



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +60 1800812339 and speak to our training experts, we may still be able to help with your training requirements.
K Fold Cross Validation In Machine Learning
Sophia Ellis 04 January 2024Gain a foundational understanding of machine learning algorithms, followed by an in-depth exploration of K-Fold Cross Validation. Uncover the step-by-step process of performing this technique, learn effective ways to analyse the results, and explore its real-world applications. Read more to learn!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

K-Fold Cross Validation in Machine Learning is a pivotal tool for assessing model performance. Machine learning algorithms, whether for classification, regression, or other tasks, often require a comprehensive evaluation.
Moreover, this technique enables robust assessment by partitioning the dataset into subsets, training and testing the model iteratively, and then aggregating results. Learn about K-fold Cross Validation in Machine Learning, including underfitting and overfitting notions, the implementation in Python, and the code explanation.
Table of Contents
1) A brief overview of algorithms in Machine Learning
2) Understanding what K Fold Cross Validation in Machine Learning is
3) Steps to perform K Fold Cross Validation in Machine Learning
4) How to analyse Cross Validation results?
5) Real-world applications of K Fold Cross Validation
6) Drawbacks faced in K Fold Cross Validation
7) Conclusion
A brief overview of algorithms in Machine Learning
Machine learning is a dynamic and rapidly evolving field that empowers computers to learn from data and make predictions or decisions without being explicitly programmed. At the core of machine learning are algorithms, which are the mathematical and computational models that drive the learning process.
These algorithms serve as the building blocks for developing intelligent systems and have various applications across industries, from healthcare to finance and beyond. Here is a list highlighting the key types of algorithms in Machine Learning:
1) Supervised Learning algorithms: These algorithms learn from labelled data, where the output is known. Examples include linear regression, decision trees, and support vector machines. They are used for tasks like classification and regression.
2) Unsupervised Learning algorithms: In this case, algorithms work with unlabelled data, seeking to identify patterns or structures within the data. Clustering algorithms like K-means and dimensionality reduction techniques such as Principal Component Analysis (PCA) fall into this category.
3) Semi-Supervised Learning algorithms: These algorithms leverage a combination of labelled and unlabelled data, making them valuable when labelled data is scarce or expensive to obtain.
4) Reinforcement Learning algorithms: Used in applications like gaming and robotics, these algorithms learn from interaction with an environment. Agents make a series of decisions to maximise a cumulative reward.
5) Deep Learning algorithms: A subset of machine learning, deep learning focuses on neural networks with multiple layers (deep neural networks). Convolutional Neural Networks (CNNs) for image processing and Recurrent Neural Networks (RNNs) for sequential data are examples.
6) Ensemble methods: These combine predictions from multiple models to improve overall performance. Popular ensemble techniques include Random Forests and Gradient Boosting.
7) Natural Language Processing or ‘NLP’ algorithms: Designed for working with textual data, NLP algorithms process and understand human language. Examples include Word2Vec, LSTM, and Transformers.
8) Anomaly detection algorithms: These algorithms identify abnormal or rare instances within a dataset, making them crucial in fraud detection, network security, and fault detection.

Understanding What is K Fold Cross Validation in Machine Learning
K-Fold Cross-Validation (KFCV) is a crucial technique in machine learning for assessing the performance and reliability of predictive models. It addresses the limitations of traditional train-test splitting and provides a more robust way to evaluate how well a model generalises to unseen data.
Furthermore, the concept of K-Fold Cross-Validation is relatively simple. Instead of dividing your dataset into just two parts, a training set and a testing set, it involves dividing the dataset into K subsets or "folds." K represents the number of partitions you want to create.
The most common choice for K is 5 or 10, but it can vary based on the dataset's size and specific needs. Each fold is used as a testing set exactly once, and the remaining K-1 folds are used as the training set. This process is repeated K times, with each fold serving as the test set once. The results are then averaged to obtain a final performance metric.
The benefits of K-Fold Cross-Validation are numerous:
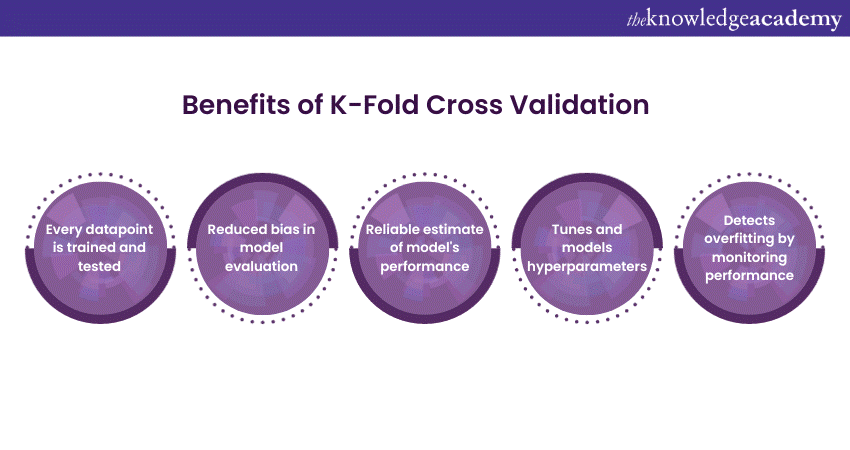
1) Reduced bias: KFCV ensures that every data point is used for both training and testing, minimising bias in model evaluation.
2) Robustness: It provides a more reliable estimate of a model's performance because it averages over multiple test sets, reducing the impact of randomness in data partitioning.
3) Maximising data utilisation: All data is used for both training and testing, making efficient use of available information.
4) Hyperparameter tuning: It is crucial for hyperparameter tuning and model selection as it helps in assessing how well a model generalises across different data partitions.
5) Detection of overfitting: KFCV can highlight if a model is overfitting by observing how its performance varies across different folds.
Steps to perform K Fold Cross Validation in Machine Learning
Performing K-Fold Cross-Validation in Machine Learning is a fundamental step to assess a model's performance while ensuring robustness and minimising bias. The technique is particularly useful in scenarios where a simple train-test split may result in biased evaluation.
Now, it minimises the risk of overfitting, as the model is assessed on various subsets of the data. It also aids in model selection and hyperparameter tuning, providing a more comprehensive view of a model's strengths and weaknesses.
Here are the key steps to carry out K-Fold Cross Validation:
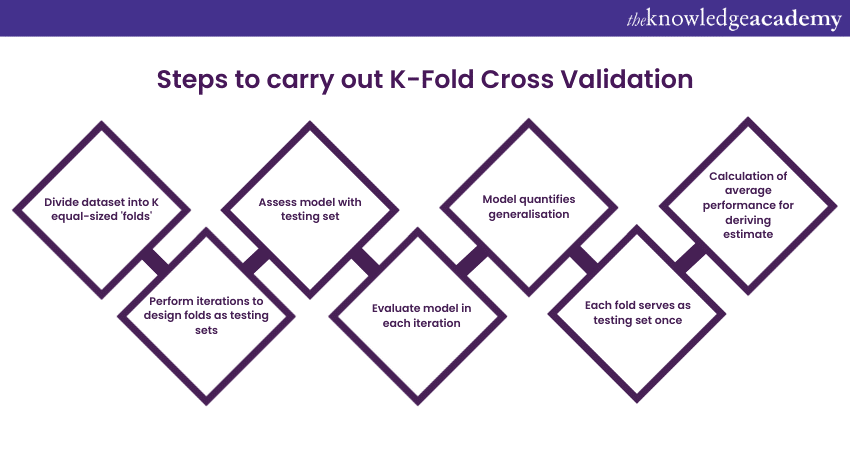
1) Data splitting: Start by dividing your dataset into K roughly equal-sized subsets or "folds." Typically, K is chosen as 5 or 10, but it can vary based on your dataset's size and requirements.
2) Training and testing iterations: Perform K iterations, each time designating one of the folds as the testing set and the remaining K-1 folds as the training set.
3) Model training: For each iteration, train your machine learning model using the training set. This involves feeding your algorithm with the data, allowing it to learn the patterns and relationships within the data.
4) Model testing: After training, assess the model's performance using the testing set. This step involves making predictions on the testing data and comparing these predictions to the actual labels or target values.
5) Performance metric calculation: Calculate a performance metric (e.g., accuracy, mean squared error, F1-score) to evaluate the model's performance for each iteration. This metric quantifies how well the model generalises unseen data.
6) Iteration repeats: Repeat steps 3 to 5 K times, with each fold serving as the testing set once.
7) Performance aggregation: After completing all K iterations, calculate the average or mean performance metric across these iterations. This provides a robust estimate of the model's overall performance.
Enhance your skills to become an AI professional by signing up for our Introduction to Artificial Intelligence Training now!
How to analyse Cross Validation results?
Analysing the results of cross-validation is a crucial step in assessing the performance of a machine learning model. The results provide insights into how well the model generalises to unseen data and can guide decisions on model selection, hyperparameter tuning, and overall model improvement.
Here is a comprehensive overview of the process of analysing Cross Validation results:
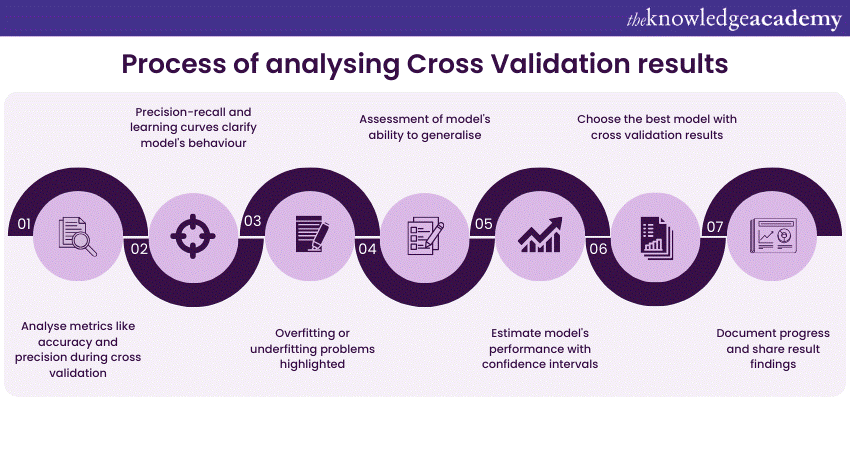
1) Performance metrics: Begin by looking at the performance metrics calculated during cross-validation. Common metrics include accuracy, precision, recall, F1-score, mean squared error, and many more, depending on the problem type (classification, regression, etc.).
2) Visualisations: Visualisations are powerful tools for understanding model performance. Plotting metrics such as ROC curves, precision-recall curves, or learning curves can provide a clear picture of the model's behaviour across different evaluation rounds.
3) Variance and bias: Assess the variance and bias of your model. A model with high variance may be overfitting, while high bias may indicate underfitting. Cross-validation helps identify these issues by observing how metrics vary across folds.
4) Detecting overfitting and underfitting: Cross-validation results can highlight overfitting or underfitting issues. If the model performs exceptionally well on the training data but poorly on test data, it's likely overfitting. Underfitting may be indicated by poor performance on both training and testing data.
5) Hyperparameter tuning: Cross-validation is instrumental in hyperparameter tuning. By comparing results with different hyperparameter configurations, you can identify the most suitable settings for your model.
6) Generalisation: Cross-validation assesses the model's generalisation ability. If performance metrics are consistent across folds, it indicates that the model can generalise well to unseen data.
7) Confidence intervals: Compute confidence intervals to estimate the range within which the model's performance metric lies. This helps assess the stability of your results and guides your level of confidence in the model's performance.
8) Model selection: If you are comparing different models, cross-validation results can help you choose the best-performing model. You can use statistical tests to determine whether the performance differences are significant.
9) Iterative model improvement: Analyse the results iteratively. After making changes to the model (e.g., feature engineering, hyperparameter adjustments), re-run cross-validation to see how the changes impact performance.
10) Record keeping: Keep records of the cross-validation results, including the metrics, visualisations, and any relevant information about the data splits and model settings. This documentation helps in tracking progress and sharing findings with others.
Real-world applications of K Fold Cross Validation
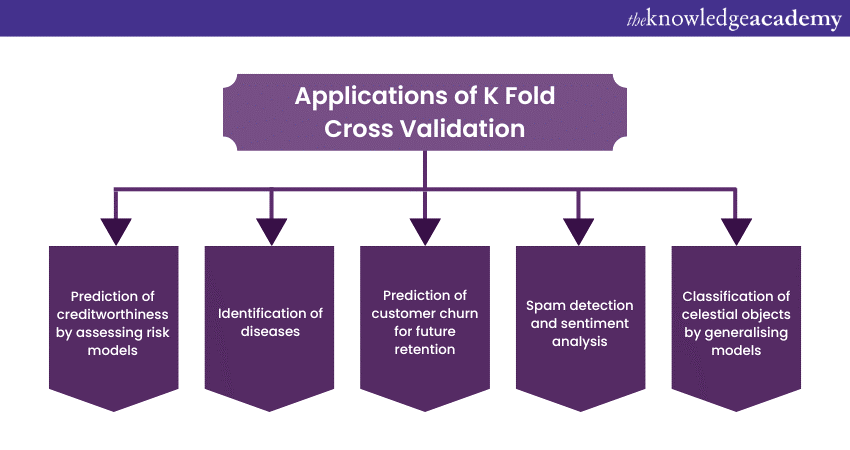
K-Fold Cross-Validation is a versatile technique with numerous real-world applications in the field of Machine Learning. By assessing a model's performance from various perspectives, K-Fold Cross-Validation helps ensure that the model is robust and capable of generalising effectively. Here are some of the many practical applications of K-Fold Cross-Validation:
Healthcare: Disease diagnosis
In medical diagnostics, K-Fold Cross-Validation can help evaluate the accuracy and reliability of machine learning models for identifying diseases such as cancer, diabetes, or heart conditions. It's crucial to ensure that these models are both sensitive and specific to reduce false positives and negatives.
Finance: Credit risk assessment
Banks and financial institutions use K-Fold Cross-Validation to assess credit risk models. By splitting data into folds, they can rigorously evaluate the models' ability to predict creditworthiness, reducing the likelihood of approving high-risk borrowers.
Retail: Customer churn prediction
Retail companies rely on K-Fold Cross-Validation to fine-tune models that predict customer churn. This ensures that the model can effectively identify customers likely to leave, allowing the business to take proactive retention measures.
Image recognition: Convolutional Neural Networks
In image recognition tasks, such as facial recognition or object detection, K-Fold Cross-Validation is used to validate the performance of convolutional neural networks. By dividing the image dataset into folds, it verifies the model's capability to generalise across various image scenarios.
Natural Language Processing: Text classification
In sentiment analysis, spam detection, and other text classification tasks, K-Fold Cross-Validation helps assess the performance of machine learning models. It ensures the model can handle diverse textual data and sentiment patterns.
Environmental science: Climate change prediction
Environmental scientists employ K-Fold Cross-Validation to validate climate change prediction models. By assessing models across different time frames and geographic regions, it ensures their reliability for future climate forecasts.
Astronomy: Celestial object classification
In the classification of celestial objects, such as stars, galaxies, or asteroids, K-Fold Cross-Validation is utilised to ensure that models generalise well to different sections of the night sky and various telescope observations.
Manufacturing: Quality Control
Manufacturing companies use K-Fold Cross-Validation to evaluate models for quality control. This helps identify defects in products and ensures that the model can handle variations in manufacturing processes.
Automotive: Autonomous vehicle development
Autonomous vehicle development relies on K-Fold Cross-Validation to assess the performance of Machine Learning models for object detection, path planning, and other critical functions. This ensures that the model can adapt to diverse driving conditions and scenarios.
Market forecasting: Stock price prediction
In finance and investment, K-Fold Cross-Validation helps assess the reliability of machine learning models used for stock price prediction. It ensures that the model can generalise across various market conditions.
Learn about neural networks, clustering, supervised and unsupervised learning by signing up for Machine Learning Training now!
Drawbacks faced in K Fold Cross Validation
K-Fold Cross-Validation is a widely used technique for assessing the performance of machine learning models, but it's not without its drawbacks and limitations. It's essential to be aware of these limitations to make informed decisions when using this method:
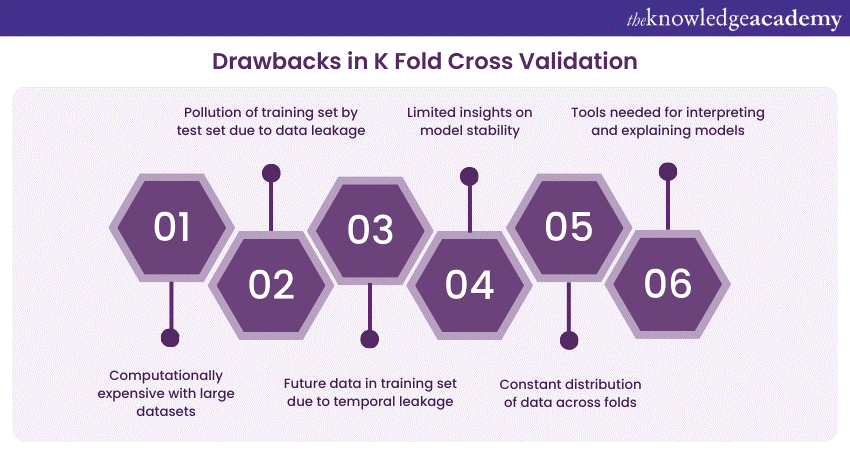
1) Computational cost: K-Fold Cross-Validation can be computationally expensive, especially when the dataset is large, or the model is complex. Running K iterations of model training and testing can consume significant time and resources.
2) Data leakage: K-Fold Cross-Validation doesn't eliminate the risk of data leakage. Information from the test set may influence the training set, especially when feature engineering or preprocessing is involved.
3) Randomness: The choice of the initial data split into folds is random. Different splits may lead to varying results, making it challenging to determine a model's performance precisely. This randomness can affect model selection and hyperparameter tuning.
4) Not suitable for time series data: K-Fold Cross-Validation doesn't work well with time-dependent data. It can introduce temporal leakage, which means data from the future may be included in the training set when predicting data from the past.
5) Class imbalance: When dealing with imbalanced datasets, K-Fold Cross-Validation may lead to unrepresentative folds, where one class is underrepresented in some folds. Stratified K-Fold can mitigate this issue but doesn't completely resolve it.
6) Inefficient for small datasets: Splitting small datasets into K folds can result in very small training sets, leading to unreliable model estimates. In such cases, other techniques like Leave-One-Out Cross-Validation may be more appropriate.
7) Overfitting and underfitting assessment: Cross-validation may not provide a complete picture of a model's overfitting or underfitting tendencies. Some models can fit the training data well, but cross-validation may not reveal the issue without further analysis.
8) Limited information on model stability: Cross-validation results focus on model accuracy but provide limited insights into model stability and robustness. A model that consistently underperforms in multiple folds may be more stable than one with varying performance.
9) Data distribution changes: Cross-validation assumes that the data distribution remains constant across folds. In practice, data distributions can vary, especially in real-world applications, where external factors or new data sources might affect the data distribution.
10) Interpretability: Cross-validation results provide numerical metrics, but they don't explain why a model performs a certain way. Interpretability and explanation of model decisions require additional techniques and tools.
Grow your revenue and improve customer experience by signing up for Artificial Intelligence & Machine Learning now!
Conclusion
K-Fold Cross Validation in Machine Learning is a powerful and widely used technique for robust model evaluation. While it has its limitations, understanding its drawbacks and applications is essential for making informed decisions in the field of Machine Learning.
Frequently Asked Questions
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Machine Learning Course
Machine Learning Course
Machine Learning Course
Fri 10th Jan 2025
Machine Learning Course
Fri 28th Feb 2025
Machine Learning Course
Fri 4th Apr 2025
Machine Learning Course
Fri 16th May 2025
Machine Learning Course
Fri 11th Jul 2025
Machine Learning Course
Fri 19th Sep 2025
Machine Learning Course
Fri 21st Nov 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


