



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +40 316317743 and speak to our training experts, we may still be able to help with your training requirements.
What is PySpark? A Beginner's Guide
Sophia Ellis 26 November 2024Curious to learn about PySpark? PySpark is a big data analysis and processing tool that enables users to handle enormous amounts of data sets through parallel computing applications. In this blog, we will understand What is PySpark, its essential features and applications, top practices, and why you should choose it.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

Is managing big data slowing down your analysis? Meet PySpark, a revolutionary data processing tool that lets you handle massive amounts of data seamlessly through its interactive Python interface. It is among the most vital tools for data scientists, helping to make their work easier and seamless.
Continue reading this comprehensive blog to uncover What is PySpark, its key features, reasons to choose, practices, widespread applications, etc. Let's dive straight into the topic!
Table of Contents
1) What is PySpark?
2) Why do we Need PySpark?
3) Key Features of PySpark
4) Who Utilises PySpark?
5) Best Practices for Optimising and Managing PySpark Applications
6) Example of a Basic Data Analysis Project in PySpark
7) Comparing Scala and PySpark
8) Conclusion
What is PySpark?
PySpark is a powerful open-source Python library that allows you to perform seamless processing and analyse of big data using Apache Spark applications. It also enables you to work efficiently with large datasets through Python, making it ideal for machine learning and data analysis tasks.
To understand it better, let’s take an example. Suppose you need to find the number of particular words in the library with millions of books. If you perform it manually, it will take ages. However, through PySpark, you can easily write Python codes to analyse all the books by breaking their tasks into smaller parts. It then aggregates those solutions into a single system to come to the conclusion.

Why do we Need PySpark?
Apache PySpark is primarily needed to address the key challenges associated with big data applications. The key reasons behind its selection are:
1) Handles Big Data Efficiently: Traditional tools struggle with large datasets, to which PySpark processes them smoothly in a distributed computing environment.
2) Speed and Performance: In-memory processing makes PySpark faster than disk-based frameworks like Hadoop MapReduce, which is crucial for real-time data analysis.
3) Versatility: PySpark supports structured as well as unstructured data from various sources, making it highly versatile.
4) Advanced Analytics: It is supported by built-in libraries for machine learning (ML) and graph processing to enable comprehensive data analysis and modelling.
5) Python Compatibility: Python compatibility ensures an easy transition for Python users, helping to broaden the user base and empowering collaboration.
6) All-in-One Solution: PySpark reduces complexity by combining multiple tools and technologies into one framework.
Dive into Python data analytics with Python Data Science Course- sign up today!
Key Features of PySpark
PySpark is designed to optimise performance, flexibility, and intuitiveness for big data applications. Some of its key features are:
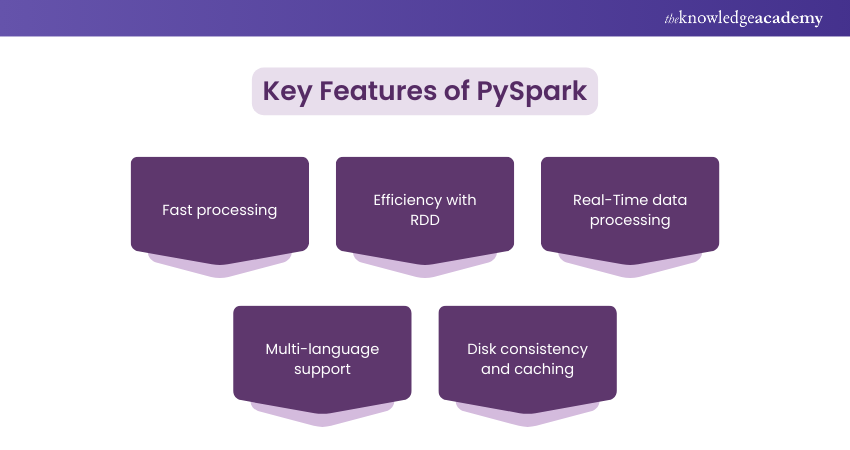
1) Fast Processing
One of the main features of Apache PySpark is its rapid processing speed. By utilising in-memory computing, PySpark can handle and analyse large sets of data far more quickly in comparison to traditional methods that relies on reading and writing data from disk. This speed enables businesses to data-driven decisions in real-time.
2) Efficiency with RDD
Another essential feature of PySpark is its Resilient Distributed Datasets (RDDs). RDDs are simple data structures that enable seamless distributed storage and processing. This means that the data is divided into smaller pieces and processed across multiple machines, further enhancing efficiency.
3) Real-time Data Processing
Another significant feature of PySpark is its ability to process data in real time. This means that as new information becomes available, PySpark can analyse it right away. This feature is useful especially for applications, including fraud detection or live analytics, where businesses need to respond to data immediately rather than waiting for the entire available data.
4) Multi-language Support
PySpark is compatible with different programming languages, including Python, Java, and Scala. This flexibility provides users to work in their preferred language, making it easier for data professionals to collaborate and share their insights.
5) Disk Consistency and Caching
PySpark offers disk consistency and caching features. Caching permits frequently used data to be stored in memory for faster access, speeding up processing times for repetitive tasks. Furthermore, this disk consistency ensures that data remains stable and reliable—a crucial facet for accurate analysis.
Who Utilises PySpark?
Apache PySpark is utilised by many professionals across different fields to make their work easier and more effective. Here are some of its key users:
1) Data Scientists
Data scientists use PySpark to analyse large datasets to derive meaningful insights. They can easily perform data cleaning, exploration, and visualisation quickly using its key applications.
2) AI Developers
AI developers utilise PySpark to build machine learning (ML) models. Since, PySpark can handle massive amounts of data, developers can process these datasets to train their models. This makes it easier for them to create AI applications capable of learning from data and making data-driven predictions and decisions.
3) Machine Learning Engineers
Machine learning engineers often work with big data to create algorithms that improve over time. PySpark helps them manage and process this data, making it possible to train and evaluate models more efficiently.
4) Big Data Engineers
Big data engineers are responsible for designing and managing big data solutions. They use PySpark to create data pipelines capable of processing and analysing large datasets and analysing distributed systems.
Advance your path toward data science- sign up for our Advanced Data Science Certification now!
Best Practices for Managing PySpark Applications
To make the most out of your Apache PySpark applications, it’s important for you to follow some best practices. These tips can help you optimise performance, manage resources, and ensure your applications run smoothly.

1) Use Efficient Data Formats: Choosing the right data format is crucial for performance. Formats like Parquet or ORC are optimised for big data and work well with PySpark. They allow for faster reads and writes and utilise less disk space compared to traditional formats like CSV.
2) Optimise Resource Usage: When running PySpark applications, managing resources effectively is key. You need to make sure to allocate the right amount of memory and CPU for your tasks. Monitoring your application’s resource usage helps identify bottlenecks or areas where you can optimise performance.
3) Cache Intermediate Data: If your application processes large datasets multiple times, consider caching intermediate results. Caching stores data in memory, allowing for faster access in future operations. This can significantly accelerate your application, particularly when performing repeated computations on the same dataset.
4) Write Efficient Transformations: When writing transformations in PySpark, try to minimise the number of actions and transformations performed. Instead of chaining too many transformations, try to group operations to reduce overhead.
5) Monitor and Debug Your Applications: Finally, focus on your PySpark applications by using monitoring tools. These tools help you track performance metrics and identify any issues that arise during execution. Debugging your applications allows you to spot errors and optimise performance, ensuring that your PySpark solutions run effectively and efficiently.
Example of a Basic Data Analysis Project in PySpark
Step 1: Setting Up PySpark
In order to start using the Apache PySpark app, you must have installed it on your computer. If not, you can use the following command to install it via pip:
|
```bash pip install pyspark ``` |
Step 2: Importing Libraries
Start by importing the necessary libraries for your analysis:
|
```python from pyspark.sql import SparkSession ``` |
Step 3: Creating a Spark Session
Next, create a Spark session, which serves as the entry point for utilising PySpark:
|
```python spark = SparkSession.builder .appName("Basic Data Analysis") .getOrCreate() ``` |
Step 4: Loading the Dataset
For this example, let’s assume you have a CSV file named `sales_data.csv` that contains sales records with the following columns: `Date`, `Product`, `Amount`, and `Quantity`. You can load this dataset using:
|
```python # Load the dataset data = spark.read.csv("sales_data.csv", header=True, inferSchema=True) ``` |
Step 5: Exploring the Data
Conduct basic exploration to understand the dataset better:
|
```python # Show the first few rows of the dataset data.show() # Print the schema of the dataset data.printSchema() ``` |
Step 6: Data Analysis
Now, let’s perform a basic analysis by calculating the total sales amount by-product:
|
```python # Calculate total sales amount by product total_sales = data.groupBy("Product").sum("Amount").withColumnRenamed("sum(Amount)", "Total_Sales") total_sales.show() ``` |
Step 7: Optimising the DataFrame
To enhance performance, consider caching the DataFrame if you plan to reuse it multiple times:
|
```python # Cache the DataFrame for performance improvement data.cache() ``` |
Step 8: Writing the Results
Finally, you may want to save the results to a new CSV file for further analysis or reporting:
|
```python # Save the total sales results to a CSV file total_sales.write.csv("total_sales_by_product.csv", header=True) `` |
Discover new insights through predictive modeling – join our award-winning Predictive Analytics Course today!
Comparing Scala and PySpark
A brief comparison between Scala and PySpark is described below:
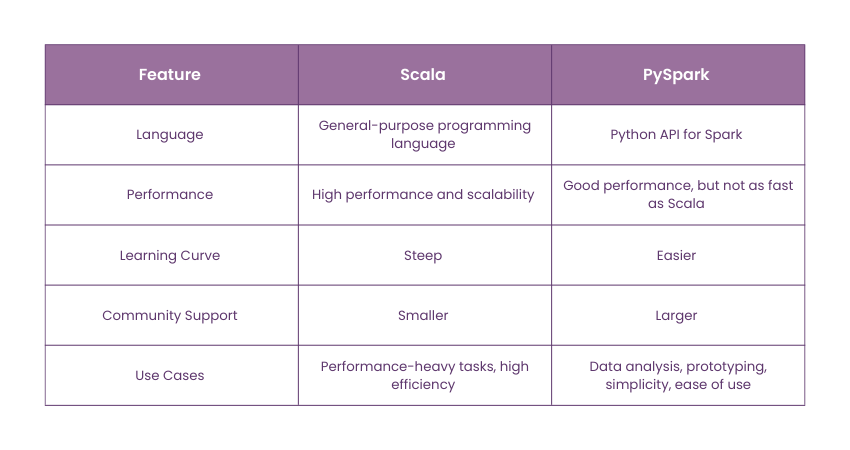
1) Language
Scala: Scala is a general-purpose programming language that works seamlessly with Apache Spark (as Spark is written in Scala). The tool is known for its speed and efficiency due to being compiled and running on the Java Virtual Machine (JVM).
PySpark: The Python API for Spark allows users to write Spark applications using Python. It is easier to learn and use, especially for Python Developer.
2) Performance
Scala: Scale offers high performance and scalability, making it ideal for applications that require fast and efficient processing.
PySpark: While not as fast as Scala, it is decently productive and utilises Python’s vast ecosystem, making it suitable for data analysis and prototyping.
3) Learning Curve
Scala: Scala has a steep learning curve, particularly for beginners who aren’t familiar with functional programming.
PySpark: In contrast, PySpark is easier to learn owing to Python’s simple syntax and wide range of libraries.
4) Community Support and Documentation
Scala: Smaller user base compared to PySpark, but still has a dedicated community and resources.
PySpark: Larger user base with more resources for troubleshooting and learning, providing extensive community support.
5) Use Cases
Scala: Suited for performance-heavy tasks and applications that need high efficiency and scalability.
PySpark: Apache PySpark is preferred for simplicity, ease of use, quick prototyping, and the ability to use Python alongside Spark.
Conclusion
We hope you understand What is PySpark. PySpark stands as the powerful tool for processing complex big data, offering Python users the speed, flexibility, and user-friendliness they require. So, whether you are a data scientist or a big data engineer, PySpark is an ideal framework tool that can simplify your complex tasks, helping you get insights faster and more effectively.
Transform complex data into actionable insights with our Data Mining Training- Book your seats now!
Frequently Asked Questions
Why Use PySpark Instead of Python?

Using PySpark instead of regular Python allows you to process massive datasets much faster by distributing tasks across multiple machines. Furthermore, it’s ideal for big data projects where Python alone would struggle with performance and scalability.
Why Is PySpark Better Than SQL?
PySpark is better than SQL for big data because of its ability to handle complex data processing and scalable transformations. While SQL is great for structured queries, PySpark offers more flexibility with unstructured data and supports advanced analytics and machine learning (ML) tasks.
What are the Other Resources and Offers Provided by The Knowledge Academy?
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs, videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA.
What is The Knowledge Pass, and How Does it Work?
The Knowledge Academy’s Knowledge Pass, a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
What are the Related Courses and Blogs Provided by The Knowledge Academy?
The Knowledge Academy offers various Data Science Courses, including PySpark Training, Advanced Data Science Certification, and Predictive Analytics Course. These courses cater to different skill levels, providing comprehensive insights into Regression Analysis.
Our Data, Analytics & AI Blogs cover a range of topics related to data science, machine learning, and artificial intelligence, offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your data analysis and AI skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 PySpark Training
PySpark Training
PySpark Training
Fri 17th Jan 2025
PySpark Training
Fri 21st Mar 2025
PySpark Training
Fri 16th May 2025
PySpark Training
Fri 18th Jul 2025
PySpark Training
Fri 19th Sep 2025
PySpark Training
Fri 21st Nov 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


