



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +44 1344 203999 and speak to our training experts, we may still be able to help with your training requirements.
Hadoop vs Spark: What's the Difference?
Eliza Taylor 03 January 2025Are you eager to study Hadoop and Spark, the two vital big data frameworks in the field of data science? Their differences are among the most popular doubts in the minds of aspirants. This blog will focus on the distinct features, capabilities, architecture, ease of use, and scalability of the Hadoop vs Spark topic.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

In the dynamic landscape of Big Data, two prominent open-source frameworks have evolved: one is Hadoop, and another one is Spark. Both are significant players in navigating the intricacies of Big Data Analytics effectively.
Understanding how Hadoop and Spark complement each other in the Big Data ecosystem is essential for Data Analysts who are seeking to harness the power of distributed and scalable platforms. In this blog, we will delve into the intricacies of these Hadoop vs Spark frameworks, exploring their differences, strengths, and potential synergies.
Table of Contents
1) What is Apache Hadoop?
2) What is Apache Spark?
3) Hadoop vs Spark: Key Differences
4) Hadoop and Spark Use Cases
5) Spark vs Hadoop: Understanding Their Complementary Roles
6) Conclusion
What is Apache Hadoop?
Apache Hadoop is a well-structured framework that allows for the distributed processing of large data sets across multiple clusters of computers using simple and straightforward programming models. It primarily comprises two main components: Hadoop Distributed File System (HDFS) and MapReduce.

1) HDFS: Hadoop Distributed File System (HDFS) is a distributed file system that provides high-throughput access to application data. It works by splitting the data into blocks and distributing them across multiple cluster nodes. In addition, it also replicates the blocks for fault tolerance and reliability.
2) MapReduce: It is a programming model that enables parallel processing of large data sets. As per the name, it consists of two phases: map and reduce. The map phase applies a user-defined function to each input key-value pair and produces a set of intermediate key-value pairs. In contrast, the reduced phase aggregates the intermediate values related to the same intermediate key and produces the final output.
Pros of Hadoop
In the domain of big data processing, organisations often evaluate different frameworks to meet their specific needs. While both Spark and Hadoop are prominent in this space, they serve distinct purposes and can work synergistically. Here is the list of Hadoop advantages described below:
a) Hadoop is highly scalable and can easily handle enormous petabytes of data on thousands of nodes.
b) Hadoop is cost-effective and can effectively run on commodity hardware.
c) It is reliable and, therefore, rarely suffers from systematic failures. It can recover from failures and errors.
d) Hadoop is flexible and can process structured, semi-structured, and unstructured data seamlessly and smoothly.
e) Hadoop is compatible and can integrate with various tools and frameworks, such as Hive, Pig, Sqoop, Flume, and Oozie.

Cons of Hadoop
Despite its widespread use, Hadoop has certain limitations that can impact its effectiveness in various scenarios. Here is the list of disadvantages of using Hadoop:
a) Hadoop is slow and can take a long time to process large amounts of data sets.
b) Hadoop is complex and requires a lot of configuration and tuning.
c) It is batch-oriented and cannot handle real-time or interactive analytics.
d) Hadoop is resource-intensive and consumes a lot of memory and disk space.
e) Despite being flexible, it is not suitable for iterative or complex algorithms, such as machine learning and graph processing.
Interested in gaining a deeper knowledge on Hadoop, refer to our blog on Hadoop Data Types
What is Apache Spark?
Apache Spark is defined as the framework that provides fast and general-purpose cluster computing. It extends the MapReduce model to support more types of computations, such as streaming, interactive, and graph processing. It majorly consists of four main components: Spark mlib, Spark SQL, Spark Streaming, and Spark GraphX.

a) Spark mlib: Spark Mlib is a scalable Machine Learning (ML) library for Apache Spark that provides common algorithms and utilities for data analysis and processing. It mainly supports Java, Scala, Python, and R languages.
b) Spark SQL: It is an Apache Spark component that provides an SQL-like interface for querying structured and semi-structured data. In addition, it also supports various data sources, such as Hive, Parquet, JSON, and JDBC.
c) Spark Streaming: Spark Streaming is a component that enables real-time data processing from various sources, such as Kafka, Flume, and Twitter. It also supports stateful and windowed operations, such as aggregations, joins, and sliding windows.
d) Spark GraphX: It is a component that enables graph processing and analysis on large-scale graphs. It also supports various graph algorithms, such as PageRank, connected components, and triangle counting.
Pros of Spark
Although Spark is a powerful framework for performing big data analytics. Therefore, it is important to consider the challenges it may present. Evaluating these disadvantages can provide valuable insights for users to maximise their proficiency in analytics capabilities. Here is the list of disadvantages of using Spark explained below:
a) Spark is fast and can process data up to 100 times faster than Hadoop in memory and ten times faster on disk.
b) Spark is easy and can be programmed in various languages, such as Scala, Python, Java, and R.
c) Spark is interactive and can support interactive shell and notebook environments, such as Spark Shell and Jupyter Notebook.
d) Spark is versatile and can support various types of analytics, such as batch, streaming, interactive, and graph processing.
e) Spark is suitable for iterative and complex algorithms, such as machine learning and graph processing.
Transform data into insights with our Apache Spark Training – sign up today!
Cons of Spark
Although Spark is a powerful framework for performing big data analytics. Therefore, it is important to consider the challenges it may present. Evaluating these disadvantages can provide valuable insights for users to maximise their proficiency in analytics capabilities. Here is the list of disadvantages of using Spark explained below:
a) Spark is memory-intensive and requires a lot of RAM to run in-memory computations.
b) Spark is not compatible with all the tools and frameworks that work with Hadoop, such as MapReduce, Hive, and Pig.
c) Spark is not reliable and can lose data in case of failures or errors.
d) Spark is not efficient and can generate a lot of shuffle and network traffic.
e) Spark is not flexible and cannot process unstructured or binary data, such as images and videos.
Hadoop vs Spark: Key Differences
As organisations increasingly adopt big data technologies, understanding the distinctions between various frameworks becomes essential. Here are the key differences between Hadoop vs Spark that highlight their unique strengths and capabilities:
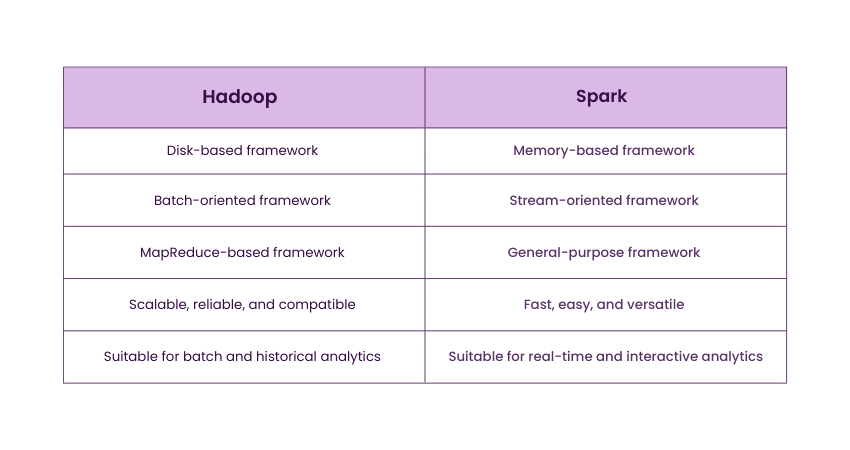
Storage Mechanism
Hadoop is a disk-based framework that reads and writes data from and to the disk. In contrast, Spark is a memory-based framework that caches and processes data in memory for a faster and more responsive performance, particularly for in-memory processing.
Processing Model
Hadoop is a batch-oriented framework that processes data in batches, whereas Spark is designed for both batch and stream processing. This makes Spark more suitable for real-time and interactive analytics with APIs.
Programming Paradigms
Hadoop primarily relies on the MapReduce programming model, while Spark offers a general-purpose framework supporting multiple programming paradigms. These include streaming, interactive, and graph processing, further enhancing its versatility and power.
Secure your future in Data Analytics with our Hadoop Big Data Certification Course – sign up now!
Hadoop and Spark Use Cases
As organisations strive to leverage big data for strategic decision-making, understanding the practical applications of different frameworks is crucial. Below are the use cases of Hadoop and Spark that illustrate their strengths in addressing various data processing needs. Here are the use cases of Hadoop and Spark:
Hadoop Use Cases
Hadoop excels deeply in processing large volumes of historical data, making it ideal for data archiving and batch-processing tasks. Organisations often use this key framework for data warehousing, where they can store and analyse massive datasets across distributed systems. Additionally, Hadoop is widely adopted for log processing and analysing unstructured data, such as social media content and web logs.
Spark Use Cases
Spark is well-suited for real-time data processing and analytics that enable organisations to derive meaningful insights from continous streaming data. Additionally, its capabilities in Machine Learning make it a popular choice for developing predictive models and performing complex data transformations. Furthermore, Spark's versatility allows it to integrate seamlessly with various data sources, facilitating interactive data exploration and analysis.
Spark vs Hadoop: Understanding Their Complementary Roles
As organisations seek to maximise their data processing capabilities, understanding how different frameworks can work together is essential. Below are the complementary roles of Hadoop and Spark in the big data ecosystem: Here are the complementary roles of Hadoop and Spark:
1) Data Processing Frameworks
Hadoop: Primarily a batch processing framework using the MapReduce paradigm.
Spark: Designed for both batch and real-time data processing, offering in-memory computation for faster performance.
2) Speed
Hadoop: Slower due to disk-based storage and processing.
Spark: Significantly faster, leveraging in-memory data storage, which reduces latency.
3) Ease of Use
Hadoop: Requires more complex coding and setup, especially for MapReduce jobs.
Spark: Provides high-level APIs in multiple languages (Python, Scala, Java), making it more user-friendly.
4) Data Storage
Hadoop: It utilises the Hadoop Distributed File System (HDFS) for storage.
Spark: It can work with HDFS but also integrates with various data sources like NoSQL databases, cloud storage, and more.
5) Use Cases
Hadoop: Best suited for large-scale data processing tasks that can tolerate latency.
Spark: Ideal for applications requiring real-time analytics, machine learning (ML), and interactive data processing.
6) Ecosystem Integration
Hadoop: Part of a larger ecosystem including tools like Hive, Pig, and HBase.
Spark: Can run on top of Hadoop, utilising HDFS while also integrating with other data sources and tools.
7) Resource Management
Hadoop: It uses YARN for resource management.
Spark: It can run on YARN but also supports standalone mode and Kubernetes for resource management.
Transform insights into actionable strategies- sign up for our Big Data Analytics & Data Science Integration Course now!
Conclusion
We hope you understood the Hadoop vs Spark differences. Integrating these two powerhouse frameworks and knowing their differences allows data analysts to handle diverse scenarios smoothly and helps achieve a comprehensive approach to Big Data Analytics. The key lies in recognising the distinctive roles each plays and seamlessly integrating them for a harmonious and powerful Data Analytics ecosystem.
Empower your career in Big Data management with our comprehensive Hadoop Administration Training – elevate your journey now!
Frequently Asked Questions
Which Framework Should I Learn First Between Hadoop and Spark?

Choosing between Hadoop and Spark depends on your goals. For batch processing and large datasets, start with Hadoop. For real-time processing and advanced analytics, Spark may be better. Both frameworks are valuable for a big data career.
What is the Difference Between Hadoop, Spark and Kafka?
Hadoop, Spark, and Kafka play distinct roles in data processing: Hadoop is for batch processing and large dataset analysis, Spark provides fast, in-memory real-time analytics, and Kafka enables high-throughput data streaming between applications. Each has strengths suited to specific use cases.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Big Data and Analytics Training, including Hadoop Big Data Certification, Apache Spark Training, and Big Data Analytics & Data Science Integration Course. These courses cater to different skill levels, providing comprehensive insights into Top 40 Apache Spark Interview Questions and Answers.
Our Data, Analytics & AI Blogs cover a range of topics related to data management, analytics techniques, and artificial intelligence applications, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your data analytics and AI skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Hadoop Big Data Certification
Hadoop Big Data Certification
Hadoop Big Data Certification
Thu 16th Jan 2025
Hadoop Big Data Certification
Thu 6th Mar 2025
Hadoop Big Data Certification
Thu 22nd May 2025
Hadoop Big Data Certification
Thu 24th Jul 2025
Hadoop Big Data Certification
Thu 11th Sep 2025
Hadoop Big Data Certification
Thu 11th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


