



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +31 208081674 and speak to our training experts, we may still be able to help with your training requirements.
Data Lake vs Data Warehouse: A Complete Breakdown
Eliza Taylor 19 December 2024This blog on Data Lake vs Data Warehouse empowers Data Scientists, Analysts, and IT experts to make strategic decisions in crafting Data Architectures. Here, you’ll learn the details of the definitions, benefits, and, finally, the difference between a Data Lake and a Data Warehouse. Discover the realm of Data Lake and Data Warehouse with us!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents
Two significant contenders emerge in data management: Data Lakes and Data Warehouses. As enterprises grapple with vast amounts of data, discerning the subtle differences between these two becomes paramount. This in-depth blog guides you through Data Lake vs Data Warehouse's intricacies, use cases, and benefits.
As the volume of data handled by organisations continues to grow exponentially, navigating the complexities of data management is essential. This comprehensive blog is designed to provide insights into the nuanced distinctions between Data Lake and Data Warehouse. By delving into their respective use cases and advantages, readers can understand how these two entities operate in data management, empowering them to make informed decisions tailored to their unique organisational needs.
Table of Contents
1) What is a Data Lake?
2) Benefits of Data Lake
3) What is a Data Warehouse?
4) Benefits of Data Warehousing
5) Data Lake and Data Warehouse: Key Differences
6) Conclusion
What is a Data Lake?
A Data Lake serves as a centralised reservoir within the data architecture of organisations, providing a versatile solution for storing unstructured and structured data at virtually any scale. This reservoir distinguishes itself from traditional databases by eschewing a specific structure or schema requirement. Unlike conventional data storage systems that demand predefined formats, a Data Lake embraces a more fluid approach, allowing the storage of raw and diverse data.
In contrast to the rigid schema enforced by traditional databases, the lack of a predefined structure in a Data Lake allows for seamless integration of diverse data types. This inclusivity is advantageous in a modern data landscape with many formats and sources. Whether dealing with text, images, videos, or other unstructured data forms, a Data Lake's flexibility becomes a strategic asset.

Benefits of a Data Lake
In this section, we will delve into the advantages of a Data Lake, emphasising its versatility, cost-effectiveness, and role in fostering advanced analytics and seamless data exploration.
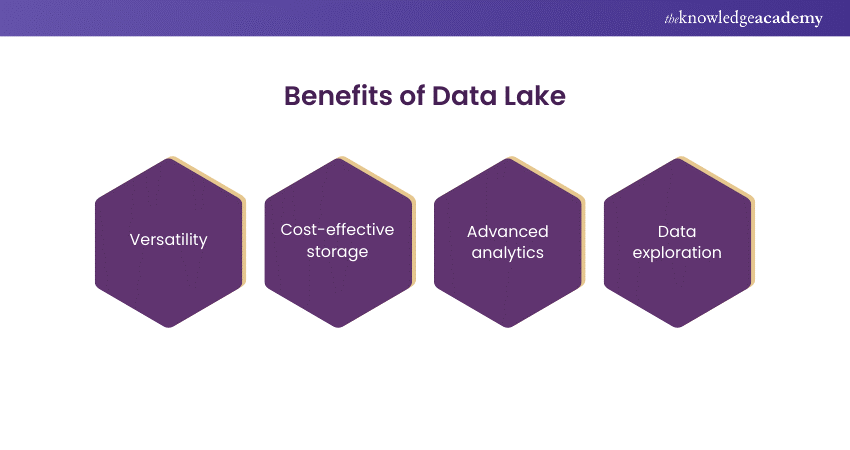
1) Versatility: A key strength of Data Lake lies in its unmatched versatility. Unlike traditional storage systems, Data Lake can store data in its raw, unaltered form, making it ideal for organisations with various data sources and formats.
2) Cost-effective Storage: Data Lake leverages scalable, cost-effective storage solutions offered by cloud computing. This enables organisations to manage growing data volumes without incurring high costs. Cloud-based scalability ensures that storage capacities align with evolving data infrastructure needs, democratising access to expansive and flexible data repositories.
3) Advanced analytics: Data Lake is pivotal in advancing analytics and Data Science. Storing raw and unprocessed data provides a foundation for data scientists to conduct advanced analytics. The absence of predefined structures allows for flexible exploration, unlocking hidden patterns and correlations within the data. Data Lake catalyses innovation, fostering a data-driven culture that enables informed decision-making.
4) Data Exploration: Users can delve into data without prior structuring, promoting agile and iterative exploration. This flexibility accelerates insight generation, encouraging inclusive participation in the data discovery process. Data Lakes become enablers of a data-driven culture where the inherent richness of raw data fuels exploration.
Examples of a Data Lake
Examples of Data Lakes include Amazon S3, Google Cloud Storage, and Microsoft Azure Data Lake. Amazon S3 is widely used for its scalability, allowing companies to store and retrieve any amount of data. Google Cloud Storage offers similar capabilities with strong integration into Google’s ecosystem. Microsoft Azure Data Lake, part of the Azure cloud platform, provides a robust and scalable environment for Big Data Analytics, supporting various data processing frameworks like Hadoop.
Learn more about Data Analytics and Big Data with our Data Warehouse Training – Sign up today!
What is a Data Warehouse?
A Data Warehouse is a centralised repository that serves as the cornerstone of an organisation's Data Management strategy. Its primary purpose is accumulating, integrating, and storing vast volumes of data from diverse sources within the enterprise. Unlike transactional databases that are optimised for real-time data processing, Data Warehouses are designed for analytical processing, providing a robust platform for reporting, business intelligence, and strategic decision-making.
The architecture of a Data Warehouse is meticulously crafted to ensure data consistency, accuracy, and accessibility. It includes data extraction, transformation, and loading (ETL) from various operational systems into a unified format within the warehouse. This transformation process aligns disparate data sources, enabling users to derive meaningful insights by querying the consolidated dataset.
Stay at the forefront of Big Data with our Big Data Analysis Course – Join today!
Benefits of Data Warehousing
In this section, we will delve into the advantages of a Data Warehouse, emphasising its structured data, query performance, data quality, consistency, and scalability for analytics.
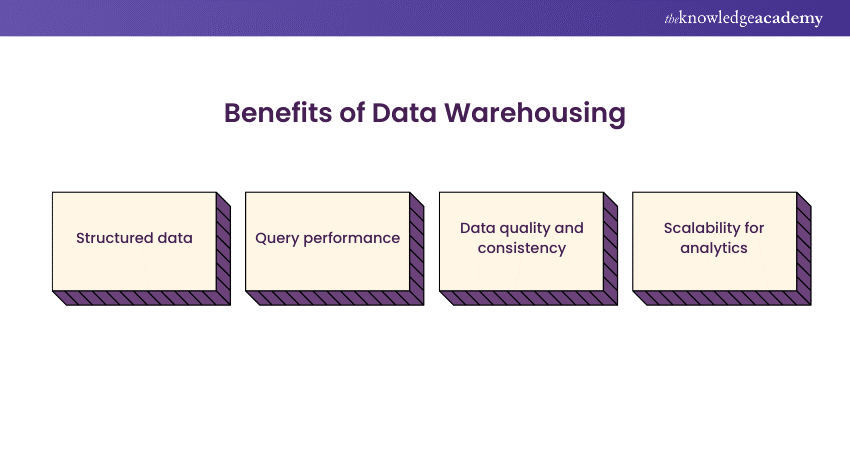
1) Structured Data: The enforcement of a structured schema within Data Warehouses lays a robust foundation for clarity in data representation. This structured approach not only organises data logically but also standardises its format. By adhering to predefined data models, Data Warehouses enable seamless communication between different datasets. Structured data becomes a linchpin in pursuing a unified and understandable data environment.
2) Query Performance: Data Warehouses are optimised for complex queries and analytical processing. This results in faster query performance, making them suitable for business intelligence and decision-making processes. This acceleration is particularly advantageous in business intelligence, where quick access to actionable insights is paramount. The efficiency with which Data Warehouses process queries empowers organisations to extract meaningful information from large datasets promptly.
3) Data Quality and Consistency: The predefined schema in Data Warehouses ensures data quality and consistency. This is crucial for organisations relying on accurate, standardised information for reporting and analysis. Data Warehouses act as custodians, enforcing a structured framework that minimises errors and disparities. This commitment to data quality and consistency fortifies the reliability of the information housed in a Data Warehouse.
4) Scalability for Analytics: While less versatile than Data Lakes regarding data types, Data Warehouses excel in scalability for analytical workloads. They can efficiently handle large volumes of structured data for reporting and analytics. This scalability ensures that Data Warehouses can seamlessly adapt to the evolving demands of analytical processes, offering a robust solution for organisations navigating the complexities of a data-driven landscape.
Examples of a Data Warehouse
Examples of Data Warehouses include Amazon Redshift, Google BigQuery, and Microsoft Azure Synapse Analytics. Amazon Redshift is a fully managed, scalable cloud Data Warehouse service that allows businesses to analyse vast amounts of data quickly and efficiently.
Google BigQuery is a serverless, highly scalable Data Warehouse that enables super-fast SQL queries using the processing power of Google's infrastructure. Microsoft Azure Synapse Analytics integrates Big Data and Data Warehousing into a single, unified platform, allowing businesses to query data on their terms, using either serverless or provisioned resources.
Explore the realm of Data Analytics with our Advanced Data Analytics Certification Course – Join today!
Data Lake and Data Warehouse: Key Differences
Now, let's investigate the key Differences between Data Lake and Data Warehouse across various dimensions.
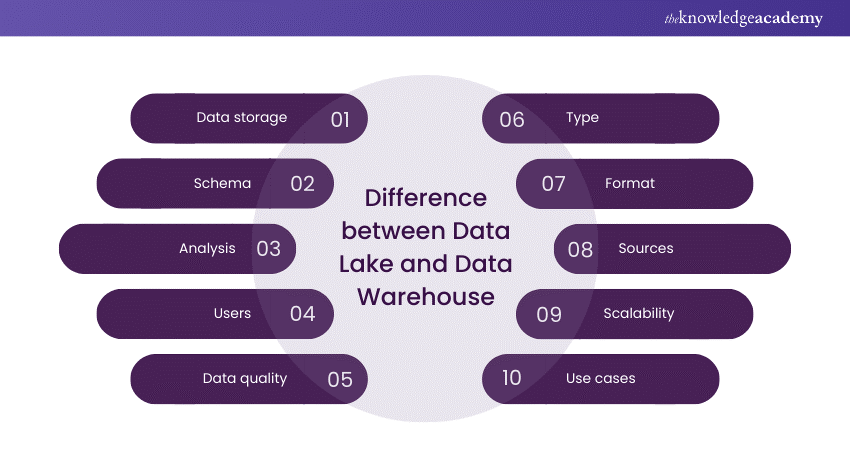
1) Data Storage
The fundamental difference between Data Lakes and Data Warehouses lies in how they store data. Data Lakes store raw, unstructured, and diverse data in its original format, accommodating everything from text files and images to sensor data and logs. This flexibility allows organisations to store vast amounts of data without the need for prior processing. In contrast, Data Warehouses store structured and processed data, which has been cleaned, transformed, and organised into predefined schemas. This makes the data immediately ready for analysis.
2) Schema
Data Lakes use a schema-on-read approach, where the schema is applied when the data is read, allowing for greater flexibility in how the data is interpreted and used. This is ideal for exploratory analysis. On the other hand, Data Warehouses employ a schema-on-write model, enforcing a predefined structure during data ingestion. This approach ensures that data is well-organised and ready for quick and efficient analysis, but it requires upfront planning.
3) Analysis
Data Lakes are particularly suited for exploratory and ad-hoc analysis due to their ability to store raw data. They enable data scientists to experiment with different datasets and analytical models without being constrained by rigid structures. Conversely, Data Warehouses are designed for complex analytical processing, offering optimised query performance for structured data. This makes them ideal for generating reliable, consistent reports and supporting business intelligence efforts.
4) Users
The typical users of Data Lakes and Data Warehouses differ significantly. Data Lakes are primarily used by data scientists, engineers, and analysts who need access to raw, unprocessed data for exploration, machine learning, and advanced analytics. Data Warehouses, however, cater to business users, analysts, and decision-makers who require structured data for reporting, trend analysis, and strategic decision-making.
5) Data Quality
Data Warehouses emphasise data quality through structured schemas and rigorous data governance practices, ensuring consistency, accuracy, and reliability. This is crucial for applications where data integrity is paramount, such as financial reporting. In contrast, Data Lakes, which store raw and unstructured data, may require additional governance measures to maintain data quality. The lack of a predefined schema can lead to challenges in ensuring data consistency across various sources.
6) Data Type
Data Lakes can store all types of data, including raw and unstructured formats such as text, images, and videos. This versatility is ideal for organisations dealing with a wide range of data sources. On the other hand, Data Warehouses focus on structured data types, organising information into tables and columns optimised for analytical queries.
7) Data Format
Data Lakes store data in its original format, often using distributed file systems like the Hadoop Distributed File System (HDFS). This approach offers maximum flexibility in data processing and analysis. Data Warehouses, however, use relational databases to organise data into structured tables, which supports efficient querying and makes the data readily accessible for analysis.
8) Data Sources
Data Lakes are designed to accommodate data from a variety of sources, regardless of format or structure, making them ideal for organisations that need to integrate diverse data types. Data Warehouses, on the other hand, integrate structured data from various sources, ensuring uniformity in data representation, which is critical for cross-functional analysis.
9) Scalability
Data Lakes leverage scalable cloud storage, making them capable of handling increasing volumes of data with ease. This scalability is particularly beneficial for organisations dealing with big data and advanced analytics. Data Warehouses, while also scalable, are optimised for analytical workloads and efficiently manage large volumes of structured data.
10) Use Cases
Data Lakes are ideal for exploratory Data Analysis, Big Data processing, and advanced analytics, providing a flexible environment for experimenting with datasets. Data Warehouses, in contrast, are better suited for business intelligence, reporting, and decision support systems, offering a reliable platform for executing complex queries and generating actionable insights.
11) Data Processing
Data Lakes prioritize flexibility in data processing, allowing various frameworks to be applied as needed. This makes them suitable for handling diverse data types and processing requirements. Data Warehouses optimise for analytical processing, ensuring efficient querying and reporting with structured data.
12) Cost
Data Lakes offer cost-effective storage, particularly for large volumes of unstructured data. However, the overall cost depends on usage patterns and the level of governance required. Data Warehouses may have higher storage costs due to their structured nature, but they can provide cost savings through optimised analytical processing, reducing the time and resources needed for data analysis.
Conclusion
There needs to be more than one-size-fits-all solution in the Data Lake vs Data Warehouse debate. Organisations must carefully assess their requirements, considering factors like data types, analysis needs, and user roles. The choice between them depends on the specific use cases, the nature of the data, and the organisation's analytical and reporting needs. By understanding the nuanced differences outlined in this breakdown, organisations can make informed decisions, ensuring they effectively harness their data's power.
Explore the realm of Data Analytics with our Data Analytics with R Course – Join today!
Frequently Asked Questions
Is Amazon S3 a Data Lake?

Amazon S3 itself is not a Data Lake, but it can be used to build a Data Lake by storing vast amounts of raw, unstructured, and structured data, which can then be processed and analysed using various tools.
Is BigQuery a Data Lake or Data Warehouse?
BigQuery is a fully managed, serverless Data Warehouse. It is designed for structured data and optimised for fast, scalable SQL queries, making it ideal for analytical processing rather than storing raw, unstructured data like a Data Lake.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 17 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy offers various Big Data and Analytics, including Big Data Analysis, Data Warehousing Training, etc. These courses cater to different skill levels, providing comprehensive insights into Data Collection.
Our Data Analytics and AI blogs cover a range of topics related to Data Analytics, offering valuable resources, best practices, and Data Analysis insights. Whether you are a beginner or looking to advance your Big Data skills, The Knowledge Academy's diverse courses and informative blogs have you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Data Warehousing Training
Data Warehousing Training
Data Warehousing Training
Fri 7th Feb 2025
Data Warehousing Training
Fri 4th Apr 2025
Data Warehousing Training
Fri 6th Jun 2025
Data Warehousing Training
Fri 8th Aug 2025
Data Warehousing Training
Fri 3rd Oct 2025
Data Warehousing Training
Fri 5th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


