



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on + 800 908601 and speak to our training experts, we may still be able to help with your training requirements.
Hashing in DBMS: Definition, Type, & Functions
Scarlett Adams 19 March 2025Hashing in DBMS efficiently maps data to specific locations, enabling quick retrieval and eliminating the need for exhaustive searches. This blog explores how hashing works, its types, and how it transforms Data Management for smoother, faster operations. Keep reading to uncover the power of this essential technique!
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.

In today’s data-driven world, efficient data retrieval is crucial for maintaining performance and productivity. When it comes to storing data in a database, time is precious, and inefficient data searches can slow down things. Hashing in DBMS maps data to specific locations, enabling instant retrieval and eliminating exhaustive searches. But how does it ensure such efficiency?
In this blog, we’ll take you through the fascinating world of Hashing in DBMS. We’ll cover how it works, its key properties, and the types of hashing techniques that optimise data storage and retrieval. By the end, you’ll see how hashing makes databases work like magic!
Table of Contents
1) What is Hashing in DBMS?
2) Properties of Hashing in DBMS
3) Working of Hash Function in DBMS
4) Types of Hashing
5) Conclusion
What is Hashing in DBMS?
Hashing in Database Management System (DBMS) is a technique that transforms large datasets into smaller, manageable hash values or codes. These codes act as identifiers, enabling efficient data storage and retrieval in a database.
A hash function is applied to a record’s key, generating an index that determines where the data is stored. This eliminates the need for searching through the entire dataset, making operations faster and more efficient. Hashing maps data to specific indexes, enabling fast access and retrieval, which boosts database performance, especially with large datasets.

Properties of Hashing in DBMS
Several key properties define the effectiveness of Hashing in DBMS:
a) Uniform Distribution: A good hashing function distributes records uniformly across the database. If the distribution is not uniform, data will pile up in certain areas (also known as clustering), making retrieval inefficient.
b) Deterministic: Hashing is deterministic, meaning the same input will always result in the same hash value. This property ensures that data can be retrieved from the same index every time, which is critical for consistency in databases.
c) Minimal Collisions: Collisions occur when two keys map to the same index. A robust hashing function minimises these collisions by ensuring a unique index for each key or by efficiently handling collisions through techniques like chaining or open addressing.
d) Efficiency: Hashing must be computationally efficient, especially when dealing with large datasets. The process of computing a hash value and indexing data should not take too much time or resources.
e) Expandable: Hashing in DBMS should be able to accommodate growing datasets. Methods like dynamic hashing are designed to expand as more data is added, ensuring continued performance without the need for massive restructuring.
Start your journey into Database Management and master foundational skills with expert Introduction to Database Training – sign up now!
Working of Hash Function in DBMS
Here’s an overview of how the hash function operates in a DBMS to efficiently manage data storage and retrieval:
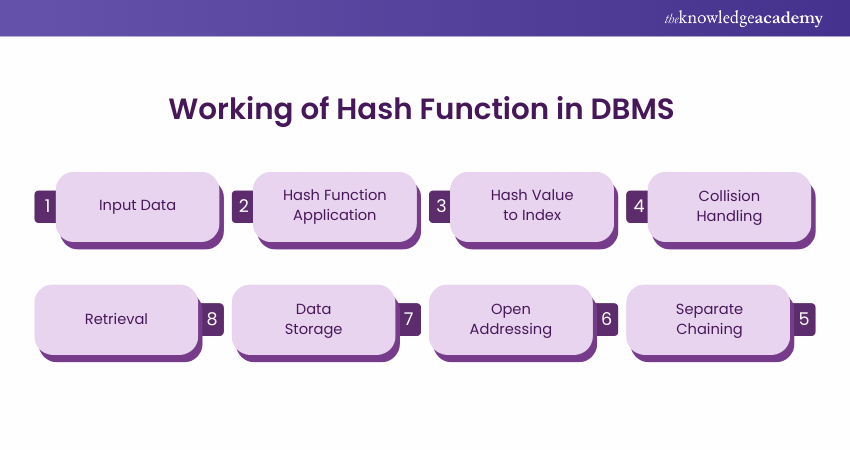
1) Input Data: The DBMS receives a data item (e.g., a record) that needs to be stored or retrieved.
2) Hash Function Application: The DBMS applies a hash function to the data item. This produces a hash value.
3) Hash Value to Index: The hash value is used as an index into the hash table. The hash table is typically an array of buckets or slots.
4) Collision Handling: If two or more data items produce the same hash value, a collision occurs. To handle collisions, various techniques are used:
5) Separate Chaining: Each bucket stores a linked list of data items that hash to that bucket.
6) Open Addressing: When a collision occurs, the DBMS searches for an empty slot using a probing strategy (e.g., linear probing, quadratic probing).
7) Data Storage: The data item is stored in the corresponding bucket of the hash table.
8) Retrieval: To retrieve a data item, the DBMS applies the hash function to the search key. The resulting hash value is used to locate the bucket where the data item is stored. The DBMS then searches the bucket (or linked list) for the desired item.
Master Redis Cluster Database skills and boost your Data Management efficiency with our Redis Cluster Database Training today!
Types of Hashing
In DBMS, there are two primary hashing techniques: Static Hashing and Dynamic Hashing. Let’s take a closer look at each method and their properties:
1) Static Hashing
In static hashing, the hash function consistently maps a key to the same bucket’s address. For instance, consider a record with an employee_id = 107 and a hash function mod-5. The function operates as H(x) % 5, where x = id, resulting in:
H(107) % 5 = 1
This means the data record will be stored or retrieved from the 1st bucket (or 1st index) in the hash table.
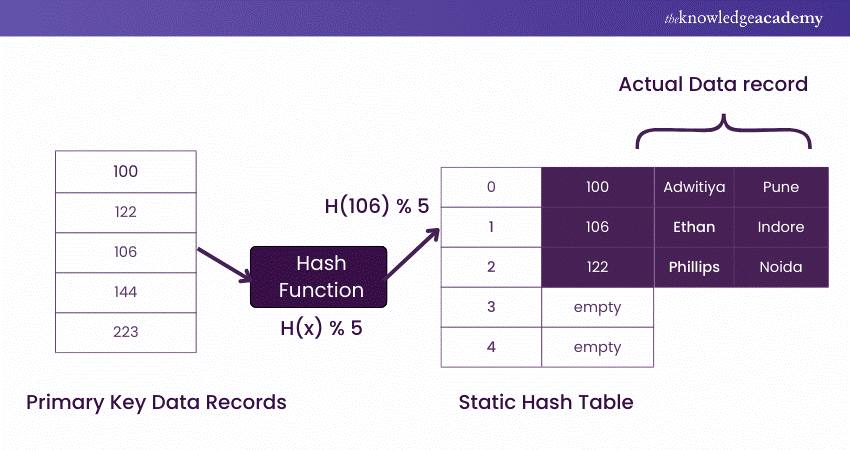
Static Hashing Technique Example:
The primary key is input into the hash function, which produces a hash index (or bucket address) where the actual data record is stored on the disk block.
Key Properties of Static Hashing:
a) Fixed Buckets: The number of buckets remains constant, determined at the beginning. Although chaining can help resolve some collisions, it’s not highly effective when the database size fluctuates.
b) Simple Hash Function: Usually, a basic hash function (such as modulo) is used to map records to buckets.
c) Efficiency for Fixed Data Size: Static hashing is very efficient when the data size is known and consistent.
d) Inefficiency with Dynamic Data: It becomes inefficient if the data size frequently changes, leading to collisions, bucket overflow, and underutilised buckets.
Collision Resolution in Static Hashing:
To handle bucket overflow, techniques like chaining and open addressing are used:
a) Chaining: The hash table is implemented using an array of nodes, where each bucket is linked to a chain of records. If the hash function produces the same index for multiple records, new nodes are added to the chain within the bucket. However, if the hash function generates the same index repeatedly, this leads to bucket skew, leaving some buckets underutilised.
b) Open Addressing (Closed Hashing): This method addresses collisions by finding the next available empty slot to store the data. Techniques such as linear probing, quadratic probing, and double hashing are employed.
2) Dynamic Hashing
Dynamic hashing, also known as extendible hashing, adapts to changing database sizes by dynamically adding or removing buckets. As the number of records fluctuates, dynamic hashing adjusts the size of the hash table accordingly, ensuring efficient storage and retrieval.
Key Properties of Dynamic Hashing:
1) Variable Bucket Size: Buckets can grow or shrink as needed, allowing for flexibility in accommodating data changes.
2) Collision Minimisation: Dynamic hashing improves performance by reducing collisions and ensuring an even distribution of records.
3) Main Components: Dynamic hashing involves data buckets, a flexible hash function, and directories.
a) Flexible Hash Function: This hash function generates dynamic values that change based on database needs.
b) Directories: These containers store pointers to buckets. When issues like bucket overflow arise, bucket splitting is used to maintain efficient data access.
4) Global Depth: The global depth represents the number of bits in each directory ID. As the dataset grows, the global depth increases, allowing more records to be handled efficiently.
Working of Dynamic Hashing:
For example, if the global depth (k) is 2, keys are mapped to hash indices based on the first 2 bits of their binary values. This results in 4 possible values: 00, 01, 10, and 11.
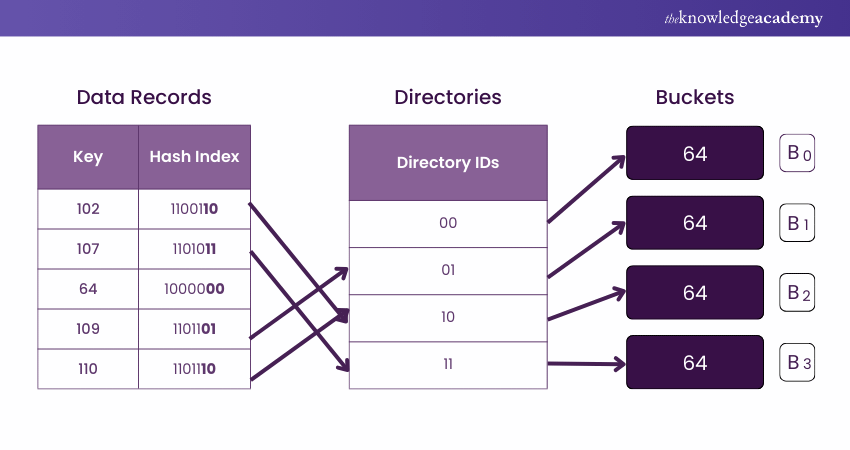
As illustrated in the dynamic hashing diagram, the k bits from the least significant bits (LSB) are used to map the key to its corresponding bucket through the directory IDs. The hash index points to directories, and the k bits from the directory ID are used to map the record to the appropriate bucket. Each bucket holds the data corresponding to the ID values converted to binary.
Dynamic hashing is particularly effective in large, evolving databases, offering scalability and efficiency while minimising collisions.
Learn essential Relational Databases & Data Modelling Training and strengthen your expertise in relational databases today!
Conclusion
Hashing in DBMS is the key to unlocking faster, more efficient Data Management. By mapping data directly to specific locations, it speeds up retrieval and eliminates time-consuming searches. Whether your database is large or growing, hashing ensures smooth operations, keeping everything running efficiently and seamlessly.
Elevate your database skills with expert Database Training and unlock limitless career opportunities!
Frequently Asked Questions
How to Hash Data in Excel?
To hash data in Excel, you can use a custom formula or VBA code. Excel doesn’t have a built-in hash function, so a common approach is using MD5 or SHA algorithms via VBA to generate hash values for data entries.
How is Data Stored in Hash Table?
In a hash table, data is stored by applying a hash function to a key, which generates an index. This index points to a specific location (bucket) in the table where the data is stored for efficient retrieval.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Database Training, including Introduction to Database Training, Relational Databases & Data Modelling Training and GraphQL Database Training With React. These courses cater to different skill levels, providing comprehensive insights into Deadlock in DBMS.
Our Programming & DevOps Blogs cover a range of topics related to DBMS, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Programming and DevOps skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Programming & DevOps Resources Batches & Dates
Date
 Introduction to Database Training
Introduction to Database Training
Introduction to Database Training
Fri 2nd May 2025
Introduction to Database Training
Fri 29th Aug 2025
Introduction to Database Training
Fri 3rd Oct 2025
Introduction to Database Training
Fri 5th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


