that elevate operations and facilitate the release process across these areas.
5) SRE Requires a Cultural change
Since SRE is a practice, it requires changing how teams across multiple disciplines communicate and implement solutions. To adopt a thriving SRE culture, organisations must:
a) Adopt new approaches to Risk Management.
b) Adapt governance processes.
c) Invest in hiring.
d) Nurture a collaborative workforce that’s well-versed in Engineering and operations.

Empower yourself to drive seamless collaboration, continuous integration, and accelerated software delivery with our Certified DevOps Professional Course. Register Now!
Roles of a Site Reliability Engineer
A Site Reliability Engineer plays a pivotal role in ensuring the reliability, availability, and performance of complex software systems and digital services. Their responsibilities span various domains, and their expertise is crucial in bridging the gap between development and operations. Here, we will delve into the critical roles of a Site Reliability Engineer:
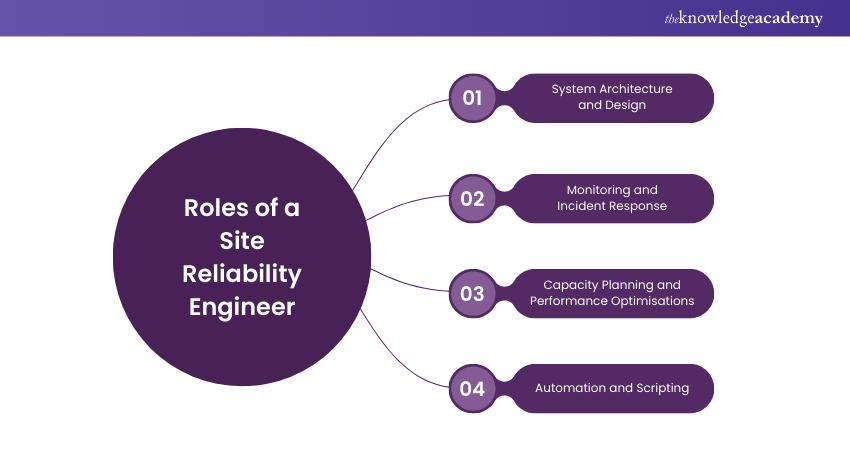
1) System Architecture and Design
The Site Reliability Engineer actively participates in software systems' design and architecture phases. They collaborate with development teams closely to ensure the systems are scalable, reliable and meet performance standards. By leveraging their understanding of software and infrastructure, these Engineers create a robust foundation for applications to operate efficiently and reliably.
Key Activities:
1) Collaborating with development teams to design scalable and fault-tolerant architectures.
2) Identifying potential bottlenecks and vulnerabilities in the system's design.
3) Implementing best practices for system resilience and high availability.
2) Monitoring and Incident Response
The Site Reliability Engineer is responsible for implementing effective monitoring solutions to track the health and performance of systems in real time. Monitoring allows them to identify anomalies and potential issues before they escalate into critical incidents. When incidents occur, they lead the response efforts, aiming to minimise downtime and swiftly restore services to regular operation.
Key Activities:
1) Implementing robust monitoring tools and strategies.
2) Setting up alerts and automated responses to address issues promptly.
3) Conducting post-incident reviews to continuously improve incident response processes.
Elevate your career with DevOps Certification Courses—empower yourself to streamline software development and operations seamlessly.
3) Capacity Planning and Performance Optimisation
Proactive capacity planning is a crucial aspect of Site Reliability Engineering. Engineers analyse system usage patterns, forecast growth, and ensure the infrastructure can handle increasing demand. Performance optimisation involves fine-tuning systems for optimal efficiency, ensuring that resources are utilised effectively to meet user demands.
Key Activities:
1) Planning for future capacity needs based on usage trends and growth projections.
2) Optimising system performance through efficient resource allocation and configuration.
3) Conducting load testing to identify and address performance bottlenecks.
4) Automation and Scripting:
Automation is at the core of Site Reliability Engineering. The Site Reliability Engineer leverages automation tools and scripting languages to streamline repetitive tasks, reduce manual errors, and enhance operational efficiency. By automating routine operations, they free up time to focus on different strategic initiatives and improvements.
Key Activities:
1) Developing scripts and automation tools for deployment, configuration, and maintenance tasks.
2) Implementing Infrastructure as Code (IaC) principles to manage and provision infrastructure.
3) Continuously seeking opportunities to automate operational workflows.
Master the essential skills to safeguard your development and operations pipeline by joining our Certified DevOps Security Professional Course!
Site Reliability Engineering Metrics
Site Reliability Engineers use numerous metrics to help track the consistency of service delivery and reliability of software systems. These metrics include:
1) Service level agreements (SLA): SLAs set the terms and conditions between a customer and service provider. These agreements dictate the following:
a) Level of performance
b) Agreed-upon indicators for measuring performance
c) Repercussions for failing to deliver services.
A standard service that's outlined in an SLA is uptime which is the amount of time a service is available.
2) Error budgets: This is a tool that SREs use to automatically reconcile the service reliability of a company with its pace of software development. Error budgets help with the following:
a) Establish a level of error risk that is in line with the service level agreements.
b) Help development teams and operations teams improve the stability and performance of services.
c) Help make data-driven decisions about deploying new features or applications
d) Maximise innovation by taking risks within acceptable limits.

3) Service level objectives (SLO): SRE teams help set service level objectives (SLOs) which is an agreed-upon performance target for a specific service over a specified period. SLOs define the expected status of services and enable stakeholders to manage particular services' health and meet SLAs.
4) Service level indicators (SLIs): SLOs are measured by service level indicators (SLIs), which are quantitative measurements presented as averages, percentages, or rates. They include the actual measurement of services such as:
a) Uptime.
b) Latency.
c) Throughput.
d) Error rates.
Unlock the power of container orchestration with Kubernetes Training and accelerate your expertise in managing and scaling containerised applications.
SRE and DevOps
SRE and DevOps are complementary strategies in Software Engineering that break down silos and lead to more reliable and efficient software delivery. Here are the key differences between the two:
1) DevOps teams answer the question: What should this software do?
2) SRE answer the question: How can this software be deployed and maintained so it works as needed?
3) DevOps teams prioritise making updates and deploying new features.
4) SRE practices protect the reliability of systems as they scale.
SREs provide DevOps teams with real-world data on software performance data, ensuring a balance of practical data to the theoretical world of Software Development.
What are the Four Golden Rules of SRE?
The four golden rules or signals of SRE are:
1) Latency: The response time for serving requests
2) Traffic: Measure of the demand on your system (in the form of requests per second).
3) Errors: How often requests fail.
4) Saturation: The fraction of resources, such as CPU and memory, utilised and available.
What Languages Does SRE Use?
Programming Languages frequently used by SREs include:
1) C and C++
2) Java
3) Python
4) Go
5) Perl
6) Ruby
Conclusion
In conclusion, the pivotal role of a Site Reliability Engineer and the principles of this field are indispensable for maintaining resilient digital infrastructures.Understanding What is Site Reliability Engineering and embracing SRE practices ensures optimal performance, availability, and reliability—All essential elements in today's dynamic web services landscape.
Transform your infrastructure with Chef Fundamentals Training—unlock the skills to automate, manage, and scale your IT environment efficiently.
Frequently Asked Questions
What is the Primary Role of a Site Reliability Engineer?

The primary role of a Site Reliability Engineer is to ensure the reliability, availability, and performance of web services and applications.They bridge the gap between development and operations by leveraging proactive practices to maintain a digital infrastructure that meets user expectations and business objectives.
How Does Site Reliability Engineering Differ From Traditional Operations or Development Roles?
SRE differs from traditional operations and development roles by emphasising a holistic approach. SRE combines Software Engineering with System Administration, focusing on automation, proactive monitoring, and collaboration to ensure reliability.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is the Knowledge Pass, and how Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various DevOps Courses, including Certified DevOps Professional Course, Certified Agile DevOps Professional Course, and Certified SecOps Professional Course. These courses cater to different skill levels, providing comprehensive insights into DevOps Vs SRE.
Our Programming & DevOps Blogs cover a range of topics related to DevOps, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your DevOps skills, The Knowledge Academy's diverse courses and informative blogs have you covered.
Upcoming Programming & DevOps Resources Batches & Dates
Date
 Python Course
Python Course
Python Course
Thu 9th Jan 2025
Python Course
Thu 13th Mar 2025
Python Course
Thu 12th Jun 2025
Python Course
Thu 7th Aug 2025
Python Course
Thu 18th Sep 2025
Python Course
Thu 27th Nov 2025
Python Course
Thu 18th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


