



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on + 800 908601 and speak to our training experts, we may still be able to help with your training requirements.
Machine Learning Methods: An Ultimate Guide
Sophia Ellis 29 August 2023Embark on a journey through the realm of "Machine Learning Methods: An Ultimate Guide." Uncover the vast landscape of various machine learning techniques, from the fundamentals of supervised learning to deep learning. Whether you're a beginner or an expert, this comprehensive blog is your key to understanding and mastering the diverse world of machine learning.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Machine Learning is a fast-growing subfield of Artificial Intelligence. It empowers computers to learn from data and improve performance without explicit programming. It encompasses diverse Machine Learning Methods, enabling groundbreaking applications in various domains.
According to PayScale, the average pay of a Machine Learning Engineer in the UK is about £52,218 annually. If you are interested in pursuing a career in this field, then you should learn about various methods used in Machine Learning. In this blog, you will learn about various Machine Learning Methods and their transformative impact.
Table of Contents
1) Various Machine Learning Methods
a) Supervised learning
b) Decision Trees and Random Forests
c) Support Vector Machines (SVM)
d) Naive Bayes classifier
e) Unsupervised learning
f) Semi-supervised learning
g) Reinforcement learning
h) Deep learning
i) Ensemble learning
j) Anomaly detection
k) Transfer learning
2) Conclusion
Various Machine Learning Methods
Machine Learning Methods encompass diverse algorithms, techniques, and statistical models that enable computers to learn from data, make predictions, and solve complex problems. Let's explore the different methods of Machine Learning:
Supervised learning
Supervised learning is one of the Machine Learning Methods which involves learning from labelled data. The algorithm learns to map fetched data to known output labels, allowing it to make predictions on new, unseen data. This method finds extensive use in tasks:
a) Image classification
b) Speech recognition
c) Natural language processing
Here, the algorithm learns from the training data by mapping input features to their corresponding output labels. During the training process, the algorithm adjusts its internal parameters to minimise the prediction errors, ultimately improving its ability to generalise to new data.

Decision Trees and Random Forests
Decision Trees and Random Forests are powerful algorithms used for both classification and regression tasks in Machine Learning. They are part of the supervised learning family and have found extensive applications in various fields due to their simplicity, interpretability, and high accuracy.
How Decision Trees make decisions?
When presented with new data, decision trees traverse from the origin node to a specific leaf node by applying the attribute tests based on the feature values of the input data. At each internal node, the decision tree checks if the data satisfies the condition defined by the test.
Depending on the result of the test, the algorithm follows the corresponding branch until it reaches a leaf node, which represents the predicted class label or regression value.
Support Vector Machines (SVM)
Support Vector Machines is a powerful and versatile Machine Learning Algorithm primarily used for classification tasks. It is well-known for its ability to handle complex datasets and effectively separate data points belonging to different classes. SVM has found applications in various domains, including image recognition, text classification, and bioinformatics.
Using SVM for classification and regression tasks
SVM is commonly used for classification, aiming to find the optimal hyperplane that best separates data points belonging to different classes. The hyperplane is chosen to maximise the margin, which is the distance between the hyperplane and the closest data points (called support vectors) from each class.
The idea is to create a decision boundary as far away from the data points as possible, reducing the risk of misclassification on new, unseen data.
SVM can be adapted for regression tasks to predict continuous values instead of discrete classes. This is achieved by modifying the SVM algorithm to find a hyperplane that best fits the data while allowing some error within a specified tolerance.
Naive Bayes classifier
The Naive Bayes classifier is a simple algorithm based on Bayes' theorem. Despite its simplicity, it performs remarkably well in text classification, spam filtering, and sentiment analysis. It assumes that features are independent, which is often an oversimplification, yet it delivers impressive results.
Applications in various fields:
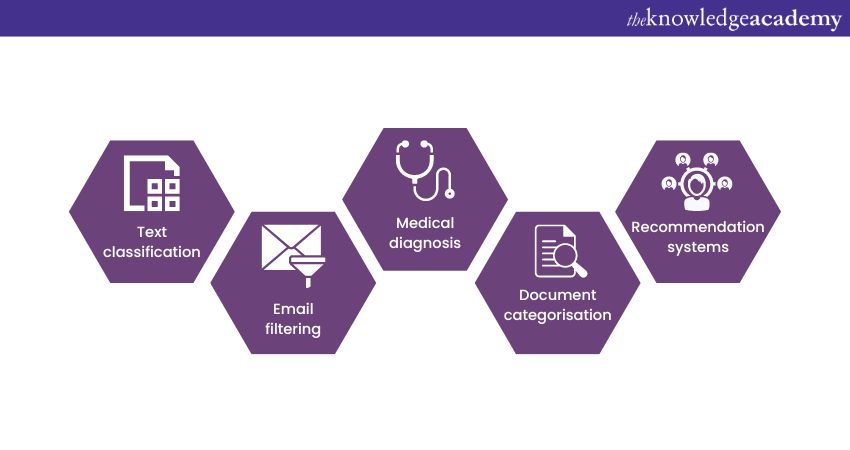
The Naive Bayes Classifier has found numerous applications in real-world problems due to its simplicity and ability to handle large datasets efficiently. Let's explore some of them below:
a) Text classification: It is widely used for sentiment analysis, spam filtering, and topic categorisation in natural language processing tasks.
b) Email filtering: The Naive Bayes Classifier is commonly employed in email spam detection, classifying inward emails as spam or not spam based on their content.
c) Medical diagnosis: In the medical field, Naive Bayes has been used for disease prediction and diagnosis based on patient symptoms and test results.
d) Document categorisation: It automatically categorises documents into different topics or classes.
e) Recommendation systems: The classifier is applied in recommendation engines to predict user preferences and recommend relevant products or content.
Unsupervised learning
Unsupervised learning is a fundamental Machine Learning technique that deals with unlabelled data, where the algorithm aims to discover patterns, structures, or relationships within the data without explicit guidance on the correct output. Unlike supervised learning, no labelled data points guide the learning process.
In unsupervised learning, the algorithm explores the data's inherent structure and attempts to find meaningful patterns without predefined categories. The primary goal is to cluster similar data points together based on their inherent similarities or to reduce the dimensionality of the data while preserving its essential characteristics.
Semi-supervised learning
Semi-supervised learning is a hybrid approach combining elements of supervised and unsupervised learning. This technique leverages the availability of a small amount of labelled data and a more substantial pool of unlabeled data to improve the performance of Machine Learning models.
Combining supervised and unsupervised learning
In traditional supervised learning, the algorithm relies solely on labelled data to train the model and make predictions. However, obtaining labelled data can be expensive and time-consuming, especially in domains requiring expert annotation.
On the other hand, unsupervised learning algorithms work with unlabeled data, finding patterns and structures without explicit class labels. Unsupervised learning efficiently handles large amounts of data without needing labelled examples. However, it may lack the precision labelled data provides regarding specific classes.
Reinforcement learning
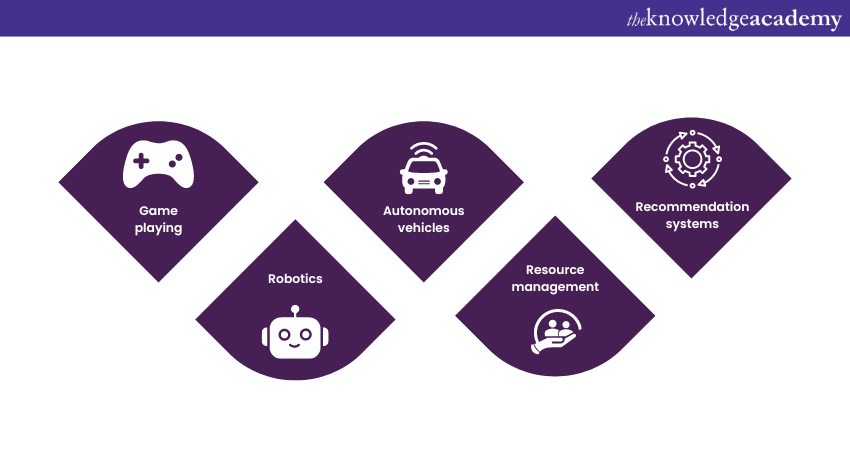
Reinforcement learning focuses on training agents to make decisions in an environment. The agent receives either rewards or penalties based on its actions, guiding it to learn optimal strategies. Reinforcement learning has several applications in robotics, game-playing, and autonomous vehicles. Let's take a look at some of them below:
1) Game playing: Reinforcement learning has been applied to master complex games, such as chess, Go, and video games, achieving superhuman performance.
2) Robotics: In robotics, reinforcement learning is used to train robots to perform tasks in dynamic and uncertain environments.
3) Autonomous vehicles: Reinforcement learning is key in training self-driving cars to navigate safely and efficiently on roads.
4) Resource management: It is applied to optimise resource allocation in energy management and logistics.
5) Recommendation systems: Reinforcement learning can be used to personalise and optimise user recommendations.
Deep learning
Deep learning involves training neural networks with multiple layers (deep neural networks) to perform complex tasks. It has revolutionised the field of Artificial Intelligence and has achieved remarkable success in various applications such as:
a) Computer vision
b) Natural language processing
c) Speech recognition
d) Game playing
Understanding neural network architecture
Artificial Neural Networks are at the center of Deep Learning are inspired by the anatomical structure of the humanoid brain. These networks consist of layers of intersected nodes called neurons. Each neuron takes input, performs a mathematical operation on it, and produces an output.
Ignite the future with the power of Deep Learning with our Deep Learning Training – Sign up today!
Ensemble learning
Ensemble learning combines multiple models to improve accuracy and robustness. Bagging and Boosting are popular ensemble techniques wherein models are taught on different subsets of data, and their predictions are combined to make final decisions.
Dimensionality reduction techniques
Dimensionality reduction techniques, like t-distributed Stochastic Neighbor Embedding (t-SNE) and Locally Linear Embedding (LLE), are essential for visualising high-dimensional data in lower dimensions. They help to identify meaningful patterns and relationships in complex datasets.
Anomaly detection
Anomaly detection is a crucial technique in Machine Learning that focuses on identifying rare and unusual patterns, events, or data points that deviate significantly from the norm. These anomalies, also known as outliers, can be indicative of critical information, such as fraud, faults, or unusual behaviour, and detecting them is essential for ensuring system integrity and security.
Transfer learning
Transfer learning is a technique that leverages knowledge gained from one domain or task to improve performance in a different but related domain or task. It involves using pre-trained models, features, or knowledge learned from a source domain to train a model for a target domain, where labelled data may be scarce or limited.
Leveraging knowledge from one domain to another:
In traditional Machine Learning approaches, models are trained from scratch for specific tasks using labelled data. However, in transfer learning, the idea is to reuse knowledge acquired from a previously learned model and apply it to a new but related task. This approach can save time, reduce the need for large amounts of labelled data, and improve the generalisation and performance of the target model.
Each of these different Machine Learning Methods plays a key role in solving different problems and driving innovation. As Machine Learning evolves, these methods will undoubtedly witness further advancements.
Unlock the potential of tomorrow's technology with our Machine Learning Training – Sign up now!
Conclusion
We hope you read and understand everything about Machine Learning Methods. Machine Learning is a powerful AI tool with various learning methods. These methods make AI more accessible and drive innovation for a brighter future.
Unlock the limitless possibilities of Artificial Intelligence with our Artificial Intelligence & Machine Learning Courses – Sign up now!
Frequently Asked Questions
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Introduction to AI Course
Introduction to AI Course
Introduction to AI Course
Fri 17th Jan 2025
Introduction to AI Course
Fri 7th Mar 2025
Introduction to AI Course
Fri 23rd May 2025
Introduction to AI Course
Fri 18th Jul 2025
Introduction to AI Course
Fri 12th Sep 2025
Introduction to AI Course
Fri 12th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


