



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on 01344 203999 and speak to our training experts, we may still be able to help with your training requirements.
Characteristics of Big Data: Types and Examples
Sienna Roberts 12 July 2023Interested in the Characteristics of Big Data? Defined by immense volume, variety, and velocity, Big Data requires advanced processing and storage solutions. This blog dives into key traits like veracity, value, and variability. Unlock the secrets of Big Data and revolutionise your data strategies today for success!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Have you ever wondered how companies like Google and Amazon manage to process and analyse massive amounts of data in real time? The answer lies in the Characteristics of Big Data. Let's explore what makes Big Data unique and how it can benefit your organisation.
Big Data has revolutionised how organisations collect, manage, and analyse vast amounts of data. But what exactly makes Big Data so powerful? What are the Characteristics of Big Data that set it apart and make it indispensable for modern businesses? Join us as we dive into the fascinating world of Big Data and uncover its defining characteristics that drive the digital age.
Table of Contents
1) A brief introduction to Big Data
2) What are the Characteristics of Big Data?
a) Velocity
b) Volume
c) Value
d) Variety
e) Veracity
f) Validity
g) Volatility
h) Visualisation
3) What are the Main Types of Big Data?
4) What are the main components of Big Data?
5) Conclusion
A brief introduction to Big Data
Big Data has emerged as a game-changer in the modern era, transforming the way organisations collect, manage, and analyse vast amounts of data. It refers to the huge volume of structured, semi-structured, and unstructured data that inundates businesses and society.
Moreover, Big Data holds immense value, offering insights that can drive innovation, improve decision-making, and fuel growth for the organisation. Harnessing the power of Big Data has become crucial for businesses seeking to stay competitive in the modern digital era. Now, we will move on to exploring the key Characteristics of Big Data Analytics, as well as its fundamental components.

What are the Characteristics of Big Data?
The key Characteristics of Big Data Analytics can be summarised as follows:
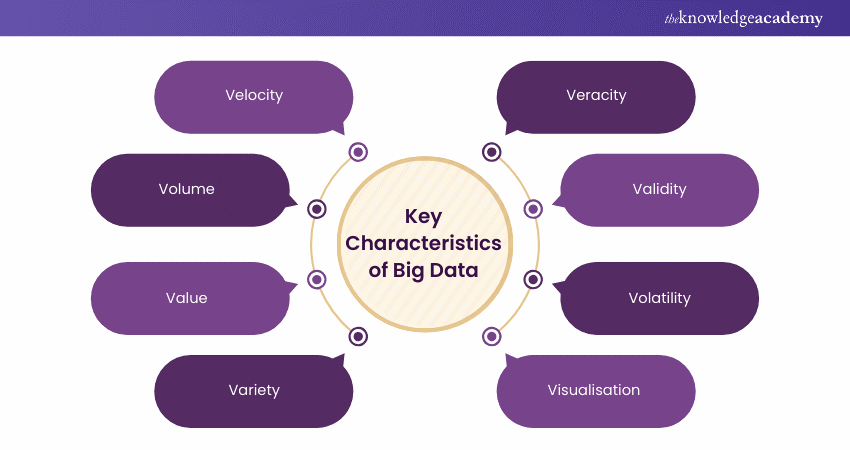
a) Velocity
Velocity is one of the Key Characteristics of Big Data. In the context of Big Data, velocity refers to the speed at which data is generated, processed, and analysed. With the advancement of technology and the increasing interconnectivity of systems, data is generated at an unprecedented rate.
Social media updates, sensor readings, online transactions, and other sources produce a continuous stream of data that requires real-time or near-real-time processing. The ability to handle high-velocity data allows organisations to respond swiftly to changing circumstances and make data-driven decisions in a timely manner.
b) Volume
Volume is another primary Big Data Characteristics. Volume represents the vast amount of data that is generated and accumulated in the realm of Big Data. The sheer scale of data is massive, often reaching terabytes, petabytes, or even exabytes.
The growth in data volume is attributed to the expansion of digital technologies, such as social media platforms, Internet of Things (IoT) devices, and online transactions. Dealing with such enormous volumes of data necessitates specialised infrastructure, storage systems, and processing capabilities to manage, store, and analyse the data effectively.
c) Value
The value of Big Data lies in its potential to derive meaningful insights and create value for organisations. By analysing large and diverse datasets, organisations can uncover patterns, correlations, and trends that can lead to valuable insights.
These insights, in turn, can drive informed decision-making, optimise business processes, improve customer experiences, and foster innovation. The value of Big Data lies not only in its quantity but also in the quality of the insights derived from it.
d) Variety
Variety is the third V when it comes to the Four V’s of Big Data. Big Data comprises various data types, including structured, semi-structured, and unstructured data. Structured data refers to data that is organised and stored in a predefined format, such as databases and spreadsheets.
Semi-structured data has some organisational structure but does not adhere to a strict schema, such as XML or JSON files. Unstructured data, on the other hand, lacks a predefined structure and includes text documents, social media posts, images, videos, and audio files.
e) Veracity
Variety makes up the four V’s of Big Data Characteristics. Veracity refers to the quality, accuracy, and reliability of the data. Big Data often originates from various sources, and the data may vary in terms of accuracy, completeness, and consistency.
Ensuring data veracity involves addressing data quality issues, performing data cleansing and validation processes, and establishing mechanisms to assess the reliability and trustworthiness of the data. High-quality and reliable data is essential for making sound decisions and drawing meaningful insights from Big Data.
Level up your data science expertise and harness the power of Big Data analytics with our Big Data Analytics & Data Science Integration Course – sign up now!
f) Validity
Validity in the context of Big Data pertains to the extent to which the data accurately represents the intended information or concept. It involves assessing whether the collected data aligns with the desired objectives and whether it is relevant and reliable for analysis.
Validity ensures that the data used for analysis is appropriate and fit for the intended purpose, reducing the risk of drawing erroneous conclusions or making flawed decisions based on inaccurate or irrelevant data.
g) Volatility
Volatility refers to the rate at which data changes or becomes obsolete. Big Data is often characterised by its dynamic nature, with data continuously updated, modified, or replaced. It is important for organisations to stay up to date with the latest data and adapt their analysis processes accordingly.
Managing data volatility involves implementing strategies to capture and integrate new data, handle data updates in a timely manner, and address the challenges associated with data that may quickly become outdated.
h) Visualisation
Visualisation plays an important role in Big Data analysis. It involves representing data in a visual format, such as charts, graphs, maps, or interactive dashboards. Visualising Big Data allows analysts and decision-makers to comprehend complex patterns, relationships, and trends more easily.
Organisations can effectively communicate insights and findings to a broader audience by presenting data visually. This facilitates understanding and enables stakeholders to make informed decisions based on the visualised information.
Enhance your career with Big Data Architecture Training - register now for in-depth, hands-on learning!
What are the Main Types of Big Data?
The main types of Big Data are:
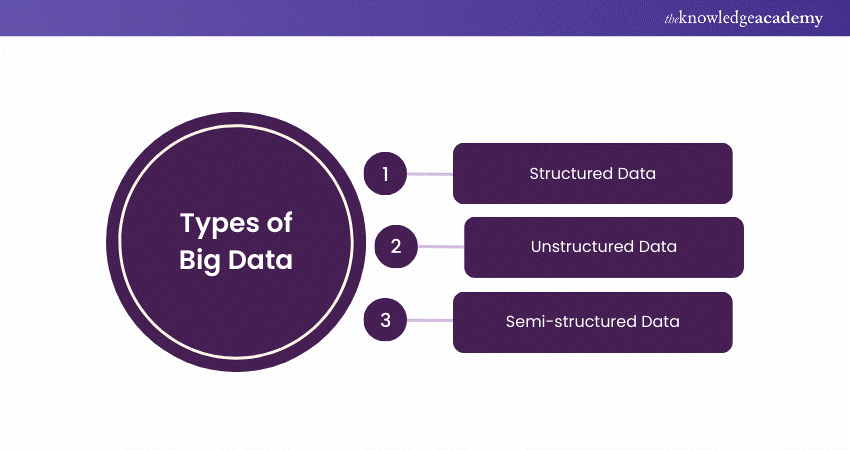
1) Structured Data
Structured data is organised in a predefined manner, often in tabular formats, making it easy to analyse and sort. Each field in structured data is distinct and can be used individually or in combination with other fields. This predefined nature allows for quick data retrieval from various database locations, making structured data highly valuable.
2) Unstructured Data
Unstructured data lacks predefined organisational properties and is not easily interpreted by standard databases or data models. It constitutes the majority of Big Data and includes information such as dates, numbers, and facts.
Unstructured data includes video and audio recordings, mobile activities, satellite imaging, and NoSQL databases. Photos published on social networking platforms such as Facebook and Instagram, as well as videos seen on YouTube, contribute significantly to unstructured data.
3) Semi-structured Data
Semi-structured data consists of both structured and unstructured data. It possesses some characteristics of structured data but does not conform to relational databases or formal data models. Examples of semi-structured data include JSON and XML files, which have some organisational properties but do not fit neatly into traditional data structures.
Gain expertise in Hadoop Big Data - join now for our in-depth Hadoop Big Data Certification Course and advance your career!
What are The Main Components of Big Data?
The following section of the blog will expand on the main components of Big Data:
a) Ingestion
Ingestion is a fundamental component of Big Data that involves the process of collecting and acquiring data from various sources. It encompasses the mechanisms and techniques used to capture data and bring it into the Big Data infrastructure for further processing and analysis.
Ingestion can involve real-time streaming of data, batch processing of data in regular intervals, or a combination of both. It includes activities such as data extraction, data cleansing, and data transformation to ensure that the acquired data is accurate and usable for subsequent stages.
b) Storage
Storage is a critical component of Big Data infrastructure that involves the storage and management of vast amounts of data. Given the enormous volume of data generated in the Big Data ecosystem, traditional storage systems may not be capable of handling the scale and complexity of the data.
Big Data storage solutions often utilise distributed file systems or NoSQL databases that provide scalability, fault tolerance, and efficient data retrieval. These storage systems are designed to handle the velocity, volume, and variety of Big Data while ensuring data integrity and durability.
c) Analysis
An analysis is a core component of Big Data that focuses on extracting meaningful insights and valuable information from the data. It involves applying various techniques to uncover patterns, trends, correlations, and other valuable information hidden within the data.
Big Data analysis encompasses descriptive, diagnostic, predictive, and prescriptive analytics approaches. Descriptive analytics helps in understanding what has happened in the past. Diagnostic analytics explores why it happened, predictive analytics forecasts future outcomes, and prescriptive analytics suggests actions to optimise results.
d) Consumption
Consumption refers to the utilisation of the analysed Big Data insights to derive value and make informed decisions. The consumption stage involves the presentation and dissemination of the analysed data and insights to relevant stakeholders. This can include generating reports, creating visualisations, building interactive dashboards, and developing data-driven applications.
By consuming the analysed data, organisations can gain actionable insights that can drive strategic decisions, operational improvements, targeted marketing campaigns, customer personalisation, and other value-adding initiatives.
Conclusion
Mastering the Characteristics of Big Data—volume, variety, velocity, veracity, and value—unleashes its true power. By harnessing these elements, your organization can revolutionise data processing, make smarter decisions, and outpace competitors. Dive into Big Data and transform your business landscape today!
Master Big Data Analysis techniques and drive innovation in your organization - sign up for our Big Data Analysis Course now!
Frequently Asked Questions
What are the Three Vs Used to Characterise Big Data?

The 3Vs used to characterise Big Data are Volume, Variety, and Velocity. Volume refers to the massive amount of data, Variety indicates the diverse types of data, and Velocity describes the rapid generation and processing of data.
What are Some Examples of Big Data?
Examples of Big Data include social media posts, sensor data from IoT devices, financial transaction records, healthcare records, and large-scale e-commerce transaction logs.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 17 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Big Data and Analytics Training, including Big Data Analysis, Hadoop Big Data Certification, Big Data Architecture Training and Big Data And Hadoop Solutions Architect. These courses cater to different skill levels, providing comprehensive insights into Big Data Analyst Job Description.
Our Data, Analytics & AI Blogs cover a range of topics related to Big Data, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Big Data skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Hadoop Big Data Certification
Hadoop Big Data Certification
Hadoop Big Data Certification
Thu 16th Jan 2025
Hadoop Big Data Certification
Thu 6th Mar 2025
Hadoop Big Data Certification
Thu 22nd May 2025
Hadoop Big Data Certification
Thu 24th Jul 2025
Hadoop Big Data Certification
Thu 11th Sep 2025
Hadoop Big Data Certification
Thu 20th Nov 2025
Hadoop Big Data Certification
Thu 11th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


