



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +40 316317743 and speak to our training experts, we may still be able to help with your training requirements.
Data Independence in DBMS: An Overview
Sienna Roberts 21 November 2024This blog delves into the concept of Data Independence in DBMS, exploring its significance, types, benefits, and challenges. It provides a comprehensive understanding of how Data Independence helps maintain flexibility in database systems. This ensures changes in the Database do not disrupt Applications or User Interfaces.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Data independence is a critical concept in the field of database management systems (DBMS). It refers to the capability of changing the schema at one level of the database system without requiring a change to the schema at the next higher level. This feature is crucial for the flexibility, scalability, and maintainability of database systems. This also ensures smooth operations even as the underlying Data evolves. Continue reading below to explore data independence, its types, and why it’s a fundamental concept in the design and management of database systems.
Table of Contents
1) What is Data Independence in DBMS?
2) Types of Data Independence
3) Distinction Between Logical Data Independence & Physical Data Independence
4) Benefits of Data Independence
5) Drawbacks of Data Independence
6) Conclusion
What is Data Independence in DBMS?
Data independence in DBMS refers to a database system's capacity to change the schema at one level without requiring changes at the next higher level. This concept is crucial for ensuring that the database can evolve without affecting the applications or User Interfaces (UI) that interact with it. Data independence allows for modifications in the database’s physical or logical schema without disrupting the overall functionality.
In a database system, data is typically organised into three levels:
1) The physical level (how data is stored).
2) The logical level (how data is structured and related).
3) The view level (how data is presented to users).
Data independence ensures that changes at the lower levels do not necessitate changes at the higher levels, thereby preserving the database system's integrity and usability.

Types of Data Independence
In DBMS, data independence is categorised into two primary types: Logical data independence and physical data independence. Each type plays an important role in maintaining the database system's flexibility and resilience.
Logical Data Independence
Logical data independence refers to changing the logical schema—how data is organised and structured—without altering the external schema or application programs that access the Data. This means that tables, views, or other database structures can be changed without affecting how users interact with the data.
Examples of Changes Under Logical Data Independence:
a) Adding or Removing Fields: You can add new attributes to a table or remove existing ones without impacting the End-User applications. For instance, if a new column needs to be added to a customer table to store additional information, this change can be made without requiring modifications to the application code that queries or updates the customer data.
b) Merging Tables: If two related tables must be combined into a single table, logical data independence allows this change without disrupting how users or applications access data. For example, merging an orders table with a customer table to simplify data retrieval can be done without requiring changes to the application logic.
c) Redefining Relationships: Changes between entities, such as altering foreign vital constraints or normalising data, can be made at the logical schema level without needing to rewrite queries or application code. This allows the database structure to evolve and improve without impacting existing functionality.
Physical Data Independence
Physical data independence is the ability to change the physical schema—how data is stored on the hardware—without affecting the logical schema or the external applications. This includes changes in storage devices, indexing strategies, or data compression methods.
Examples of Changes Under Physical Data Independence:
a) Changing Storage Devices: Data can be moved from one storage device to another, such as from Hard Disk Drives (HDDs) to Solid-State Drives (SSDs), without altering the logical structure of the database. This allows for hardware upgrades and optimisations without impacting the way data is accessed or organised.
b) Modifying Indexing Strategies: Adjusting the indexing strategy used to store and retrieve data, such as changing from a B-tree index to a hash index, can improve performance without affecting the logical schema or requiring changes to application code. This enables the database to be optimised for specific workloads without disrupting existing functionality.
c) Optimising Data Storage: Implementing data compression, partitioning, or other storage optimisation techniques can be done at the physical schema level without affecting the logical organisation of the data. This permits more efficient use of storage resources while maintaining data integrity and accessibility.
Master high-performance data management with our Redis Cluster Database Training. Sign up now!
Difference Between Logical Data Independence & Physical Data Independence
While both logical and physical data independence contribute to the overall flexibility and resilience of a database system, they address different aspects of Data Management and have distinct implications:
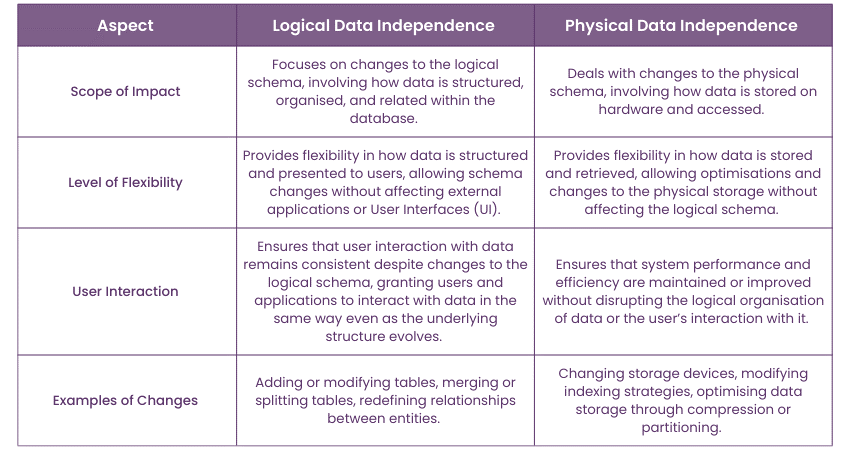
Understanding these differences is important for effectively managing and maintaining a robust and flexible database system.
Benefits of Data Independence
Data independence offers numerous benefits that contribute to the efficiency, flexibility, and longevity of a database system:

a) Adaptability: Databases can evolve as business needs change without requiring a complete system overhaul. This adaptability is crucial in dynamic business environments where data requirements frequently shift.
b) Cost-effective Maintenance: Data independence reduces the need for costly and time-consuming rewrites of applications when changes are made to the database. By isolating the impact of changes to specific levels of the database, data independence allows for more efficient and cost-effective maintenance.
c) Consistent User Experience: Data independence ensures that users continue interacting with the data seamlessly, even as underlying structures are modified. This consistency is vital in environments where users rely on steady access to data for their daily operations.
d) Enhanced Performance: Data independence optimises physical storage and retrieval methods without disrupting logical data structures. This can lead to notable improvements in system performance, as the database can be fine-tuned to maximise efficiency while maintaining the integrity and usability of the data.
e) Future-proofing: Data independence makes the database more resilient to future changes, ensuring it can adapt to new technologies and requirements. As new technologies and methodologies emerge, the ability to incorporate these changes without disrupting existing operations is critical for ensuring the longevity and relevance of the database system.
These benefits make data independence an essential feature in any modern DBMS, supporting current operations and future growth.
Unlock the power of data with our Relational Databases & Data Modelling Training. Join now!
Drawbacks of Data Independence
While data independence provides many advantages, it is not without its challenges:
a) Complex Implementation: Achieving data independence requires a well-designed DBMS, which can be complex and resource-intensive to develop and maintain. Separating logical and physical schemas requires careful planning and design to ensure the system operates efficiently.
b) Performance Overhead: Abstracting the logical and physical schemas can introduce performance overhead, mainly if not managed efficiently. The additional layers of abstraction can slow down data retrieval and processing, leading to reduced system performance.
c) Initial Cost: The upfront cost of implementing a DBMS that supports strong data independence can be higher than that of more straightforward, less flexible systems. Organisations must weigh the long-term benefits of data independence against the initial investment required to implement it.
d) Training and Expertise: Maintaining data independence requires skilled personnel who understand the database's technical and functional aspects. Effectively maintaining data independence requires ongoing training and expertise in database design, management, and optimisation.
Despite these challenges, the benefits of data independence often outweigh the drawbacks, particularly for organisations that require flexible and scalable database solutions.
Conclusion
Data independence in DBMS is a powerful feature that allows organisations to maintain flexibility, scalability, and efficiency in their database systems. By separating data management's logical and physical aspects, databases can evolve and adapt without disrupting user interactions or requiring costly rewrites. Understanding and leveraging data independence is vital to building robust, future-proof database systems that can meet the demands of a dynamic business environment.
Integrate seamlessly with our GraphQL Database Training With React. Join now!
Frequently Asked Questions
What is The Key Distinction Between Logical and Physical Data Independence?

Logical data independence allows changes to the logical schema without affecting the external applications, while physical data independence allows modifications to the physical storage without impacting the logical schema.
Why is Data Independence Important in DBMS?
Data independence is crucial because it allows a database to adapt to changes over time without disrupting the applications or user interfaces (UI) that rely on the data, ensuring flexibility and reducing maintenance costs.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Database Training, including the Introduction to Database Training, Redis Cluster Database Training and Relational Databases & Data Modelling Training. These courses cater to different skill levels and provide comprehensive insights into Magento vs Wordpress.
Our Programming & DevOps blogs cover a range of topics related to Database Training, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Database Administration Skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Programming & DevOps Resources Batches & Dates
Date
 Introduction to Database Training
Introduction to Database Training
Introduction to Database Training
Fri 21st Feb 2025
Introduction to Database Training
Fri 25th Apr 2025
Introduction to Database Training
Fri 20th Jun 2025
Introduction to Database Training
Fri 22nd Aug 2025
Introduction to Database Training
Fri 17th Oct 2025
Introduction to Database Training
Fri 19th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


