



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +44 1344 203 999 and speak to our training experts, we may still be able to help with your training requirements.
Resilient Distributed Datasets: An Introduction
Sophia Ellis 27 December 2023Explore Resilient Distributed Datasets (RDDs) in this blog. Learn their role in distributed computing, especially within Apache Spark, and their significance in big data. Covers RDD creation, functions, and optimisation for data scientists and engineers seeking efficiency in Big Data processing.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Today, where the digital universe is expanding at an exponential rate, how can we efficiently process and analyse data on such an immense scale? This is where Resilient Distributed Datasets, or RDDs, come into the picture. They represent a fundamental concept that has revolutionised the way we handle and manipulate large datasets.
In this blog, we will discuss the characteristics, use cases, advantages and challenges of Resilient Distributed Datasets. Read more!
Table of Contents
1) Characteristics of RDD
2) Use cases of RDD
3) Advantages of RDD
4) Limitations of RDDs
5) Conclusion
Characteristics of RDD
Resilient Distributed Datasets have some key characteristics that make them unique and effective for big data processing. Let's explore these characteristics in this section:
a) Resilience: RDDs are resilient because they can recover data lost during processing due to hardware failures. They do this by keeping a record of the operations applied to the data.
b) Distribution: RDDs are distributed across multiple computers in a cluster, which means that they can handle large amounts of data by breaking it into smaller units that can be processed in parallel.
c) Immutability: RDDs are immutable, meaning once created, their data cannot be changed. Instead, any operation on an RDD creates a new one, ensuring data consistency.
d) In-memory computation: RDDs can store data in memory, allowing for faster data processing compared to traditional disk-based systems.
e) Transformations and actions: RDDs support two types of operations. Transformations create new RDDs by applying functions to existing data, while actions return results or save data.
f) Lazy evaluation: RDDs use lazy evaluation, which means they only perform transformations once an action is called
g) Parallel processing: RDDs can be divided into smaller partitions and processed in parallel on different computers, making them highly efficient for parallel data processing.
Spark your data journey today with our Apache Spark Training and ignite your big data career!
Use cases of RDD
Resilient Distributed Datasets are versatile data structures used in various real-world scenarios. Here are some simplified use cases of RDDs:
a) Data exploration: RDDs are handy for exploring large datasets, allowing data scientists to analyse and extract insights from vast volumes of information.
b) Machine Learning: RDDs play a crucial role in big data Machine Learning. They enable the parallel processing of data required for training and deploying Machine Learning models at scale.
c) Real-time processing: When dealing with continuous streams of data in real-time applications, such as social media updates or sensor data, RDDs facilitate the efficient handling of incoming data.
d) Text analysis: For natural language processing tasks, like sentiment analysis or language translation, RDDs can process and transform text data in parallel.
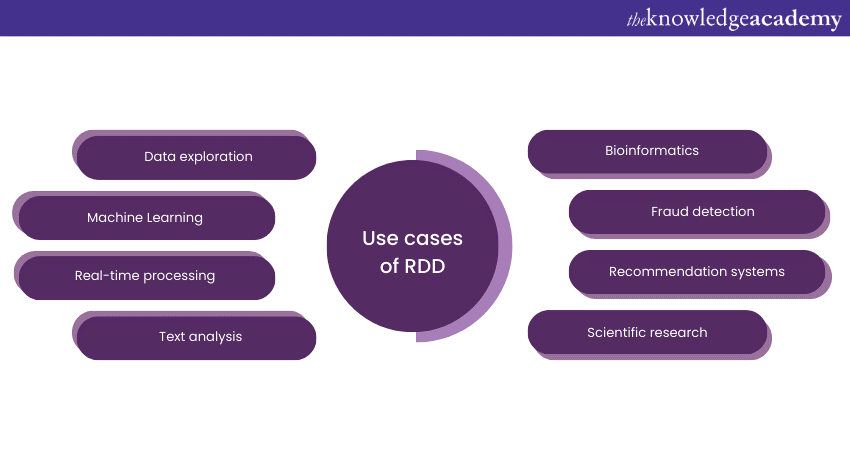
e) Bioinformatics: In genomics research, where enormous datasets are generated from DNA sequencing, RDDs assist in the analysis and interpretation of genetic data.
f) Fraud detection: In the finance industry, RDDs can be employed to process large volumes of transactions and identify suspicious patterns indicative of fraud.
g) Recommendation systems: E-commerce websites and streaming platforms use RDDs to analyse user behaviour and suggest products or content based on their preferences.
h) Scientific research: In various scientific fields, RDDs help process experimental data, simulations, or observations on a large scale.
Unlock the power of big data with our Big Data Architecture Training. Dive into the future of insights and innovation.
Advantages of RDD
Resilient Distributed Datasets (RDDs) have several advantages in plain language:
a) Data safety: RDDs are good at keeping your data safe. If a computer in your data processing group fails, RDDs can still give you your data without any loss or damage.
b) Fast data processing: RDDs can help you process data quickly because they keep data in the computer's memory, which is much faster than reading it from a disk.
c) Custom data work: With RDDs, you can do exactly the kind of work you want on your data. You're not limited to fixed methods or operations.
d) Data flexibility: RDDs can work with different types of data. It doesn't matter if your data is neatly organised or messy; RDDs can handle it.
e) Big scalability: You can make RDDs work on big data just as easily as small data. You can add more computers to help them work faster when you need to.
f) High compatibility: RDDs work smoothly with other parts of Apache Spark, a big data framework. This makes it easy to build big data applications.
Challenges of RDD
RDDs are a powerful data processing tool, but they do come with certain challenges and limitations. These challenges are discussed below:
a) Complexity of operations: RDDs require a deeper understanding of data processing concepts, which can make them challenging for newcomers to big data processing.
b) Performance overheads: The fact that RDDs can't be changed once they're created means that every time you want to do something different with your data, you have to create a completely new RDD.
c) Memory usage: While RDDs promote in-memory computation for speed, they can consume a large amount of memory when handling large datasets, potentially leading to memory-related issues.
d) Data serialisation: Serialisation of data when passing it between nodes in a cluster can be a bottleneck, affecting performance.
e) Narrow and wide transformations: Understanding and using the right types of transformations (narrow vs. wide) can be challenging, as wide transformations require shuffling data across partitions, which can be resource intensive.
f) Lack of optimisation: RDDs do not benefit from query optimisation techniques used in relational databases. This means that query performance may not be as efficient for structured data.

Conclusion
In this blog, we learned the proven track record of Resilient Distributed Datasets (RDDs), which are pivotal assets in the world of Big Data processing. With their remarkable resilience, parallel processing capabilities, and support for custom data operations, RDDs have empowered organisations to tackle the most significant data challenges efficiently. We hope you enjoyed reading our blog.
Transform Data into Insights by joining our courses on Big Data and Analytics Training. Join now!
Frequently Asked Questions
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Apache Spark Training
Apache Spark Training
Apache Spark Training
Thu 23rd Jan 2025
Apache Spark Training
Thu 10th Apr 2025
Apache Spark Training
Thu 8th May 2025
Apache Spark Training
Thu 17th Jul 2025
Apache Spark Training
Thu 4th Sep 2025
Apache Spark Training
Thu 13th Nov 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


