



 Top Rated Course
Top Rated Course

We may not have the course you’re looking for. If you enquire or give us a call on +44 1344 203 999 and speak to our training experts, we may still be able to help with your training requirements.
Deep Learning Cheatsheet: A Quick Guide
Sienna Roberts 22 September 2023Explore the ultimate Deep Learning Cheatsheet – your comprehensive blog to mastering the intricate field of artificial intelligence. From neural networks to backpropagation, this cheat sheet simplifies complex concepts and algorithms, making it an invaluable resource for both beginners and experienced AI enthusiasts.

Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Table of Contents

The various intricacies, like complex algorithms and models, call for a clear understanding and a strategic approach to Deep Learning. Therefore, keeping a Deep Learning Cheatsheet can prove handy for anyone who wants to dive deeper into the domain of Machine Learning. In this blog, we have covered the Deep Learning Cheatsheet and filled it with valuable, concise information to enhance your understanding.
Table of Contents
1) A brief introduction to Deep Learning
2) Understand Deep Learning with a Cheatsheet
a) Data processing
b) Training Neural Networks
c) Finding the optimal weight
d) Tuning parameters
e) Optimising of convergence
f) Regularisation
3) Best practices
4) Conclusion
A brief introduction to Deep Learning
Deep Learning utilises Artificial Neural Networks (ANNs) to enable machines to learn, interpret, and make decisions from complex data. These networks are made of layers of nodes or "neurons", connected in a manner that allows them to process information in a non-linear way.
The domain excels in recognising patterns and relationships within vast amounts of unstructured data. Thus, it becomes crucial in fields like image recognition, Natural Language Processing (NLP), and autonomous vehicles.
Unlike traditional algorithms, such models can automatically learn features from raw data, continually improving accuracy, its transformative potential is undeniable, though challenges like data and computational demands remain.
Learn the basics of linear algebra and algorithms by signing up for our Deep Learning Training now!
Understand Deep Learning with a Cheatsheet
You can get a quick overview of the various concepts in Deep Learning, by skimming through this Deep Learning Cheatsheet, as shown below:
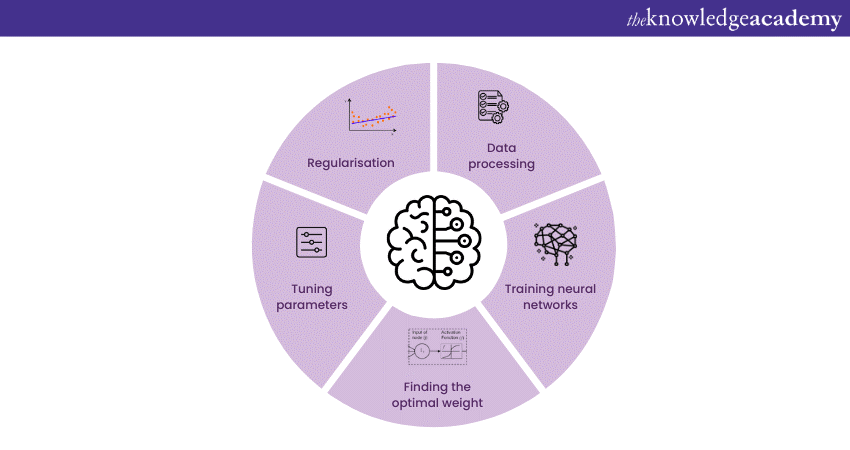
Data processing
Data processing involves the conversion and organisation of raw data into a structured form, making it suitable for training Neural Networks. These steps include preprocessing steps like cleaning, normalising, and transforming data to remove inconsistencies or noise.
Additionally, feature extraction might be applied to highlight essential characteristics relevant to the learning task. Data is then divided into batches, typically segregated into training, validation, and testing sets. These procedures ensure that the Neural Network can efficiently learn the underlying patterns without biases. As a result, the quality of data processing directly impacts the effectiveness of a Deep Learning model. This, in turn, influences its ability to generalise and predict accurately.
Training Neural Networks
A Neural Network can be trained with the following steps:
a) Data preparation: Gathering and preprocessing data, including normalisation and splitting it into training, validation, and test sets.
b) Model architecture: Designing the structure of the Neural Network, selecting layers, neurons, and activation functions.
c) Forward propagation: Passing the input data through the network to generate predictions.
d) Loss calculation: Computing the difference between predictions and actual values using a loss function.
e) Backpropagation: Adjusting the network's weights using algorithms like Gradient Descent, minimising the loss.
f) Iteration: Repeating the process across multiple epochs, tuning the model.
g) Evaluation: Assessing the trained model on unseen data, ensuring it generalises well.
h) Optimisation: Applying techniques to prevent overfitting and enhance efficiency.
Acquire the knowledge of translating real data into patterns by signing up for our Neural Networks with Deep Learning Training now!
Finding the optimal weight
A Neural Network’s weights can be calculated using the following steps:
a) Initialise weights: Start with random or predefined weights for each connection in the Neural Network.
b) Forward propagation: Pass input data through the network, applying weights and activation functions to compute predictions.
c) Calculate loss: Determine the loss or error between the predicted outputs and the actual targets using a loss function.
d) Backpropagation: Compute the gradients of the loss function with respect to each weight by applying the chain rule.
e) Update weights: Adjust the weights in the direction that minimises the loss, using an optimisation algorithm like Gradient Descent.
f) Iterate: Repeat the process across multiple epochs or iterations until the loss converges to a minimum.
g) Evaluate: Test the model with the optimised weights on validation data to ensure that it generalises well.
Tuning parameters
A Neural Network model’s parameter can be tuned with the following steps:
a) Initialising weights: Choosing appropriate initial values for the weights and avoiding values that are too large or small to prevent vanishing or exploding gradients.
b) Convergence optimisation: Selecting suitable optimisation techniques, such as Adam or RMSProp, to ensure efficient convergence to the optimal solution.
c) Learning rate selection: Tuning the learning rate, balancing between fast convergence and stability.
d) Regularisation techniques: Applying methods like dropout or L1/L2 regularisation to prevent overfitting.
e) Batch size and Epochs: Adjusting the size of data batches and the number of training iterations for optimal training dynamics.
f) Validation strategy: Using validation sets to continuously evaluate and tune the model.
g) Grid or random search: Employing systematic search methods to explore various hyperparameter combinations and identify the best set.
Regularisation
Here are the steps to successfully regularise Neural Network models:
a) Definition: Regularisation in Deep Learning prevents overfitting by adding penalties to the loss function.
b) Methods: Includes L1 (lasso) and L2 (ridge) regularisation, applying linear penalties to the weights.
c) Dropout: A technique where randomly selected neurons are ignored during training, enhancing generalisation.
d) Implementation: Added to the loss function, influencing the weight update during backpropagation.
e) Effect: Helps the model to perform better on unseen data, striking a balance between bias and variance.

Best practices
It is recommended for developers to follow some key practices when working with Neural Network models in Deep Learning. These practices are described as follows:
a) Overfitting small batches: Initially, overfitting a small batch of data helps in ensuring that the model can capture relationships in data. It's a valuable diagnostic step before scaling up.
b) Checking gradients: Regular monitoring of gradients during training ensures that they don't vanish or explode, affecting the learning process.
c) Data normalisation: Processing data to a uniform scale enhances training efficiency.
d) Early stopping: Terminating training when validation performance plateaus prevent overfitting.
e) Hyperparameter tuning: Systematic selection of model parameters optimises performance.
f) Model evaluation: Regular assessment of validation data ensures that the model generalises well to unseen information.
Conclusion
We hope that this Deep Learning Cheatsheet served as a quick skim-through for learners and Machine Learning Engineers. We hope the insights provided can help you explore the intricacies and their profound impact on modern technology. A fundamental understanding of these aspects is vital for anyone working in the field.
Learn how to solve problems in computational finance and NLP by signing up for our Machine Learning Training now!
Frequently Asked Questions
Upcoming Data, Analytics & AI Resources Batches & Dates
Date
 Deep Learning Course
Deep Learning Course
Deep Learning Course
Fri 17th Jan 2025
Deep Learning Course
Fri 7th Mar 2025
Deep Learning Course
Fri 23rd May 2025
Deep Learning Course
Fri 18th Jul 2025
Deep Learning Course
Fri 12th Sep 2025
Deep Learning Course
Fri 12th Dec 2025
 If you wish to make any changes to your course, please
If you wish to make any changes to your course, please


