



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on + 1-866 272 8822 and speak to our training experts, we may still be able to help with your training requirements.
Big Data Architecture: A Comprehensive Guide
Sienna Roberts 03 January 2025Big Data Architecture is the foundation for data-driven decision-making. This comprehensive framework efficiently organises, processes, and analyses vast data volumes, enabling businesses to glean valuable insights. Dive into the intricacies of Big Data Architecture to optimise your data strategies and harness the power of information.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

The importance of Big Data Architecture is paramount in today’s day and age. Businesses have the capability to leverage distributed computing frameworks and cloud-based solutions to handle massive data volumes.
More importantly, the future scope of Big Data Architecture promises seamless integration of AI, edge computing, and quantum computing, revolutionising industries and empowering data-driven decision-making for a brighter future. Explore this blog to learn in detail about Big Data Architecture, including its components, patterns, scaling methods and future scope. Read more.
Table of Contents
1) Understanding What is Big Data Architecture
2) Exploring the Core Components of Big Data Architecture
3) What are the Various Patterns in Big Data Architecture?
4) Benefits of Big Data Architecture
5) How can you Scale Big Data Architectures?
6) Looking at the Future Scope in Big Data Architecture
7) Conclusion
Understanding What is Big Data Architecture
Big Data Architecture refers to the systematic design and structure of a data management framework that can handle and process large volumes of diverse and rapidly flowing data. It encompasses a series of interconnected components and technologies that work together to store, process, and analyse massive datasets, often in real-time, to extract valuable insights and knowledge.
At its core, Big Data Architecture addresses the challenges posed by the three Vs of big data: Volume, Variety, and Velocity. The Volume represents the enormous size of data generated, Variety accounts for the different data formats and types (structured, semi-structured, unstructured), and Velocity deals with the speed at which data is generated and must be processed.
More importantly, a well-designed Big Data Architecture incorporates various elements, including data sources and ingestion mechanisms, storage solutions (such as data lakes or warehouses), data processing frameworks (e.g., Hadoop, Spark), and data governance and security measures. It also considers scaling strategies, cloud-based solutions, and analytics tools to harness the full potential of big data.

Exploring the Core Components of Big Data Architecture
Big Data Architecture comprises various components, which are discussed in detail below as follows:
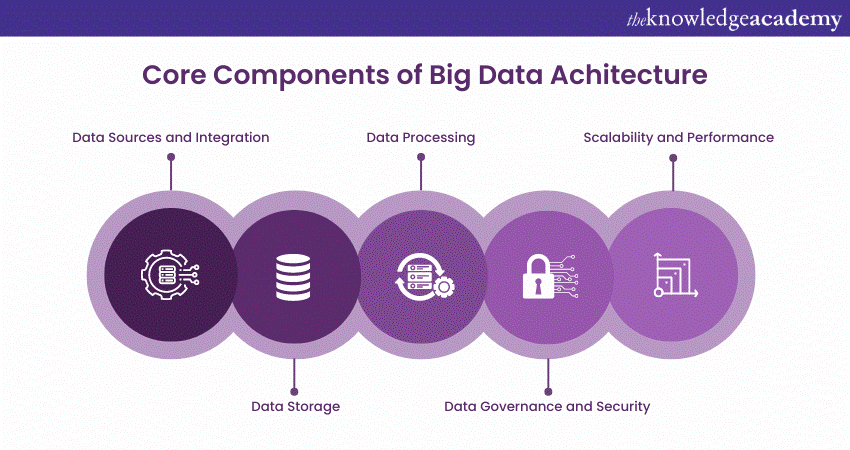
Data Sources and Integration
A crucial element of big data architecture is identifying and categorising data sources for ingestion. These sources include structured data from databases, semi-structured data from APIs and logs, and unstructured data from social media and sensors. Efficient data ingestion is essential to manage the vast, real-time data influx, with tools like Apache Kafka and Apache NiFi commonly used to ensure a seamless data flow into the big data ecosystem.
Data Storage
Data storage is a pivotal component of big data architecture. Traditional databases often fall short due to the massive data volumes involved, necessitating the use of big data storage solutions like Data Lakes and Data Warehouses. Data Lakes offer flexible storage for both structured and unstructured data in its raw form, while Data Warehouses provide structured storage optimised for querying and analytics. NoSQL databases such as MongoDB and Cassandra are also employed for specific scenarios, offering horizontal scalability and high performance for certain data types.
Data Processing
Data processing is the core of big data architecture, transforming and analysing data to extract valuable insights. This process involves two primary approaches: Batch processing, which handles large datasets at scheduled intervals, and real-time stream processing, which processes data as it arrives. Technologies like Apache Hadoop and Apache Spark are widely used for distributed data processing, enabling parallel computation and efficient management of vast data volumes.
Data Governance and Security
Data governance and security are critical in big data architecture, ensuring data quality, compliance, and privacy. Data governance determines policies and processes for data management, access, and usage, while security measures like encryption, authentication, and authorisation protect against unauthorised access and potential breaches. Compliance with regulationsof the General Data Protection Regulation (GDPR), is also a key aspect of data governance.
Scalability and Performance
Scalability is essential in big data architecture, allowing the system to grow with increasing data volumes without compromising performance. Horizontal scaling, which involves adding more servers or nodes, distributes data and processing tasks across multiple resources, ensuring the system can efficiently handle peak loads. Techniques like caching and indexing are used to enhance query performance and reduce latency in data access.
Learn the various analytics platforms and databases for Big Data, by signing up for the Big Data and Analytics Training Courses now!
What are the Various Patterns in Big Data Architecture?
Here are the various patterns in Big Data Architecture described in further detail:
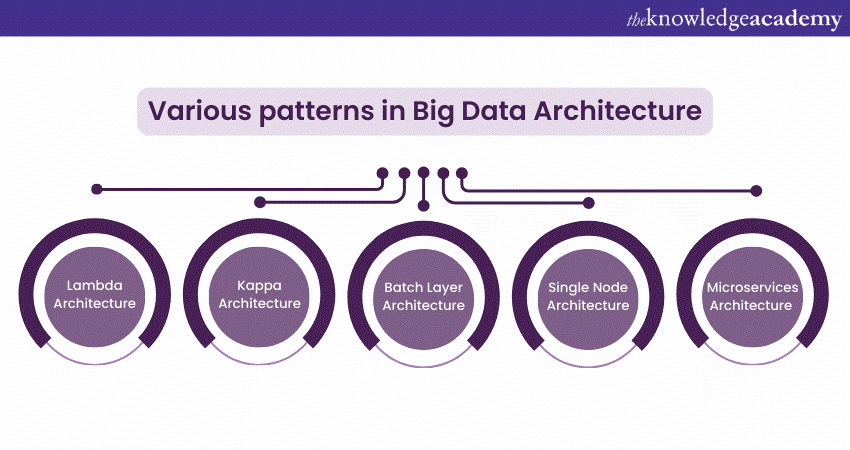
Lambda architecture
Lambda Architecture is a widely adopted pattern in big data that addresses the challenges of processing both real-time and batch data. It comprises three layers: The Batch layer, Speed layer, and Serving layer. The Batch layer processes large volumes of data offline, producing comprehensive batch views for in-depth insights. The Speed layer handles real-time data, delivering low-latency results for immediate analysis. The Serving layer then merges outputs from both layers to provide a unified data view. This architecture is known for its resilience, fault tolerance, and scalability, making it ideal for applications requiring both real-time and historical data analysis.
Kappa Architecture
Kappa Architecture offers a streamlined alternative to Lambda Architecture by focusing exclusively on real-time data processing. In this model, all data—whether historical or current—is treated as an immutable stream of events. The data is ingested and processed in real-time using technologies like Apache Kafka and Apache Flink. By eliminating the need for separate batch and real-time processing pipelines, Kappa Architecture simplifies big data processing, making it particularly advantageous for scenarios where real-time insights and actions based on the freshest data are critical.
Batch Layer Architecture
Batch Layer Architecture is a straightforward approach in big data that focuses solely on processing data in batches. In this model, data is collected over time and processed in its entirety at scheduled intervals. This processing can include data cleaning, transformation, and analysis. Batch processing is cost-effective and suited to scenarios where low latency is not a priority, such as historical trend analysis and periodic reporting.
Single Node Architecture
Single Node Architecture is the simplest pattern, typically used in small-scale big data projects or when the data volume is manageable on a single server. This architecture involves a single machine handling the storage, processing, and analysis of data. Although it lacks the scalability and fault tolerance of more complex architectures, Single Node Architecture is easy to set up and maintain, making it an ideal choice for initial data exploration and experimentation.
Microservices Architecture
In big data, Microservices Architecture involves breaking down the system into smaller, independent services that communicate via APIs. Each microservice is accountable for a specific task, such as data ingestion, processing, storage, or analytics. This decoupling enhances flexibility, scalability, and maintainability, allowing teams to work independently on different components, thereby streamlining development and deployment processes.
Acquire the knowledge of various Microservices scenarios and domain-driven design, by signing up for the Microservices Architecture Training Course now!
Benefits of Big Data Architecture
a) Parallel Computing for High Performance Big Data architectures leverage parallel computing to accelerate the processing of large datasets. Multiprocessor servers perform multiple calculations simultaneously by breaking down complex problems into smaller tasks that can be processed concurrently.
b) Elastic Scalability Big Data architectures offer elastic scalability, allowing for horizontal scaling to match the size of each workload. Typically deployed in the cloud, these solutions let you pay only for the storage and computing resources you use.
c) Flexibility in Solution Choice The market provides a wide range of platforms and solutions for Big Data architectures, such as Azure managed services, MongoDB Atlas, and Apache technologies. These can be combined to tailor the best fit for your specific workloads, existing systems, and IT expertise.
d) Interoperability with Related Systems Big Data architectures enable the creation of integrated platforms across different workloads, supporting IoT processing, business intelligence, and analytics workflows by leveraging various architecture components.
How can you Scale Big Data Architectures?
Organisations can scale Big Data Architectures, in various ways that are highlighted below as follows:
a) Distributed File Systems: Utilise distributed file systems like Hadoop Distributed File System (HDFS) to store and manage vast amounts of data across multiple nodes. This enables horizontal scaling, where data can be distributed and processed in parallel, increasing overall throughput and performance.
b) Data Partitioning: Implement data partitioning techniques to divide data into smaller chunks and distribute them across different nodes. By doing so, data processing can be parallelised, reducing the load on individual nodes and improving overall efficiency.
c) Load Balancing: Use load balancing mechanisms to evenly distribute data processing tasks across the nodes in the cluster. Load balancing ensures that each node performs a fair share of work, preventing bottlenecks and optimising resource utilisation.
d) Data Replication: Employ data replication to create redundant copies of critical data across multiple nodes. Replication enhances fault tolerance, ensuring data availability even if some nodes fail, and contributes to better read performance by serving data from the nearest replica.
e) Distributed Computing Frameworks: Leverage distributed computing frameworks such as Apache Spark and Apache Hadoop to process large-scale data across a cluster of nodes. These frameworks allow for efficient distributed data processing, making it easier to scale the architecture as data volumes grow.
f) Cloud-based Solutions: Adopt cloud-based solutions to scale Big Data Architecture dynamically. Cloud platforms offer auto-scaling capabilities that adjust resources based on demand, allowing you to handle peak workloads efficiently without overprovisioning.
g) Containerisation and Orchestration: Use containerisation tools like Docker to package and deploy big data applications consistently across different environments. Container orchestration platforms like Kubernetes facilitate automated scaling and management of containerised applications, streamlining deployment and scaling processes.
h) In-memory Data Processing: Implement in-memory data processing to reduce data access latency and accelerate data analysis. In-memory technologies, such as Apache Ignite and Redis, store data in RAM, enabling faster read and write operations.
i) Sharding: Employ sharding techniques to break down large datasets into smaller, manageable partitions. Sharding helps distribute data evenly across nodes, improving data retrieval performance and supporting horizontal scaling.
j) Caching: Utilise caching mechanisms to store frequently accessed data in memory, reducing the need to retrieve data from slower storage systems. Caching enhances overall system performance and responsiveness, especially for real-time applications.
k) Auto-scaling: Implement auto-scaling mechanisms to dynamically adjust resources based on workload demands. Auto-scaling ensures that the system can adapt to varying workloads, optimising resource allocation and cost efficiency.
l) Commodity Hardware: Consider using commodity hardware instead of expensive specialised hardware. Commodity hardware is more cost-effective and allows for easier expansion and replacement, facilitating seamless scalability.
Keen to have deeper knowledge of Data analytics, refer to our blog on data Architecture.
Future Scope in Big Data Architecture
Here are the various possibilities in Big Data Architecture, highlighted and discussed in detail as follows:
Advancements in AI and Machine Learning
The future of Big Data Architecture will see a seamless integration of artificial intelligence and machine learning algorithms. As data continues to grow exponentially, AI-driven analytics will become essential for extracting meaningful insights and patterns from vast datasets. This integration will lead to more accurate predictions, personalised recommendations, and intelligent automation, revolutionising industries like healthcare, finance, and marketing.
Edge Computing and IoT Integration
The rapid increase of IoT devices will generate an immense amount of data at the edge of networks. Big Data Architecture will evolve to accommodate edge computing, bringing data processing closer to the data source, reducing latency, and conserving network bandwidth. Integrating IoT data streams into big data architecture will enable real-time analytics, enabling industries like manufacturing and smart cities to leverage immediate insights for improved efficiency and decision-making.
Quantum Computing
As quantum computing technology matures, it will significantly impact Big Data Architecture. Quantum computing's immense processing power will handle complex data analysis tasks, breaking new ground in areas like cryptography, drug discovery, and climate modelling. The integration of quantum computing into big data systems will bring in a new era of data processing capabilities.
Data Privacy and Security
As data breaches and privacy concerns persist, the future of Big Data Architecture will prioritise robust data governance and security. Implementing privacy-preserving techniques like homomorphic encryption and secure multi-party computation will become crucial to protecting sensitive data while allowing analysis. Additionally, advancements in blockchain technology may further enhance data integrity and security in big data ecosystems.
Conclusion
The future of Big Data Architecture holds immense promise and potential. Businesses can harness data-driven insights to transform industries and drive innovation. Big Data Architecture will continue to shape the way data is managed, processed, and utilised, enabling organisations to stay competitive and make informed decisions in an increasingly data-centric world.
Get familiar with the concept of implementing data analytics as a manager, by signing up for the Data Analytics For Project Managers Training now!
Frequently Asked Questions
What is the 5 Layer Architecture of Big Data?

The 5-layer architecture of Big Data includes the Data Ingestion Layer, Data Storage Layer, Data Processing Layer, Data Analysis Layer, and Data Visualisation Layer. Each layer manages specific aspects of handling and analysing large datasets.
What is the Best Architecture for Large Data Sets?
The best architecture for large data sets often depends on the use case, but a distributed, scalable architecture like Lambda or Kappa is ideal. These architectures efficiently process both real-time and batch data, ensuring high performance and flexibility.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 17 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Big Data & Analytics Courses, including Hadoop Big Data Certification Training, Apache Spark Training and Big Data Analytics & Data Science Integration Course. These courses cater to different skill levels, providing comprehensive insights into Key Characteristics of Big Data.
Our Data, Analytics & AI Blogs cover a range of topics related to Big Data, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Big Data Analytics skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Hadoop Big Data Certification
Hadoop Big Data Certification
Hadoop Big Data Certification
Thu 30th Jan 2025
Hadoop Big Data Certification
Thu 27th Feb 2025
Hadoop Big Data Certification
Thu 20th Mar 2025
Hadoop Big Data Certification
Thu 29th May 2025
Hadoop Big Data Certification
Thu 3rd Jul 2025
Hadoop Big Data Certification
Thu 4th Sep 2025
Hadoop Big Data Certification
Thu 20th Nov 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


