



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +40 316317743 and speak to our training experts, we may still be able to help with your training requirements.
What are Python Data Structures? Explained in detail
Sienna Roberts 21 September 2023Imagine you have a toolbox filled with different tools, each designed for a particular task. Similarly, Python offers a variety of data structures, each with unique features and use cases. In this blog, we will discuss the various Python data structures, including lists, tuples, dictionaries, sets, linked lists, trees, graphs, and more.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Python, with its elegant syntax and extensive libraries, empowers developers to create efficient and expressive code. At its core, Python offers a rich variety of data structures, each serving a unique purpose. From the humble list to the intricate graph, these Python Data Structures enable us to organise, manipulate, and analyse data with finesse.
And here’s the exciting part: not only does mastering Python enhance your coding skills, but it also opens doors to lucrative opportunities. In the UK, Python Developers command an average annual salary of around £95,000. So, let’s explore Python Data Structure; the building blocks of Python—lists, tuples, dictionaries, sets, and more—unleashing their potential in our code journey!
Table of Contents
1) Understanding Data Structures in Python
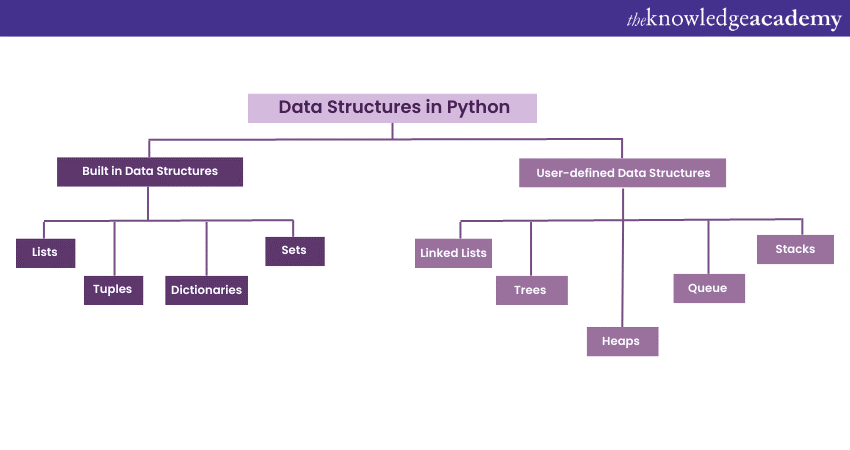
2) Built-in Data Structures
3) User-defined Data Structures
4) Sets and Multisets
5) Python Data Structures and Algorithms
6) Python Data Structures: Advantages and Disadvantages
7) Conclusion
Understanding Data Structures in Python
In programming, Data Structures are containers used to organise and store data in a way that facilitates efficient access and modification. Python provides several built-in Data Structures, each with its own unique characteristics and use cases. These Data Structures serve as the foundation for creating complex algorithms and solving computational problems effectively.
Python Data Structures play a crucial role in optimising code performance. By choosing the right Data Structure for a specific problem, developers can reduce time complexity and improve the overall efficiency of their programs. Understanding Data Structures enables programmers to make informed decisions while designing solutions, leading to more elegant and maintainable code.
The choice of Data Structure can greatly impact the performance of algorithms. For example, using a dictionary for fast key-value lookups or a set for eliminating duplicates in a list can result in faster execution times. Developers can understand the underlying principles of Data Structures and write code that runs more efficiently. This makes Python a popular choice for high-performance applications.

Built-in Data Structures
Python provides a robust set of built-in Data Structures that are essential to programming. These Data Structures include lists, tuples, dictionaries, sets, and more. Each structure serves unique purposes, facilitating efficient data storage, retrieval, and manipulation. Using Python's built-in Data Structures enhances code organisation and accelerates software development.
Lists: Versatile and Dynamic Arrays
Python provides a robust set of built-in Data Structures that are essential to programming. These Data Structures include lists, tuples, dictionaries, sets, and more. Each structure serves unique purposes, facilitating efficient data storage, retrieval, and manipulation. Using Python's built-in Data Structures enhances code organisation and accelerates software development.
Creating Lists and List Operations
To create a list in Python, enclose the elements within square brackets, separated by commas:
|
my_list = [1, 2, 3, "hello", True] |
Lists support various operations, including appending elements, extending lists, and concatenating lists:
|
numbers = [1, 2, 3] numbers.append(4) # [1, 2, 3, 4] numbers.extend([5, 6]) # [1, 2, 3, 4, 5, 6] another_list = [7, 8] concatenated = numbers + another_list # [1, 2, 3, 4, 5, 6, 7, 8] |
Accessing elements in a list is done using zero-based indexing:
|
my_list = [10, 20, 30, 40, 50] print(my_list[0]) # Output: 10 print(my_list[-1]) # Output: 50 |
List slicing enables you to extract a portion of the list efficiently:
|
numbers = [1, 2, 3, 4, 5, 6] subset = numbers[1:4] # Output: [2, 3, 4] |
Python provides several built-in methods for manipulating lists, such as sorting, counting occurrences, and removing elements:
|
numbers = [5, 2, 1, 4, 3] numbers.sort() # [1, 2, 3, 4, 5] count_twos = numbers.count(2) # 1 numbers.remove(3) # [1, 2, 4, 5] |
List comprehensions are a simple and concise way to create lists in Python. They allow you to build a new list by applying an expression to each element of an existing list:
|
numbers = [1, 2, 3, 4, 5] squared_numbers = [num ** 2 for num in numbers] # [1, 4, 9, 16, 25] |
List comprehensions simplify code and improve readability when creating transformed lists.
2) Tuples: Immutable Data Containers
In Python, like lists, tuples offer the same capabilities but with one crucial difference - they are immutable. This means their elements cannot be changed after creation. Tuples are defined using parentheses:
|
my_tuple = (1, 2, 3, "hello", True) |
Creating a tuple is simple; you can define it with elements separated by commas:
|
my_tuple = (1, 2, 3) |
Accessing elements in a tuple is the same as with lists, using zero-based indexing:
|
print(my_tuple[0]) # Output: 1 |
Tuples are commonly used to represent fixed collections of data that should not be modified. The immutability of tuples makes them useful for cases where data should not change throughout the program's execution. They are used for data that needs to remain constant, such as coordinates, RGB values, and database records.
While both tuples and lists have their use cases, tuples are preferred when immutability is necessary. If data needs to be altered or updated, lists are the more appropriate choice. Tuples are also more memory-efficient than lists, making them valuable for data that should not be modified.
3) Dictionaries: Efficient Key-value Pairs
Dictionaries are an important Data Structure in Python that store data in key-value pairs. Each dictionary key must be unique, and keys are used to access their corresponding values in an efficient way.
To create a dictionary, you use curly braces and specify key-value pairs:
|
my_dict = {"name": "John", "age": 30, "city": "New York"} |
Accessing values in a dictionary is done through their keys:
|
print(my_dict["name"]) # Output: John |
Dictionaries offer several methods for adding, removing, or modifying key-value pairs:
|
my_dict["occupation"] = "Engineer" # Adding a new key-value pair my_dict["age"] = 31 # Modifying an existing value del my_dict["city"] # Removing a key-value pair |
Dictionaries are ideal for situations that involve mapping unique keys to values. They are commonly used to store and retrieve data in scenarios like database records, configuration settings, and JSON data.
4) Sets: Unordered collection of unique elements
A set has an unordered collection of unique elements. Unlike lists and tuples, sets do not allow duplicate values, making them perfect for eliminating duplicates from a sequence.
In Python, a set can be created by enclosing elements within curly braces or using the set() constructor:
|
my_set = {1, 2, 3, 4, 5} another_set = set([3, 4, 5, 6, 7]) |
Sets support various operations, including union, intersection, and difference:
|
set_a = {1, 2, 3} set_b = {3, 4, 5} union_set = set_a | set_b # {1, 2, 3, 4, 5} intersection_set = set_a & set_b # {3} difference_set = set_a - set_b # {1, 2} |
Similar to list comprehensions, Python supports set comprehensions, allowing you to create sets using concise expressions:
|
numbers = [1, 2, 2, 3, 3, 4, 5] unique_numbers = {num for num in numbers} # {1, 2, 3, 4, 5} |
Sets are valuable for tasks that require unique elements, such as counting distinct items in a sequence or performing set-based mathematical operations.
Unlock your coding potential by joining our Python Course!
User-defined Data Structures
User-defined Data Structures in Python allow developers to create custom data storage and manipulation solutions tailored to specific needs. By defining custom classes, programmers get control over data organisation and efficiency. This enables code reusability, abstraction, and modularity for more effective and flexible programming.
1) Linked Lists: Building Blocks for Dynamic Data Structures
Linked lists are fundamental Data Structures composed of nodes, where each node contains data and a reference (pointer) to the next node in the sequence. Unlike arrays, linked lists do not require contiguous memory allocation, allowing for more flexibility and efficient memory usage.
There are different types of linked lists, with singly linked lists and doubly linked lists being the most common:
Singly Linked Lists: In a singly linked list, each node points to the following node in the sequence. The last node points to NULL (or None in Python), indicating the end of the list.
|
class Node: def __init__(self, data): self.data = data self.next = None
# Creating a singly linked list head = Node(1) second = Node(2) third = Node(3)
head.next = second second.next = third |
Doubly Linked Lists: A doubly linked list extends the concept of a singly linked list by having each node point to both the next and previous nodes.
|
class Node: def __init__(self, data): self.data = data self.prev = None self.next = None # Creating a doubly linked list head = Node(1) second = Node(2) third = Node(3) head.next = second second.prev = head second.next = third third.prev = second |
In a circular linked list, the last node reroutes back to the first node, creating a circular structure. This can be useful in scenarios where continuous iteration is required, such as in game development or task scheduling.
Linked lists are valuable for implementing dynamic Data Structures, such as stacks and queues, and are used in various programming and algorithmic concepts. Linked lists offer several advantages, such as efficient insertion and deletion operations, as well as dynamic memory allocation. However, they have some drawbacks, including slower access time due to the need to traverse the list linearly.
1) Trees: Hierarchical Representations of Data
Trees are hierarchical Data Structures comprising nodes connected by edges. Each tree has a root node at the top, from which other nodes branch out. Trees are mostly used to represent hierarchical relationships, such as file systems, family trees, and organisation charts.
Binary Trees and Binary Search Trees (BST): Binary trees are trees where each node has two offspring, commonly referred to as the left child and right child. Binary search trees (BST) are a type of binary tree with a specific property. The value of a node's left child is less than or equal to the node's value. At the same time, the value of the right child is greater than the node's value.
|
class Node: def __init__(self, key): self.key = key self.left = None self.right = None # Creating a binary search tree root = Node(5) root.left = Node(3) root.right = Node(8) root.left.left = Node(2) root.left.right = Node(4) root.right.left = Node(7) root.right.right = Node(9) |
Tree traversal involves visiting all nodes in a tree in a specific order. There are three common techniques for tree traversal:
In-order Traversal: In in-order traversal, the left subtree is visited first, followed by the root node, and then the right subtree.
|
def in_order_traversal(node): if node: in_order_traversal(node.left) print(node.key) in_order_traversal(node.right) in_order_traversal(root) # Output: 2, 3, 4, 5, 7, 8, 9 |
Pre-order Traversal: In pre-order traversal, the root node is visited first, followed by the left and right subtrees.
|
def pre_order_traversal(node): if node: print(node.key) pre_order_traversal(node.left) pre_order_traversal(node.right) pre_order_traversal(root) # Output: 5, 3, 2, 4, 8, 7, 9 |
Post-order Traversal: In post-order traversal, the left and right subtrees are visited first, followed by the root node.
|
def post_order_traversal(node): if node: post_order_traversal(node.left) post_order_traversal(node.right) print(node.key) post_order_traversal(root) # Output: 2, 4, 3, 7, 9, 8, 5 |
Balancing Binary Search Trees: Balancing a binary search tree ensures that its height is minimised, resulting in faster access times and more efficient tree operations. Common balancing techniques include AVL trees and red-black trees.
Graphs: Connecting the Dots in Data
Graphs are collections of nodes (vertices) connected by edges (lines). They are used to model relationships between objects. Graphs are widely used in various real-world scenarios, such as social networks, computer networks, and transportation systems.
In Python, you can represent graphs using various methods, such as adjacency lists and adjacency matrices.
Adjacency Lists: In an adjacency list representation, each node has a list of its neighbouring nodes.
|
graph = { 1: [2, 3], 2: [1, 4], 3: [1, 5], 4: [2], 5: [3] } |
Adjacency matrices: In an adjacency matrix representation, a 2D array is used to indicate connections between nodes.
|
graph = [ [0, 1, 1, 0, 0], [1, 0, 0, 1, 0], [1, 0, 0, 0, 1], [0, 1, 0, 0, 0], [0, 0, 1, 0, 0] ] |
Graph traversal involves visiting all nodes in a graph in a specific order. Common graph traversal algorithms include depth-first search (DFS) and breadth-first search (BFS).
Depth-First Search (DFS): DFS explores each branch as much as possible before backtracking. It can be implemented using recursion or a stack.
|
def dfs(graph, node, visited): if node not in visited: visited.add(node) for neighbor in graph[node]: dfs(graph, neighbor, visited) visited_nodes = set() dfs(graph, 1, visited_nodes) # Output: {1, 2, 3, 4, 5} |
Breadth-First Search (BFS): BFS explores all neighbour nodes at a particular depth before moving on to nodes at the next depth level.. It can be implemented using a queue.
|
from collections import deque def bfs(graph, start): visited = set() queue = deque([start]) while queue: node = queue.popleft() if node not in visited: visited.add(node) queue.extend(graph[node])
bfs(graph, 1) # Output: {1, 2, 3, 4, 5} |
Graphs are widely used in real-life scenarios, such as:
1) Social Networks: Representing friends and connections between users.
2) Computer Networks: Modeling communication paths between devices.
3) Transportation Systems: Mapping routes and connections between cities.
Heaps: Priority Queues in Python
Heaps are specialised trees used to maintain a collection of elements, with each element having a priority associated with it. They are often used to implement priority queues, wherein the element with the highest (or lowest) priority is served first.
Min Heaps vs Max Heaps
Heaps can be either min heaps or max heaps. In a min heap, the parent node's value is less than or equal to its child nodes, making the minimum element the root. In a max heap, the parent node's value is greater than or equal to its child nodes, making the maximum element the root.
|
import heapq min_heap = [3, 5, 7, 9, 4, 6] heapq.heapify(min_heap) # Convert list to a min heap max_heap = [-3, -5, -7, -9, -4, -6] heapq.heapify(max_heap) # Convert list to a max heap |
Heapsort is a sorting algorithm that uses a heap Data Structure to sort elements in ascending or descending order. Heapsort has a time complexity of O(n log n) and is particularly useful when a stable sort is not required.
Heaps are essential in various applications, including:
1) Job scheduling: Prioritising tasks based on their urgency or importance.
2) Dijkstra's algorithm: Finding the shortest path in a graph.
Python's heapq module provides functions for creating and manipulating heap Data Structures efficiently:
|
import heapq heap = [] heapq.heappush(heap, 3) heapq.heappush(heap, 1) heapq.heappush(heap, 4) heapq.heappop(heap) # Output: 1 |
HashMaps: Efficient Key Value Storage
HashMaps are a Data Structure that stores key-value pairs and provides fast access to values based on their keys. In Python, the built-in dict type is a HashMap implementation. It allows efficient insertion, retrieval, and deletion of elements.
Creating a HashMap:
|
# Using dict to create a HashMap my_dict = {'apple': 1, 'banana': 2, 'orange': 3} |
Accessing Values:
|
# Accessing values using keys print(my_dict['banana']) # Output: 2 |
Inserting and Deleting:
|
# Inserting a new key-value pair my_dict['grape'] = 4 # Deleting a key-value pair del my_dict['apple'] |
Queue: First-in, First-Out Data Management
A Queue is a linear Data Structure in accordance with the First-In-First-Out (FIFO) principle. Elements are inserted at the rear and removed from the front. It models real-life scenarios like waiting in line. In Python, the deque class from the collections module provides a Queue implementation.
Creating a Queue
from collections import deque
|
# Creating a Queue using deque queue = deque() |
Enqueue and Dequeue
|
# Enqueue elements queue.append(1) queue.append(2) queue.append(3) # Dequeue elements print(queue.popleft()) # Output: 1 print(queue.popleft()) # Output: 2 |
Stacks: Last-in, First-Out Data Structures
Stacks are linear Data Structures following the Last In, First Out (LIFO) principle. Elements are added and removed from the same end, called the top. Python's built-in list type can act as a stack.
Creating a Stack
|
# Using list to create a stack stack = [] |
Push and Pop Operations
|
# Push elements onto the stack stack.append(10) stack.append(20) stack.append(30) # Pop elements from the stack print(stack.pop()) # Output: 30 print(stack.pop()) # Output: 20 |
Stacks are widely used in programming for tasks like function call tracking, expression evaluation, and undo/redo functionality.
Sets and Multisets
In this section, you'll learn how to implement mutable and immutable set and multiset (bag) Data Structures in Python using built-in data types and standard library classes.
Understanding Sets in Python
A set is an unordered collection of unique objects. Sets are typically used for:
a) Quickly test if a value is in the set.
b) Inserting or deleting values.
c) Computing the union or intersection of sets.
In Python, sets have O(1) time complexity for membership tests and O(n) time complexity for union, intersection, difference, and subset operations. The standard library’s set implementations follow these performance characteristics.
Creating Sets
Python provides syntactic sugar for creating sets using curly braces or set comprehensions:
|
vowels = {"a", "e", "i", "o", "u"} squares = {x * x for x in range(10)} |
To create an empty set, use the set() constructor. Using {} will create an empty dictionary instead:
|
empty_set = set() |
Mutable Sets: The set Type
The set type is Python’s built-in mutable set implementation, allowing dynamic insertion and deletion of elements. Sets in Python are backed by the dict data type and share its performance characteristics. Any hashable object can be stored in a set:
|
>>> vowels = {"a", "e", "i", "o", "u"} >>> "e" in vowels True >>> letters = set("alice") >>> letters.intersection(vowels) {'a', 'e', 'i'} >>> vowels.add("x") >>> vowels {'i', 'a', 'u', 'o', 'x', 'e'} >>> len(vowels) |
Immutable Sets: The frozenset Type
The frozenset class implements an immutable version of a set. Once constructed, it cannot be changed. This immutability allows frozenset objects to be used as dictionary keys or elements of another set:
|
>>> vowels = frozenset({"a", "e", "i", "o", "u"}) >>> vowels.add("p") Traceback (most recent call last): File " AttributeError: 'frozenset' object has no attribute 'add' >>> # Frozensets are hashable and can be used as dictionary keys: >>> d = {frozenset({1, 2, 3}): "hello"} >>> d[frozenset({1, 2, 3})] |
Multisets: The collections.Counter Class
The collections.Counter class implements a multiset (or bag) that allows elements to have multiple occurrences. This is useful for tracking not just membership but also the count of each element:
|
>>> from collections import Counter >>> inventory = Counter() >>> loot = {"sword": 1, "bread": 3} >>> inventory.update(loot) >>> inventory Counter({'bread': 3, 'sword': 1}) >>> more_loot = {"sword": 1, "apple": 1} >>> inventory.update(more_loot) >>> inventory Counter({'bread': 3, 'sword': 2, 'apple': 1}) |
One caveat with Counter is the distinction between the number of unique elements and the total count of elements. len() returns the number of unique elements, while sum() returns the total count:
|
>>> from collections import Counter >>> inventory = Counter() >>> loot = {"sword": 1, "bread": 3} >>> inventory.update(loot) >>> inventory Counter({'bread': 3, 'sword': 1}) >>> more_loot = {"sword": 1, "apple": 1} >>> inventory.update(more_loot) >>> inventory Counter({'bread': 3, 'sword': 2, 'apple': 1}) >>> len(inventory) # Unique elements 3 >>> sum(inventory.values()) # Total number of elements |
By understanding and utilising these different types of sets and multisets, you can effectively manage collections of unique or repeated elements in Python.
Python Data Structures and Algorithms
Algorithms play an important role in Python Data Structures, which enables efficient data manipulation and retrieval. An algorithm is a set of instructions or step-by-step procedures designed to solve particular problems or perform tasks. When paired with appropriate Data Structures, algorithms optimise performance and enhance code efficiency.
Python offers a rich collection of built-in algorithms for various Data Structures. For instance, the sort() method uses the Timsort algorithm for sorting lists, and the search() method employs binary search in ordered data. These algorithms ensure that common operations on Data Structures are fast and reliable.
Additionally, developers can create their own custom algorithms to work with user-defined Data Structures. For example, when implementing a linked list, a custom algorithm can efficiently traverse the list to locate or modify elements. Similarly, when working with graphs, graph traversal algorithms like Depth-First Search (DFS) or Breadth-First Search (BFS) can help navigate through the nodes effectively.
Efficient algorithms are essential in handling large datasets and complex computational problems. As the volume of data increases, algorithms that scale well become crucial for maintaining acceptable performance levels. Python's versatility and extensibility enable developers to experiment with various algorithms and Data Structures to find the best solutions for their specific needs.
Furthermore, considering the time complexity and space complexity of algorithms becomes important when dealing with significant datasets. Asymptotic notations, such as Big O notation, help measure the growth rate of an algorithm's resource consumption. This aids in selecting the most efficient solution.
By combining the right Data Structures with appropriate algorithms, Python empowers developers to tackle complex problems with elegance and effectiveness. This makes it a popular choice for various programming applications.
Level up your programming skills with our comprehensive Programming Training today!
Python Data Structures: Advantages and Disadvantages
Each Data Structure offers unique capabilities for tasks like sorting, inserting, and finding data, with efficiency varying based on the situation. No single Data Structure is inherently superior, but using the wrong one for a specific task can lead to inefficiency or skewed data.
Advantages of Python Data Structures
1) Efficiency: Data Structures like linked lists and binary search trees provide efficient insertion and deletion operations.
2) Memory Usage: Tuples use less memory compared to lists, making them more efficient for storing large amounts of data.
3) Quick Retrieval: Dictionaries allow for fast retrieval of values using keys, which is beneficial for handling unstructured data.
4) Existence Checking: Sets are excellent for checking the existence of a value and ensuring no duplicates are present.
5) Order Maintenance: Binary search trees maintain a sorted order of elements, facilitating quick access, sorting, and deletion.
Disadvantages of Python Data Structures
1) Sequential Access: Linked lists only provide sequential access, making searching and sorting operations challenging.
2) Immutability: Tuples do not support sorting, adding, replacing, or deleting elements, limiting their flexibility.
3) Limited Functionality: Sets have restricted functionality compared to other Data Structures.
4) Handling Large Data: Dictionaries are not suitable for handling large amounts of tabular data due to their structure.
5) Shifting Items: Arrays can be cumbersome for searching, sorting, inserting, and deleting since these operations often require shifting items.
Baster the pillar of GUI programming with Java Swing Development Training - sign up soon!
Conclusion
Python Data Structures form the backbone of efficient and organised programming. From versatile lists and immutable tuples to efficient dictionaries and powerful sets, each Data Structure serves a specific purpose in Python development. Understanding the principles, operations, and applications of Data Structures enables developers to write elegant, maintainable, and high-performance code.
Frequently Asked Questions
Why are Data Structures Important in a Python Programming Career?

Understanding Data Structures is important in a Python programming career as they determine the efficiency of data manipulation and storage. Mastery of Data Structures allows developers to write optimised, scalable code essential for tackling complex problems and improving application performance.
What are the Different Types of Advanced Data Structures Used in Computer Science?
In Computer Science, advanced Data Structures include trees, graphs, heaps, tries, and hash tables. Each serves unique purposes, such as optimising search algorithms, managing hierarchical data, and ensuring efficient memory usage. Mastery of these structures is key to solving intricate computational problems.
What are the Other Resources and Offers Provided by the Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 17 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are related Programming & DevOps Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Programming Training, including the Python Course, PHP Course, and R programming Course. These courses cater to different skill levels, providing comprehensive insights into Python Scripts.
Our Programming & DevOps Blogs cover a range of topics related to Java, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your Programming Skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Programming & DevOps Resources Batches & Dates
Date
 Python Course
Python Course
Python Course
Mon 20th Jan 2025
Python Course
Mon 24th Mar 2025
Python Course
Mon 26th May 2025
Python Course
Mon 28th Jul 2025
Python Course
Mon 22nd Sep 2025
Python Course
Mon 17th Nov 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


