



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +971 8000311193 and speak to our training experts, we may still be able to help with your training requirements.
Top 35 NLP Interview Questions and Answers
Sophia Ellis 19 November 2024Discover this blog to grasp the essentials of acing your NLP interviews with these top 35 interview questions and answers. This blog offers an extensive collection of NLP Interview Questions designed to inspire both seasoned professionals and aspiring practitioners alike. Read ahead to ensure your ultimate success in interviews!

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

In today's rapidly evolving digital era, Natural Language Processing (NLP) is pivotal for bridging the gap between human language and machine intelligence. Are you ready to confidently answer NLP interview questions? Let's explore some key topics to make sure you're prepared for success.
Don't let NLP Interview Questions leave you uncertain. Gain a competitive advantage with the insights shared in this guide and be ready to demonstrate your proficiency and excel in those interviews! Keep reading to boost your comprehension and preparedness!
Table of Contents
1) Basic-level NLP Interview Questions and Answers
a) What do you understand by Natural Language Processing?
b) What are stop words?
c) What is Syntactic Analysis?
d) What is Semantic Analysis?
e) List the components of Natural Language Processing.
2) Intermediate -level NLP Interview Questions and Answers
3) Advanced -level NLP Interview Questions and Answers
4) Conclusion
Basic-level NLP Interview Questions and Answers
Here are some basic-level NLP interview questions and answers:
1) What do you understand by Natural Language Processing?
This question is meant to evaluate the candidate's level of understanding of Natural Language Processing.
Here's a sample answer:
“I perceive NLP as a fascinating branch of Artificial Intelligence. It allows me to engage in interactions with humans using natural language, processing vast amounts of textual data to understand, interpret, and generate human-like language.”

2) What are stop words?
The purpose of this question is to evaluate the candidate's understanding of stop words in NLP.
Here's a sample answer:
During the initial processing of natural language text data, stop words tend to be phrases that are removed. In the setting of text analysis tasks like retrieving data or text mining, certain words—"and," "the," "is," and so on—occur regularly and have limited significance. Removing stop words from text data allows attention to be concentrated on the important words that express the main ideas of the text.
3) What is Syntactic Analysis?
The purpose of this question is to assess the candidate's knowledge of Syntactic Analysis in NLP.
Here's a sample answer:
Syntactic Analysis, also referred to as parsing, is a method of examining a sentence or phrase's grammatical structure and relationship between words in natural language. It involves breaking down sentences into their various components and recognising phrases, subject, predicate, and object sentence structures, all in accordance with formal grammar requirements. Syntactic Analysis is essential for many NLP tasks, such as automated translation, grammar checking, and syntax highlighting.
4) What is Semantic Analysis?
The purpose of this question is to gauge the candidate's understanding of Semantic Analysis in NLP.
Here's a sample answer:
By understanding the process and meaning of words, phrases, and sentences, Semantic Analysis extracts meaning from natural language text data. It extends beyond Syntactic Analysis to figure out the word's intended meaning depending on how it is used in a sentence or document.
Machines are now able to comprehend the complexity of human language through Semantic Analysis, which makes jobs like recognising named entities, sentiment analysis, and question-answering systems simpler.
5) List the components of Natural Language Processing.
The purpose of this question is to evaluate the candidate's knowledge of the key components of NLP.
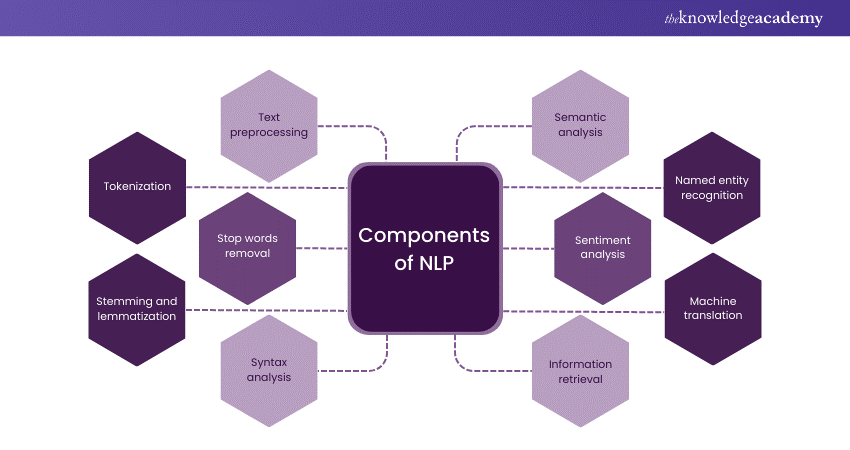
Here's a sample answer:
The components of Natural Language Processing include:
1) Text preprocessing
2) Tokenization
3) Stop words removal
4) Stemming and lemmatization
5) Syntax analysis
6) Semantic analysis
7) Named entity recognition
8) Sentiment analysis
9) Machine translation
10) Information retrieval
6) What is Parsing in the context of NLP?
The purpose of this question is to assess the candidate's understanding of parsing in NLP.
Here's a sample answer:
In NLP, parsing breaks down sentences into their component phrases, clauses, and words to figure out their unique grammatical meaning. For jobs like Syntactic Analysis, machine translation, and grammar identification, it is essential.
7) Define the terminology in NLP.
The purpose of this question is to assess the candidate's understanding of fundamental terminology in Natural Language Processing.
Here's a sample answer:
In NLP, terminology refers to the specialized vocabulary used to describe concepts, techniques, and processes within the field. Examples of NLP terminology include "tokenization," "lemmatization," "part-of-speech tagging," "named entity recognition," and "word embedding."
8) What is the difference between NLP and CI?
The purpose of this question is to assess the candidate's understanding of the distinction between Natural Language Processing and Computational Intelligence (CI).
Here's a sample answer:
In order to allow machines to understand, translate, and produce human language, NLP focuses only on the relationship between computers and human (natural) languages. On the other hand, CI is a broader discipline that includes a range of computational methods, such as NLP, for tasks including problem-solving and decision-making.
9) What are precision and recall?
The purpose of this question is to assess the candidate's understanding of evaluation metrics in information retrieval and classification tasks.
Here's a sample answer:
Precision and recall are two key metrics to take into account while evaluating the efficacy of machine learning models, especially for tasks like text classification and data retrieval. While precision measures the number of relevant events among the retrieved instances, recall shows the percentage of suitable instances that the model succeeded to collect.
10) Explain how we can do parsing.
The purpose of this question is to assess the candidate's understanding of Syntactic Analysis in Natural Language Processing.
Here's a sample answer:
Parsing involves analysing the grammatical structure of sentences to determine their syntactic relationships and hierarchical organization. There are various parsing techniques used in NLP, including constituency parsing and dependency parsing, which employ different algorithms and linguistic theories to parse sentences into syntactic structures.
11) What is the purpose of the multi-head attention mechanism in Transformers?
The purpose of this question is to assess the candidate's understanding of attention mechanisms in deep learning architectures, specifically in the context of Transformer models used in NLP tasks.
Here's a sample answer:
The model may concentrate on different parts of the data series simultaneously due to the multi-headed focus system, which improves its capacity to identify complex patterns and connections. The model may develop deeper representation and perform better on tasks like text generation and machine translation by concentrating on several points in the data it receives series.
Equip yourself with the Artificial Intelligence (AI) For Project Managers Course! Reserve your place today!
Intermediate -level NLP Interview Questions and Answers
For those with a solid grasp of NLP fundamentals, here are some intermediate-level interview questions and answers.
12) What is the Transformer model?
The purpose of this question is to assess the candidate's understanding of a key architecture in Natural Language Processing.
Here's a sample answer:
The Transformer model, from "Attention is All You Need" by Vaswani et al., transformed NLP by replacing traditional recurrent or convolutional layers with self-attention mechanisms. It enables parallel processing and captures long-range dependencies efficiently, comprising encoder and decoder layers of self-attention and feedforward networks.
13) What are the main challenges in NLP?
The purpose of this question is to assess the candidate's awareness of the key hurdles faced in Natural Language Processing.
Here's a sample answer:
Some of the main challenges in NLP include ambiguity and variability in human language, understanding context and semantics, dealing with noisy and unstructured data, handling rare and out-of-vocabulary words, addressing domain adaptation and transfer learning, and achieving robustness and interpretability in machine learning models.
14) What do you mean by Corpus in NLP?
The purpose of this question is to evaluate the candidate's understanding of data sources used in Natural Language Processing.
Here's a sample answer:
“In NLP, I understand a corpus as a significant resource—a large collection of text or speech data carefully compiled and annotated for linguistic analysis and model training. Corpora form the backbone of various NLP tasks like language modelling, sentiment analysis, and named entity recognition, offering crucial data for both training and evaluation purposes.”
15) What is tokenization in NLP?
The purpose of this question is to assess the candidate's understanding of the initial preprocessing step in Natural Language Processing.
Here's a sample answer:
Depending on the tokenization approach used, tokenization involves splitting a text into smaller units of language called tokens, which can be words, sub words, or characters. As a basis for further analysis and processing activities like parsing, part-of-speech tagging, and recognition of named entities, tokenization is an essential step in natural language processing (NLP).
16) What do you mean by perplexity in NLP?
The purpose of this question is to evaluate the candidate's familiarity with a metric used in language modelling tasks in Natural Language Processing.
Here's a sample answer:
“I gauge perplexity as a measure of uncertainty or surprise in my language model when forecasting the next word in a sequence. A lower perplexity signifies improved predictive capability, whereas higher perplexity signifies heightened uncertainty and inferior model performance.”
17) What do you mean by Masked language modelling?
The purpose of this question is to assess the candidate's understanding of a specific training objective used in pretraining language models in Natural Language Processing.
Here's a sample answer:
In masked language modelling, the model has to anticipate the characters that are masked, which are randomly masked throughout the input sequence. The model is encouraged to develop strong representations that retain situational information and make future NLP tasks easier by achieving this training goal.
18) Explain the concept of cosine similarity and its importance in NLP.
The purpose of this question is to assess the candidate's understanding of a similarity measure commonly used in Natural Language Processing.
Here's a sample answer:
Cosine similarity, in NLP, gauges the angle between vectors in high-dimensional space, crucial for tasks like document retrieval, clustering, and recommendation systems. It determines semantic similarity, aiding in information and document retrieval.
19) What are the various types of machine learning algorithms used in NLP?
The purpose of this question is to evaluate the candidate's knowledge of machine learning techniques applicable to Natural Language Processing.
Here's a sample answer:
Various machine learning algorithms are used in NLP, including but not limited to:
1) Naive Bayes
2) Support Vector Machines (SVM)
3) Logistic Regression
4) Decision Trees
5) Random Forests
6) Gradient Boosting Machines (GBM)
7) Neural Networks (e.g., Feedforward, Convolutional, Recurrent)
Each algorithm has its strengths and weaknesses, and the choice depends on the specific NLP task, dataset characteristics, and computational resources available.
20) What is topic modelling in NLP?
The purpose of this question is to assess the candidate's understanding of a technique used for uncovering latent thematic structure in a collection of documents.
Here's a sample answer:
Topic modelling in NLP automatically identifies themes in text documents. Algorithms like LDA and NMF are common. It aids in tasks such as document clustering, summarisation, and data analysis.
21) What are the various algorithms used for training word embeddings?
The purpose of this question is to evaluate the candidate's knowledge of techniques for learning distributed representations of words in Natural Language Processing.
Here's a sample answer:
Several algorithms are used for training word embeddings, including:
1) Word2Vec
2) GloVe
3) FastText
4) ELMo
5) BERT
6) GPT
These algorithms capture semantic and syntactic similarities between words, enabling downstream NLP tasks such as sentiment analysis, named entity recognition, and machine translation.
22) What is word sense disambiguation?
The purpose of this question is to assess the candidate's understanding of a task in Natural Language Processing aimed at determining the correct meaning of a word in context.
Here's a sample answer:
For NLP tasks like retrieving data and translation by machine, word sense disambiguation is crucial as it determines the true purpose of a word based on its setting. It's essential for accurate semantic interpretation, particularly in question answering systems.
23) What is the conditional random field (CRF) model in NLP?
The purpose of this question is to evaluate the candidate's knowledge of a probabilistic graphical model used for sequence labelling tasks in NLP.
Here's a sample answer:
Modelling the conditional probability distribution of label sequences given information as input, discriminative statistical models, or CRFs, are a form of model. CRFs are widely used in applications where the output labels depend on the setting, such as splitting, recognising named entities, and part-of-speech tagging.
24) What is a recurrent neural network (RNN)?
The purpose of this question is to assess the candidate's understanding of a type of neural network architecture commonly used in NLP for sequential data processing.
Here's a sample answer:
A Recurrent Neural Network is a type of artificial neural network designed to handle sequential data by maintaining a hidden state that captures information about previous inputs. RNNs are well-suited for tasks such as language modelling, and sentiment analysis, where understanding context and temporal dependencies is crucial.
25) How does the Backpropagation through time work in RNN?
The purpose of this question is to evaluate the candidate's understanding of the training algorithm used for updating parameters in Recurrent Neural Networks.
Here's a sample answer:
Backpropagation through time (BPTT) extends backpropagation for RNN training. It unrolls the network through time, computes gradients using the chain rule, and considers input-output pairs, enabling effective learning of long-range dependencies and temporal dynamics.
Advanced -level NLP Interview Questions and Answers
Delving deeper into the intricacies of NLP, let's explore a selection of advanced-level interview questions and their detailed answers.
26) What do you mean by TF-IDF in Natural language Processing?
The purpose of this question is to assess the candidate's understanding of a common term weighting scheme used in NLP.
Here's a sample answer:
TF-IDF (Term Frequency-Inverse Document Frequency) is a numerical statistic that reflects the importance of a term in a document relative to a collection of documents. TF-IDF is computed by multiplying the term frequency (TF), indicating a term's frequency in a document, with the inverse document frequency (IDF), which penalises common terms. IDF highlights unique terms in a document compared to others.
27) What do you mean by Autoencoders?
This question assesses understanding of an artificial neural network used for unsupervised tasks like dimensionality reduction and feature learning.
Here's a sample answer:
Autoencoders are neural network models trained to reconstruct input data at the output layer. They learn a compressed representation (encoding) in a lower-dimensional space, then decode it back to the original data space. Autoencoders comprise an encoder mapping input to a latent space and a decoder reconstructing data from the latent representation.
28) What are some of the common NLP tasks?
The purpose of this question is to assess the candidate's familiarity with the variety of tasks addressed within the field of Natural Language Processing.
Here's a sample answer:
NLP tasks include Sentiment Analysis, Named Entity Recognition (NER), Part-of-Speech Tagging (POS), Machine Translation, Text Summarization, Question Answering, and Text Classification. These tasks are fundamental to various applications such as search engines, chatbots, virtual assistants, and text analytics.
29) How do Conversational Agents work?
The purpose of this question is to assess the candidate's understanding of the underlying mechanisms of Conversational Agents, also known as chatbots or virtual assistants.
Here's a sample answer:
Conversational Agents utilise NLP techniques to comprehend and respond to user input. They involve intent recognition, entity extraction, dialogue management, and response generation. Agents can be rule-based or employ machine learning to enhance responses.
30) What are the steps involved in preprocessing data for NLP?
The purpose of this question is to evaluate the candidate's understanding of the preprocessing steps necessary to prepare text data for Natural Language Processing tasks.
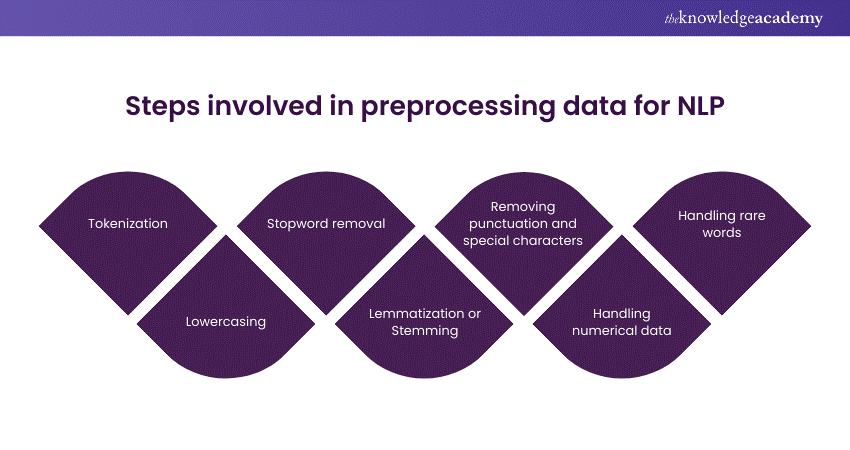
Here's a sample answer:
The preprocessing steps typically include:
1) Tokenization: Breaking text into individual words or sub words.
2) Lowercasing: For sake of uniformity, all text should be converted to lowercase.
3) Stopword removal: Removing common terms that don't add much sense, such as "the," "is," and "and."
4) Lemmatization or stemming: Reducing words to their base or root form to normalize variations.
5) Removing punctuation and special characters: Eliminating non-alphabetic characters that do not contribute to meaning.
6) Handling numerical data: Converting numbers to text or removing them depending on the task.
7) Handling rare words: Dealing with rare or out-of-vocabulary words by replacing them or grouping them together.
These preprocessing steps help to clean and standardize the text data before feeding it into NLP models for further analysis.
31) What is an ensemble method in NLP?
This question evaluates understanding of ensemble methods, enhancing NLP models with combined predictions.
Here's a sample answer:
Ensemble methods in NLP train multiple models, then combine their predictions through techniques like voting, averaging, or stacking. Ensemble methods help to reduce overfitting, increase robustness, and improve overall performance by leveraging the diversity of individual models' strengths and weaknesses.
32) What is Parts-of-speech tagging?
This question aims to assess the candidate's grasp of a vital task in Natural Language Processing - assigning grammatical categories to words in a sentence.
Here's a sample answer:
Parts-of-speech (POS) tagging entails labelling each word with its corresponding part of speech (e.g., noun, verb, adjective). It's crucial for various NLP tasks like Syntactic Analysis, and machine translation, offering vital syntactic insights into sentence structure and meaning.
33) What do you mean by a Bag of Words (BOW)?
This question aims to evaluate the candidate's comprehension of a basic and widely used model in Natural Language Processing - the Bag of Words model.
Here's a sample answer:
BOW represents text data as a set of unique words and their frequencies in a document, ignoring grammar and word order. Each document is depicted as a vector where each dimension stands for a unique word, and the value indicates the word's frequency or presence in the document.
34) What is the meaning of N-gram in NLP?
The purpose of this question is to assess the candidate's understanding of a sequence of N items from a given text or speech.
Here's a sample answer:
In NLP, an N-gram is a sequence of N words from a text, used to model language statistics and word co-occurrence. Common types include unigrams, bigrams, and trigrams, aiding in tasks like language modelling, translation, and spell checking by capturing contextual word patterns.
35) What are some metrics on which NLP models are evaluated?
The purpose of this question is to evaluate the candidate's awareness of evaluation metrics used to assess the performance of Natural Language Processing models.

Here's a sample answer:
Some common metrics for evaluating NLP models include:
1) Accuracy: Correct predictions among total instances
2) Precision: True positives among all positive predictions
4) Recall: True positives among actual positives
5) F1-score: Harmonic mean of precision and recall
6) BLEU (Bilingual Evaluation Understudy): Evaluates machine translation quality
7) ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Assesses summarization tasks
8) Perplexity: Measures probability distribution effectiveness in language modelling
These metrics help researchers and practitioners assess the effectiveness and quality of NLP models across various tasks and datasets.
Take the next step in your career with our Machine Learning Course- sign up now!
Conclusion
In conclusion, Natural Language Processing stands at the forefront of Artificial Intelligence, bridging the gap between human language and machine understanding. As NLP techniques evolve, mastering NLP Interview Questions is crucial for unlocking new possibilities in human-computer interaction and intelligent systems.
Unlock the power of AI and Machine Learning with our Natural Language Processing (NLP) Fundamentals With Python Course. Book your spot now!
Frequently Asked Questions
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Natural Language Processing (NLP) Fundamentals with Python
Natural Language Processing (NLP) Fundamentals with Python
Natural Language Processing (NLP) Fundamentals with Python
Thu 30th Jan 2025
Natural Language Processing (NLP) Fundamentals with Python
Thu 27th Mar 2025
Natural Language Processing (NLP) Fundamentals with Python
Thu 29th May 2025
Natural Language Processing (NLP) Fundamentals with Python
Thu 24th Jul 2025
Natural Language Processing (NLP) Fundamentals with Python
Thu 25th Sep 2025
Natural Language Processing (NLP) Fundamentals with Python
Thu 27th Nov 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


