



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +40 316317743 and speak to our training experts, we may still be able to help with your training requirements.
Hadoop vs MongoDB: Key Differences
Gracey Smith 20 March 2025Explore Hadoop vs MongoDB to grasp the fundamental distinctions between these two prominent data management solutions. While Hadoop excels at distributed data processing, MongoDB specialises in NoSQL document-oriented databases. This blog dives into the core disparities, helping you make informed decisions for your data management needs.
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.

Hadoop and MongoDB are two popular solutions that cater to different data management needs in the domain of big data analytics. Each has its unique strengths and use cases, and understanding their differences is crucial for making informed decisions. In this blog, we will dive into a detailed comparison of Hadoop vs MongoDB, comparing their architecture, data models, query languages, and use cases.
Table of Contents
1) What is Hadoop?
2) What is MongoDB?
3) Hadoop vs MongoDB: What’s the difference?
a) Data storage and processing
b) Schema flexibility
c) Scalability
d) Query performance
e) Use cases
4) Which one should I choose?
5) Conclusion
What is Hadoop?
Hadoop is an open-source distributed computing framework that has become a cornerstone in the world of big data processing. It was developed by the Apache Software Foundation (ASF) and is widely used by companies and organisations to handle and analyse large volumes of data efficiently.
At the core of Hadoop's architecture lies the Hadoop Distributed File System (HDFS). This distributed file system is designed to store vast amounts of data across multiple machines in a cluster. The data is broken down into smaller blocks, typically 128 megabytes or 256 megabytes in size, and distributed across nodes in the cluster. This distribution of data ensures fault tolerance and enables data processing to occur in parallel, which significantly enhances performance. While preparing for roles in big data, reviewing Hadoop Interview Questions can provide a deeper understanding of its architecture, components, and best practices.
Unlock the power of big data with our comprehensive Hadoop Big Data Certification!
What is MongoDB?
MongoDB is a popular NoSQL database management system known for its flexibility and scalability. As opposed to traditional relational databases, MongoDB follows a document-oriented data model, making it highly suitable for managing unstructured and semi-structured data. This open-source database has gained widespread adoption across industries for its ability to handle modern data requirements effectively.
At the heart of MongoDB's data model are collections and documents. A collection is a grouping of related documents, and each document represents a record in the database. These documents use a format called BSON (Binary JSON), which is similar to JSON (JavaScript Object Notation). BSON allows for efficient storage and retrieval of data, making MongoDB well-suited for real-time and dynamic applications.
Master MongoDB for app and web development by registering for our MongoDB Developer Training now!
Hadoop vs MongoDB: What’s the difference?
Now that we know what MongoDB and Hadoop are, now we will expand on the differences between Hadoop and MongoDB below.
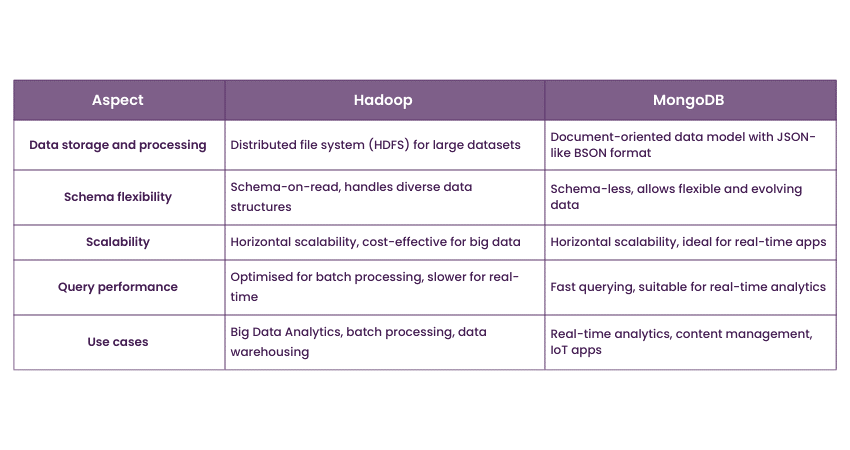
Data storage and processing
Hadoop and MongoDB have fundamentally different approaches to data storage and processing. Hadoop is based on a distributed file system known as HDFS (Hadoop Distributed File System). It breaks down large datasets into smaller blocks and distributes them across multiple nodes in a cluster. This distributed storage and processing capability allow Hadoop to handle vast amounts of data efficiently, making it a preferred choice for big data processing tasks.
On the other hand, MongoDB is a NoSQL document-oriented database. It stores data in JSON-like BSON format, where each record represents a document. MongoDB is designed for real-time and transactional workloads, making it suitable for use cases that require rapid access to data, such as web applications and content management systems. The storage model in MongoDB is optimised for quick retrieval and manipulation of data at the document level, making it ideal for scenarios where real-time querying is essential.
Schema flexibility
Another significant difference between Hadoop and MongoDB lies in their schema flexibility. Hadoop follows a schema-on-read approach, meaning data does not require a predefined schema before it is stored. This schema flexibility allows Hadoop to handle various data types and formats, making it well-suited for unstructured and semi-structured data. However, it also means that data validation and formatting occur during the data processing phase, which may lead to some complexities in data processing workflows.
In contrast, MongoDB adopts a schema-less data model. It allows for dynamic and evolving data structures within the same collection. This schema flexibility is advantageous in scenarios where the data schema is likely to change over time or if there are multiple variations of data records. Developers can easily modify document structures without the need for extensive database migrations, providing more agility and adaptability in data-driven applications.
Scalability
Scalability is a critical consideration when dealing with large datasets and high-throughput applications. Both Hadoop and MongoDB offer scalability, but their approaches differ. Hadoop is inherently designed for horizontal scalability. As data volume grows, more nodes can be added to the Hadoop cluster, distributing the workload and ensuring efficient data processing. This scalability makes Hadoop a cost-effective solution for handling big data tasks across a large number of nodes.
MongoDB, too, provides horizontal scalability through a technique called Sharding. Sharding involves partitioning data across multiple servers, allowing for data distribution and parallel processing. However, MongoDB's scalability is more suitable for real-time applications with rapid data access requirements. It excels in handling read and write operations efficiently as the database scales, making it an excellent choice for use cases where low latency and responsiveness are crucial.
Query performance
Query performance is a crucial aspect of any data management system. Hadoop's primary data processing paradigm is MapReduce, which involves breaking down data processing tasks into map and reduce phases. While Hadoop can efficiently handle batch processing tasks, its query performance for real-time data retrieval is relatively slower compared to MongoDB.
MongoDB, on the other hand, provides powerful and flexible query capabilities through its JSON-like query language. It allows for indexing and supports a wide range of queries, including complex aggregations and geospatial queries. As a result, MongoDB excels in real-time data retrieval and analytics use cases, making it an optimal choice for applications that require quick access to up-to-date information.
Use cases
Hadoop and MongoDB cater to different use cases due to their distinctive features and strengths. Hadoop is best suited for scenarios involving large-scale batch processing, such as ETL (Extract, Transform, Load) tasks, log analysis, data warehousing, and machine learning. Its ability to process massive datasets efficiently makes it a go-to solution for big data Analytics, where extensive computations are performed on distributed data.
On the other hand, MongoDB shines in real-time Data Analytics, content management systems, IoT (Internet of Things) applications, and mobile app development. It’s schema-less design and horizontal scalability make it an excellent choice for applications that need quick access to data, such as real-time dashboards, customer analytics, and content-driven platforms.
Grab the Hadoop HDFS Commands Cheat Sheet for a handy guide on essential Hadoop commands.
Which one should I choose?
When deciding between Hadoop or MongoDB, consider the following pointers to make an informed choice:

1) Data type and structure: Assess the diversity of your data. If it comes in various formats and lacks a fixed structure, Hadoop's schema-on-read approach makes it adaptable for handling unstructured and semi-structured data. Alternatively, if your data is relatively structured and requires flexibility, MongoDB's schema-less design provides agility in dealing with evolving data.
2) Scalability: Consider the scalability needs of your project. Hadoop's horizontal scalability is cost-effective for large-scale batch processing and big data Analytics. MongoDB's horizontal scalability, on the other hand, caters to real-time applications with rapid data access requirements.
3) Query performance: Evaluate the query performance required for your use case. Hadoop excels in batch processing, while MongoDB's rich query language and indexing capabilities make it suitable for real-time analytics and fast data retrieval.
4) Use cases: Identify your specific application requirements. Hadoop is well-suited for big data Analytics, data warehousing, and batch processing tasks. In contrast, MongoDB shines in real-time analytics, content management, IoT applications, and mobile development.
5) Team skills and familiarity: Consider your development team's expertise. Hadoop's MapReduce may require additional training, while MongoDB's JSON-like data model could be easier for developers familiar with NoSQL databases.
6) Budget and infrastructure: Evaluate the cost implications. Hadoop's distributed architecture might require a larger initial investment in hardware, while MongoDB's scalability offers a more cost-effective scaling approach.

Conclusion
Both Hadoop and MongoDB are powerful tools for data management, each excelling in different areas. Hadoop is a robust choice for batch processing and big data analytics, while MongoDB shines in real-time data analytics and dynamic applications. Consider your specific requirements, data characteristics, and workload before making a decision. Hope we could provide you with the detailed comparison for Hadoop vs MongoDB you were looking for!
Unlock your potential in app and web development with our expert App & Web Development Training Courses. Sign up now!
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 MongoDB Certification Course
MongoDB Certification Course
MongoDB Certification Course
Fri 25th Apr 2025
MongoDB Certification Course
Fri 20th Jun 2025
MongoDB Certification Course
Fri 22nd Aug 2025
MongoDB Certification Course
Fri 17th Oct 2025
MongoDB Certification Course
Fri 19th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


